









更多、更及时内容欢迎 微信公众号围观: 小窗幽记机器学习
基本信息
论文标题:
Unified Named Entity Recognition as Word-Word Relation Classification
论文地址:
https://arxiv.org/abs/2112.10070
论文代码:
https://github.com/ljynlp/W2NER
简介
NER 任务主要有三种类型:Flat(扁平)、overlapped(重叠或嵌套)、discontinuous(非连续),越来越多的研究致力于将它们统一起来。此前的 SOTA方案主要基于 Span 和 Seq2Seq 模型, 不过这类方法很少关注边界,可能会导致后续的偏移。2022 AAAI的论文《Unified Named Entity Recognition as Word-Word Relation Classification》介绍了一个统一NER的SOTA模型W2NER,该模型在14个包含扁平实体、重叠实体和非连续实体的数据集(8个英文 + 6个中文)上,均取得了SOTA的结果(F1指标)。W2NER将NER问题视为词词关系分类,为此引入两种词词关系:NNW(Next-Neighboring-Word)和 THW-*(Tail-Head-Word-*)。具体而言,构造一个 2D 的词词关系网格,然后使用多粒度 2D 卷积以更细致地抽取网格表示。最后,使用一个 共同预测器(co-predictor) 来推理词-词关系。
多类型NER抽取方法
多类型NER抽取方法大致可以分为4种:
- 序列标注方法
- 基于超图
- 基于sequence-to-sequence的生成方法
- 基于span的方法,比如指针网络或token 对的形式
1). 基于序列标注
序列标注方法比较常用,给每一个 Token 一个标签(比如BIO标注标准中的一个标签)。输入序列会使用已有的表征框架(如 CNN、LSTM、Transformer等) 表征成序列特征,再过一层CRF以得到各个Token的标签结果。对于多类型NER,可以将**「多分类」改为「多标签分类」**或将多标签拼成一个标签。前者不容易学习,而且预测出来的 BI 可能都不是一个类型的;而后者则容易导致标签增加,且很稀疏。虽有不少研究,比如《A Neural Layered Model for Nested Named Entity Recognition》提到的动态堆叠平铺 NER 层来识别嵌套实体;《Recognizing Continuous and Discontinuous Adverse Drug Reaction Mentions from Social Media Using LSTM-CRF》的 BIOHD 标注范式(H 表示多个实体共享的部分,D 表示不连续实体中不被其他实体共享的部分),注意 H 和 D 都是实体的 Label,标注时会和 BI 结合使用,如 DB,DI,HB,HI。但总的来说较难设计一个不错的标注 Scheme。
序列标注方法可以很好解决扁平实体的问题,对于嵌套实体通过修改标注可以勉强解决,但是会增加模型复杂度;而面对不连续实体序列标注方法无法解决。所以在只存在扁平实体的情况下,可以选择序列标注的方法,这边推荐一下复旦邱锡鹏老师团队的tener方法,使用transofrmer改进结构的模型。
2). 基于超图
