







读取流程
cassandra的数据可能在Memtable中,也可能在多个SSTable中,每个地方都可能有某个column对应的值,怎么才能读取最新的值呢?有必要了解下cassandra读取数据流程:
(1)判断rowcache中是否有需要读取的数据,如果有直接返回;
(2)从Memtable中获取数据,调用getColumnFamily方法获取该列族的数据;
(3)从多个SSTable中获取相关列的数据:
a、先通过bloom filter文件判断该key是否存在于SSTable中,如果存在,进行第二步;
b、查询key_cache中是否有当前key,如果有直接定位到key所在SSTable中的位置;
c、 key_cache可不存在,通过index定位到具体位置。
下图是从SSTable中获取数据的过程
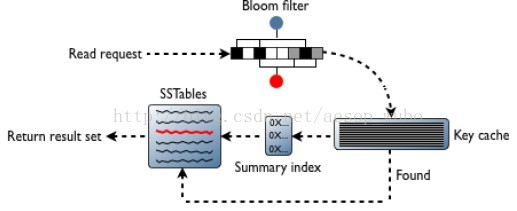
(4)将(2)(3)中的数据进行合并后返回给客户端。
下图是cassandra读取数据示意:

RowCache
RowCache中缓存了最近读取的列信息,常常将一些热点数据放入RowCache中,减少了操作磁盘的开销。Cassandra写入数据后会同步更新RowCache,保证RowCache中的数据是最新的。
KeyCache
二级索引
如果查询的key并不是一个row key怎么办,比如User列族以userId做为row key,每个row key中包含姓名、性别、身份证等,需要按身份证查询用户怎么办?
需要在身份证这个列上建一个二级索引,二级索引也相当于是一个列族,row key为身份证号码, 只有一个column名为userId。
先通过二级索引找到key对应的row key,再用row key定位到具体数据。
压缩机制
cassandra后台会有一个线程,将多个SSTable进行合并,保证同一个列族在一个SSTable文件中,同时会删除被标记为墓碑的值(超过gc_grace_seconds)。
压缩可以防止文件碎片,有效提升读取效率,减少磁盘I/O。
压缩是在后台进行的,对客户端透明,频繁地进行数据压缩会导致系统不稳定,因为压缩本身也会有大量的磁盘I/O,可以在配置文件中配置压缩的优先级,还可以考虑关闭自动压缩,在系统空闲时手动压缩。

















 212
212

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









