







今天我们来介绍一个比较实用的MCPserver-fetch网页内容抓取。通过这个MCP工具,我们可以实现一个非常有用的功能,就是通过抓取接口文档的内容,自动生成接口调用代码。
这里我们选用魔塔MCP市场提供的MCP服务。登录魔塔MCP市场,在MCP广场,我们搜索"fetch网页内容抓取",点击进入详情页,在右侧"通过SSE URL服务连接",点击连接,则会产生一个MCPserver的配置信息,
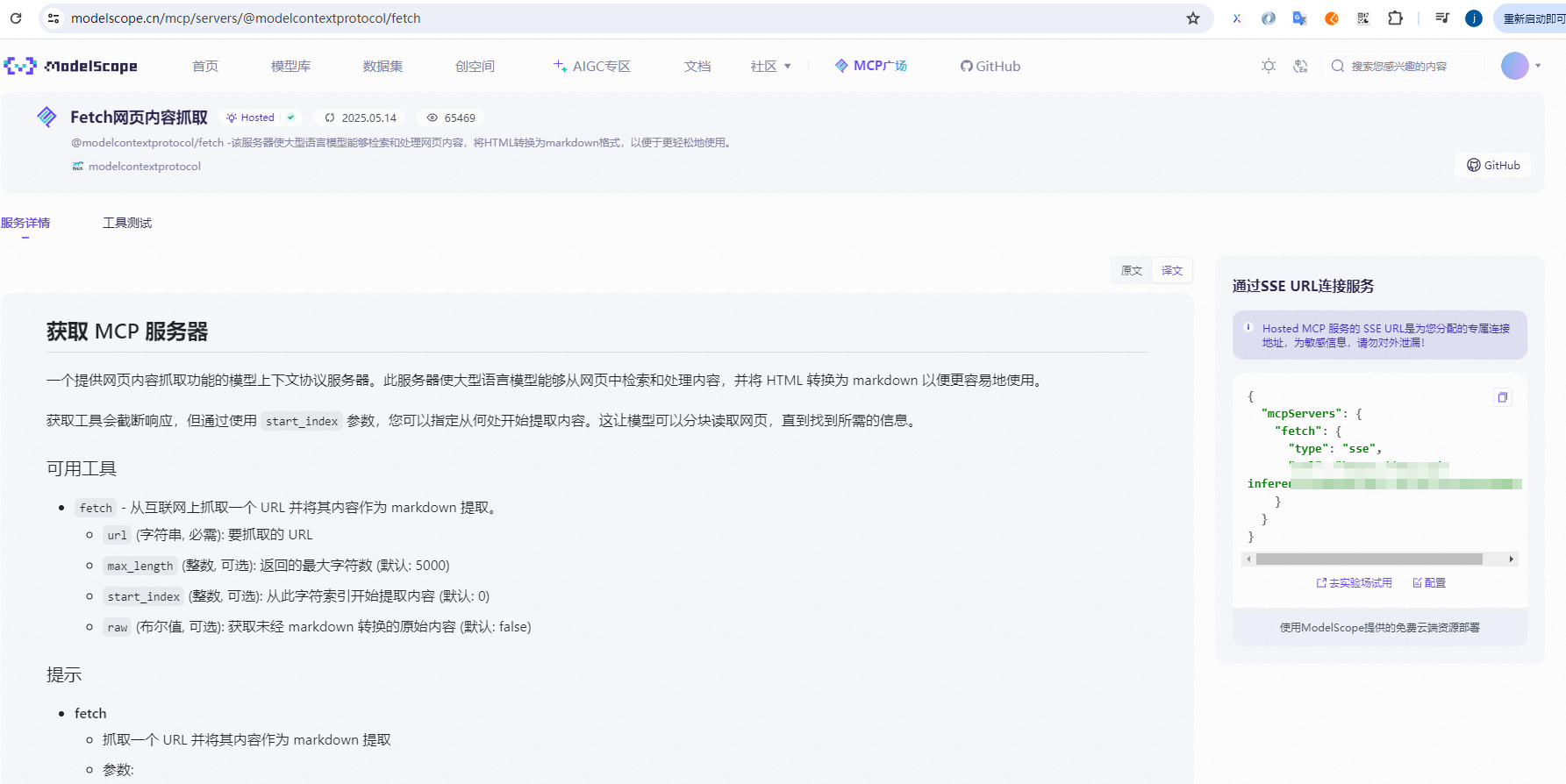
我们拷贝配置信息,在cursor中添加mcp mcpserver(具体mcpserver如何添加,可以参考我之前写的配置figma mcpserver的文章)。同样,我们看到mcp server有绿色的小点,表示配置成功了。
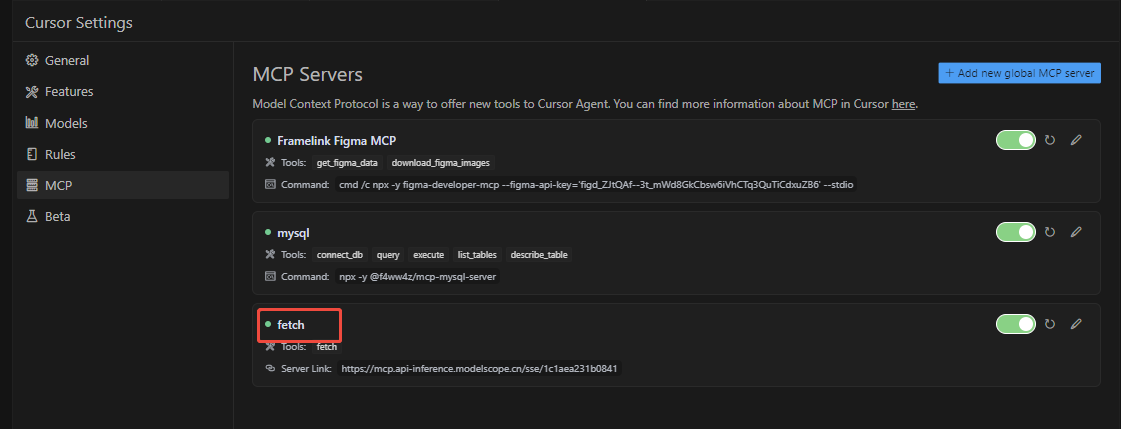
配置好以后,我们只要在对话中输入提示词"通过mcpserver fetch获取文档https://help.aliyun.com/zh/lingma/developer-reference/listkbfiles-get-the-list-of-knowledge-base-files描述的接口规范,并生成示例调用代码",cursor就能自动给我们生成调用代码了
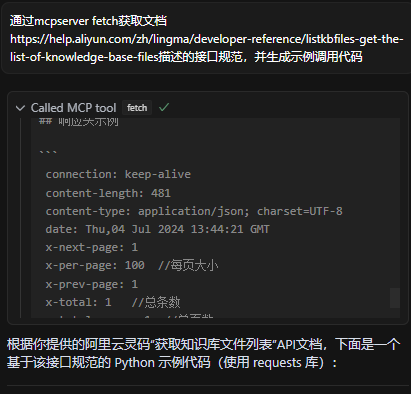
以下是最终生成的代码
```python
import requests
# 替换为你的实际参数
domain = "test.rdc.aliyuncs.com" # 服务接入点
organization_id = "99d1****71d4" # 组织ID
kb_id = "3a41****3eca" # 知识库ID
token = "pt-0fh3****0fbG_35af****0484" # 个人访问令牌
# 可选参数
query = "history" # 文件名称模糊查询
order_by = "gmt_added"
sort = "desc"
page = 1
per_page = 20
url = f"https://{domain}/oapi/v1/lingma/organizations/{organization_id}/knowledgeBases/{kb_id}/files"
params = {
"query": query,
"orderBy": order_by,
"sort": sort,
"page": page,
"perPage": per_page
}
headers = {
"Content-Type": "application/json",
"x-yunxiao-token": token
}
response = requests.get(url, params=params, headers=headers)
if response.status_code == 200:
print("请求成功,返回内容如下:")
print(response.json())
# 你还可以通过 response.headers 获取分页信息
print("总条数:", response.headers.get("x-total"))
print("总页数:", response.headers.get("x-total-pages"))
else:
print("请求失败,状态码:", response.status_code)
print(response.text)
```


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