基于超图的方法首次在《Joint Mention Extraction and Classification with Mention Hypergraphs》中提出,用于解决重叠NER问题,后续也被用于不连续实体。这类方法在推理时容易被虚假结构和结构歧义问题影响。
3). 基于 Seq2Seq
seq2Seq用于NER首次出现于《Multilingual Language Processing From Bytes》,输入句子,输出所有实体的开始位置、Span 长度和标签。其他后续应用包括:
- 使用增强的 BILOU 范式解决重叠 NER 问题。
- 基于 BART 通过Seq2Seq+指针网络生成所有可能的实体开始-结束位置和类型序列。
但是这种方法存在解码效率低和Seq2Seq架构固有的暴露偏差(exposure bias)问题。所谓暴露偏差问题是指训练时使用上一时间步的真实值作为输入;而预测时,由于没有标签值,只能使用上一时间步的预测作为输入。由于模型都是把上一时间步正确的值作为输入,所以模型不具备对上一时间步的纠错能力。如果某一时间步出现误差,则这个误差会一直向后传播。
4). 基于Span
基于 Span 的方法将 NER 问题转为 Span 级别的分类问题,具体方法包括:
- 枚举所有可能的 Span,再判断他们是否是有效的 Mention。
- 使用 Biaffine Attention 来判断一个 Span 是 Mention 的概率。
- 将 NER 问题转为 MRC 任务,提取实体作为答案 Span。
- 两阶段方法:使用一个过滤器和回归器生成 Span 的建议,然后进行分类。
- 将不连续的 NER 转为从基于 Span 的实体片段图中找到完整的子图。
这类方法全枚举所有可能spans,因此受到最大span长度和模型复杂度的影响,尤其是对于长span实体。
总的来说,简单的NER 任务目前一般使用序列标注就可以解决,多类型NER效果较好的还是基于 Span 的方法。
NER->词词关系分类
现有大多数NER工作主要考虑更准确的实体边界识别,W2NER作者在仔细重新思考了三种不同类型NER的共同特征后,觉得统一 NER的瓶颈更多在于实体词之间相邻关系的建模。这种邻接相关性本质上描述了文本片段之间的语义连通性,尤其对于重叠和不连续的部分起着关键作用。如下图 a 所示:

因此,文章提出一种词-词关系分类架构——W2NER,通过对实体边界和实体词之间相邻关系进行建模。具体来说,预测两种类型的关系,如上图 b 所示。
-
NNW:这类关系可以解决实体词识别,指示两个 Token 在一个实体中是否相邻。比如aching-> in。 -
THW-*:这类关系主要用以检测实体边界和和实体类型,指示两个 Token 是尾部还是头部,*标签则对应实体的类型。比如legs->aching, Symptom,意味着尾部是legs,头部是aching,实体类型是Symptom。
那W2NER如何将NER问题转为词-词关系分类问题?以下为例:
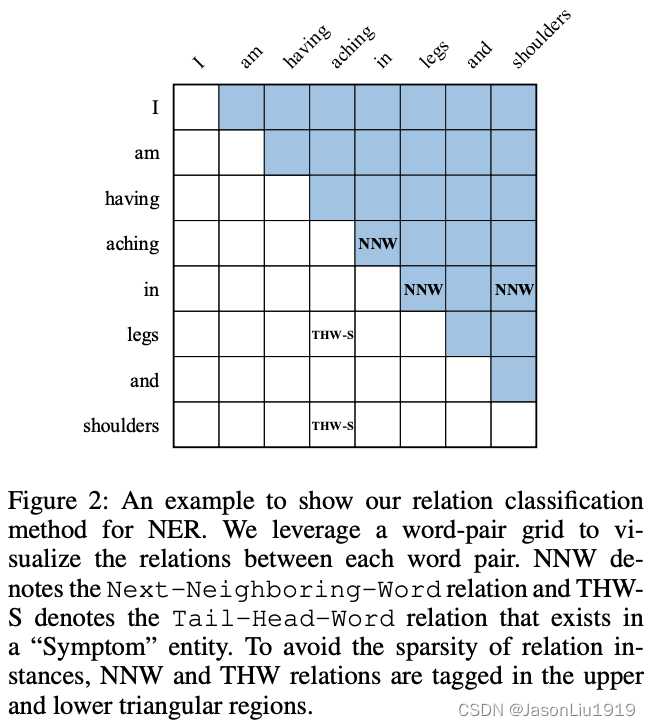
词之间的关系包括以下几种类型:
NONE:表示词对之间没有任何关系NNW:词对属于一个实体 Mention的一部分,网格中特定行的 token 在列中有一个连续的 tokenTHW-*:THW 关系表示网格中行 token 是一个实体 mention 的尾部,网格中列 token 是一个实体 mention 的头部,*表示实体类型。
Figure 1中的例子的网格化结果如Figure 2 所示。Figure 1 中的两个实体:aching in legs 和 aching in shoulders,可以通过Figure 2 中的 NNW 关系(aching→in)、(in→legs)和(in→shoulders)和 THW 关系(legs→aching,Symptom)和(shoulders→aching,Symptom)解码得出。
而且NNW和THW关系还暗示 NER 的其他影响,比如NNW关系将同一不连续的实体片段关联起来(如 aching in 和 shoulders),也有利于识别实体词(相邻的)和非实体词(不相邻的)。至于THW关系则有助于识别实体的边界。
W2NER模型框架
整体的网络架构如下图所示:
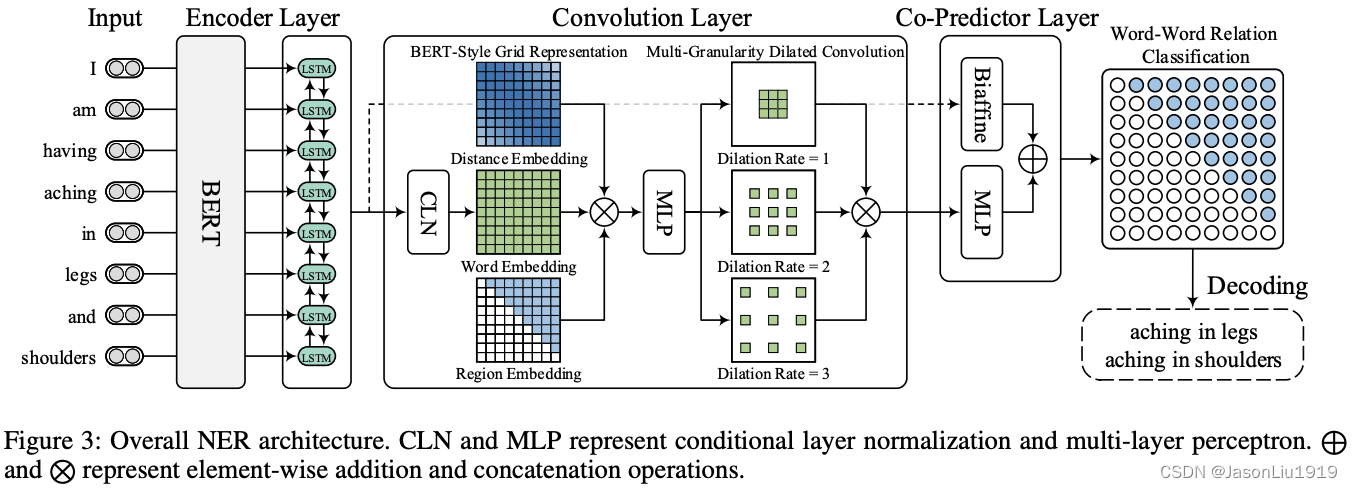
总的来说,W2NER由3部分组成。首先用 BERT 和 LSTM 抽取输入句子的上下文特征,然后过一个2D 卷积层对词-词关系进行建模和表征,以用于后续的词对关系分类。最后再过一个联合预测器(Co-Predictor)对词-词关系进行推理并产生所有可能的实体 Mention,其中 Biaffine 分类器和 MLP 被联合使用以获得更好的词对分类结果。
Encoder Layer:
- 输入 Bert ,得到 sub-word representation(因为英文使用 word piece的方式,每个token都会被分割成word piece)
- 使用 max pooling 得到 word representations
- 输入到 Bi-LSTM 得到最终 word representations
Convolution Layer:
Encoder层之后接的是卷积层以进一步对抽取的特征进行细化,因为 2D 卷积能很好地处理二维的网格关系,具体又包括三个模块:
- Conditional Layer Normalization(CLN),即带归一化的condition layer。使用CLN以生成词对表示。
- BERT 风格的网格表征以进一步丰富词对表示
- 多粒度膨胀卷积以捕获远近词之间的交互
CLN 部分:
V
i
j
=
CLN
(
h
i
,
h
j
)
=
γ
i
j
⊙
(
h
j
−
μ
σ
)
+
λ
i
j
γ
i
j
=
W
α
h
i
+
b
α
λ
i
j
=
W
β
h
i
+
b
β
μ
=
1
d
h
∑
k
=
1
d
h
h
j
k
,
σ
=
1
d
h
∑
k
=
1
d
h
(
h
j
k
−
μ
)
2
\mathbf{V}_{i j}=\operatorname{CLN}\left(\mathbf{h}_{i}, \mathbf{h}_{j}\right)=\gamma_{i j} \odot\left(\frac{\mathbf{h}_{j}-\mu}{\sigma}\right)+\lambda_{i j} \\ \gamma_{ij} = \mathbf{W}_{\alpha} h_i + \mathbf{b}_{\alpha} \\ \lambda_{ij} = \mathbf{W}_{\beta} h_i + \mathbf{b}_{\beta} \\ \mu=\frac{1}{d_{h}} \sum_{k=1}^{d_{h}} h_{j k}, \\ \quad \sigma=\sqrt{\frac{1}{d_{h}} \sum_{k=1}^{d_{h}}\left(h_{j k}-\mu\right)^{2}}
Vij=CLN(hi,hj)=γij⊙(σhj−μ)+λijγij=Wαhi+bαλij=Wβhi+bβμ=dh1k=1∑dhhjk,σ=dh1k=1∑dh(hjk−μ)2
其中
V
\mathbf{V}
V是单词对表征矩阵,
V
i
,
j
\mathbf{V}_{i,j}
Vi,j可以看作词
x
i
x_i
xi 和
x
j
x_j
xj 的词表征(
h
i
\mathbf{h}_i
hi 和
h
j
\mathbf{h}_j
hj)的组合。由于NNW和THW具有方向性,所以可以将
x
i
x_i
xi视为
x
j
x_j
xj的条件。
γ
i
j
\gamma_{ij}
γij和
λ
i
j
\lambda_{ij}
λij是超参数,而
h
i
\mathbf{h}_i
hi是这2个参数的条件。
μ
\mu
μ和
σ
\sigma
σ分别是均值和标准差,而
h
j
k
h_{jk}
hjk表示
h
j
\mathbf{h}_j
hj的第
k
k
k个维度。
BERT-Style的网格表示效仿BERT的3种表征,也对应引入3种张量表示:词信息(CLN)表征(对应BERT中的token embedding) 、词对的相对位置信息(对应BERT中的 position embedding)和用于区分网格上下三角的区域信息(对应BERT中的 segment embedding)。其中表示词信息的表征来自于前一个模块CLN的输出结果,即 V \mathbf{V} V。而词对之间相对位置关系 E d \mathbf{E}^d Ed和区域信息 E t \mathbf{E}^t Et。
再将3个张量拼接输入到MLP层进行降维和信息融合,以此得到网格表征,至此网格表征具有位置-区域敏感的特点。再接一个多粒度膨胀卷积(粒度=1,2,3),用以捕获不同距离词的交互信息。最后将三个膨胀卷积结果拼起来得到最终的词对网格表征 Q \mathbf{Q} Q。
Co-Predictor Layer:
这个步骤主要是利用MLP对上述卷积层得到的网格表征预测词对关系。由于之前的研究表明使用**双仿射预测器(Biaffine Predictor)**可以提升MLP预测器在关系分类上的性能,所以文章也使用2个Predictor进行词对的关系分类,然后合并后作为最后输出结果。
-
Biaffine Predictor
词对 ( x i , x y ) (x_i,x_y) (xi,xy)之间的Biaffine分类器关系得分计算如下:
s i = MLP 2 ( h i ) o j = MLP 3 ( h j ) y i j ′ = s i ⊤ U o j + W [ s i ; o j ] + b \begin{aligned} \mathbf{s}_{i} &=\operatorname{MLP}_{2}\left(\mathbf{h}_{i}\right) \\ \mathbf{o}_{j} &=\operatorname{MLP}_{3}\left(\mathbf{h}_{j}\right) \\ \mathbf{y}_{i j}^{\prime} &=\mathbf{s}_{i}^{\top} \mathbf{U o}_{j}+\mathbf{W}\left[\mathbf{s}_{i} ; \mathbf{o}_{j}\right]+\mathbf{b} \end{aligned} siojyij′=MLP2(hi)=MLP3(hj)=si⊤Uoj+W[si;oj]+b
其中 s i \mathbf{s}_i si和 o j \mathbf{o}_j oj 分别表示第 i i i和第 j j j个词的主语表征和宾语表征。注意:计算 s i \mathbf{s}_i si和 o j \mathbf{o}_j oj的输入就是前面的词表征,即是 h h h而不是卷积后的结果,卷积这部分特征被丢给了MLP Predictor。 -
MLP Predictor
对于卷积层得到的特征结果 Q \mathbf{Q} Q再使用一个MLP计算词对之间的关系得分:
y i j ′ ′ = MLP ( Q i j ) \mathbf{y}_{i j}^{\prime\prime}=\operatorname{MLP}(\mathbf{Q}_{ij}) yij′′=MLP(Qij)
词对关系最终的概率得分:
y
i
j
=
Softmax
(
y
i
j
′
+
y
i
j
′
′
)
\mathbf{y}_{i j}=\operatorname{Softmax}( \mathbf{y}_{i j}^{\prime} + \mathbf{y}_{i j}^{\prime\prime})
yij=Softmax(yij′+yij′′)
Decoding:
模型最终得到的结果是词和词之间的关系(既需要确定词的边界,也需要确定词之间的关系),可以看作有向图。Decoding的目标是使用 NNW 关系在图中查找从一个单词到另一个单词的某些路径。每条路径对应于一个实体 Mention。THW信息一方面有助于识别 NER的类型和边界,另一方面还可以用作消除歧义的辅助信息。

如Figure 4所示几个例子:
-
a:两条路径对应平铺的实体,THW 关系表示边界和类型。
-
b:如果没有 THW 关系,则只能找到一条路径(ABC),而借助 THW关系 可以找到嵌套的 BC。
-
c:包含两条路径:ABC 和 ABD,NNW 关系有助于连接不连续的span AB 和 D。
-
d:如果只使用 THW 关系,将会识别到 ABCD 和 BCDE,如果只使用 NNW 则会找到四条路径,结合起来才能识别到正确的实体:ACD 和 BCE。
Loss:
L
=
−
1
N
2
∑
i
=
1
N
∑
j
=
1
N
∑
r
=
1
∣
R
∣
y
^
i
j
r
log
y
i
j
r
\mathcal{L}=-\frac{1}{N^{2}} \sum_{i=1}^{N} \sum_{j=1}^{N} \sum_{r=1}^{|\mathcal{R}|} \hat{\mathbf{y}}_{i j}^{r} \log \mathbf{y}_{i j}^{r}
L=−N21i=1∑Nj=1∑Nr=1∑∣R∣y^ijrlogyijr
N N N 表示句子中词数, y ^ \hat{y} y^是二元向量表示词对的真实关系 Label, y y y 是预测的概率, r r r 表示预先定义的关系集合中的第 r 个关系。可以看出,整个就是个词对分类问题。
小结
文章基于词-词关系分类,提出一个统一的实体框架 W2NER,关系包括 NNW 和 THW。框架在面对各种不同的 NER 时非常有效。另外,通过消融实验,发现以卷积为中心的模型表现良好,其他几个模块(网格表示和共同预测器Co-Predictor)也是有效的。总的来说,文章更加关注边界词和内部词之间的关系,另外 2D 网格标记方法也可以大大避免 Span 和序列标注模型中的缺点。














 1881
1881











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









