






目录
所有create表和改动表数据的都不做(实际中用不到):33-50
6.29: 1、2、4、5、7、8、10!、11、12没做、15、16
6.30:17、18!、19、21!、32;中间跳了22-30
7.4:22、23!、24、25、26
7.5:28!、29、30、51!、52!
#逆向排序
select * from employees
order by hire_date desc limit 1;
desc limit N,M
其中N是跳开吉祥,M是跳开后显示几项
如果要查询倒数第三个:desc limit 2,1
查询倒数第一个:desc limit 1
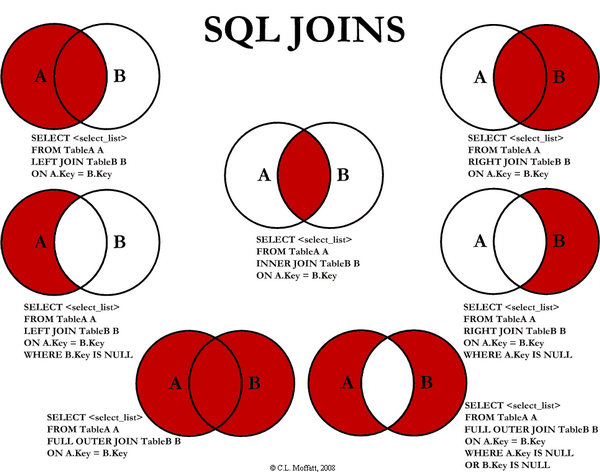
2. 多表查询(join)
select a.last_name, a.first_name, b.dept_no
from dept_emp as b left join employees as a
on a.emp_no = b.emp_no;
#这一段就是保留dept_emp的所有行,然后把employees的弄过来,用emp_no进行链接
select a.last_name, a.first_name, b.dept_no
from employees as a left outer join dept_emp as b
on a.emp_no = b.emp_no;
#主表放在左边,如果没有找到的结果也要显示,则用left outer join
3. group by
select emp_no, count(salary) as t
from salaries
group by emp_no
having t>15;
#group by……having,不能用where4. distinct
select distinct salary from salaries
order by salary desc;
#distinct放最前面
用作去重5. null和not in的用法
select a.emp_no
from employees as a left join dept_manager as b
on a.emp_no = b.emp_no
where b.dept_no is null;
#is null和is not null本质和not in表达的意思是一样的
和上述代码效果相同的是:
select a.emp_no from employees as a
where a.emp_no not in (select b.emp_no from dept_manager as b);6. 取余数
select * from employees
where (emp_no % 2=1) and (last_name != "Mary")
order by hire_date desc;
#取余数,除了 emp_no %2 =1,还有mod(emp_no,2)=1,表示emp_no/2余1
#对于字符(如mary),必须加“”7. avg函数
此题可以和第三题合在一起看,也是对group by的巩固应用
select a.title, avg(b.salary)
from titles as a left join salaries as b
on a.emp_no = b.emp_no
group by a.title;8. left join
select a.last_name, a.first_name, c.dept_name
from employees as a left join dept_emp as b
on a.emp_no = b.emp_no
left join departments as c
on b.dept_no = c.dept_no;
--三表查询,思路也是一样的:
--先把所有要select的字段写出来,
--from后面,join一次只能带两个表,先说左表和关联表用on连结
--再left join一次,用关联表和右表连结9. MAX函数以及嵌套查询
不用order by查工资排名第二的人
-- 错误示范
select a.emp_no,a.last_name, a.first_name, b.emp_no, max(b.salary)
from employees as a left join salaries as b
on a.emp_no = b.emp_no
where (b.salary not in (select max(salary) from salaries))
and (b.salary not in
(select max(salary) from salaries
where salary <
(select max(salary) from salaries)));
-- 正确操作
select a.emp_no, b.salary,a.last_name, a.first_name
from employees as a left join salaries as b
on a.emp_no = b.emp_no
where b.salary=
(select max(salary) from salaries
where salary <
(select max(salary)from salaries
where salary <
(select max(salary) from salaries)));max函数本质是排序后取数的过程,这里错误示范中,select max(salary)本质是select了一个具体数字,而不是一个column。max()返回的一定是一个具体值,而且在进行函数操作的时候会把表格的顺序打乱。
10. 把一张表分拆成两张
没啥好说的,我真牛!
select b.emp_no, (b.salary-c.salary) as growth
from
(select * from salaries
where to_date = "9999-01-01")
as b
join
(select d.*,e.hire_date
from salaries as d
left join
employees as e
on d.emp_no = e.emp_no
where d.from_date = e.hire_date)
as c
on b.emp_no = c.emp_no
order by growth;
11. Mysql的contat函数,用于字符链接
select concat(last_name," ",first_name) as Name from employees;12. join的用法
select d.dept_no, d.dept_name, count(t.salary)
from departments as d join
(select a.dept_no, a.emp_no, b.salary
from dept_emp as a join salaries as b
on a.emp_no = b.emp_no)
as t
on d.dept_no = t.dept_no
group by d.dept_no
order by d.dept_no;
-- 我的作法
SELECT d.dept_no, d.dept_name, count(s.salary) AS SUM
FROM departments d JOIN dept_emp de ON d.dept_no = de.dept_no
JOIN salaries s ON de.emp_no = s.emp_no
GROUP BY d.dept_no
ORDER BY d.dept_no;
-- 别人的作法,意思是一样的,不过三表链接的时候连用两个join,更加简洁13. dense_rank窗口函数
1、RANK()
在计算排序时,若存在相同位次,会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,4······
2、DENSE_RANK()
这就是题目中所用到的函数,在计算排序时,若存在相同位次,不会跳过之后的位次。
例如,有3条排在第1位时,排序为:1,1,1,2······
3、ROW_NUMBER()
这个函数赋予唯一的连续位次。
例如,有3条排在第1位时,排序为:1,2,3,4······
详情用法可以看一下这篇文章
总结下来,如果要分组进行密集排名就是
select m,n,
dense_rank() over (partition by column-name order by XX) as "rank"
from 表格;
select emp_no, salary,
dense_rank() over (
order by salary desc) as m
from salaries
where to_date='9999-01-01'
order by m asc,emp_no asc;14. group by两层统计
如果要统计某个组下,某种身份的count,那group by其实后面可以跟两个column name
select a.dept_no, a.dept_name, c.title, count(b.emp_no)
from departments as a
join dept_emp as b
on a.dept_no = b.dept_no
join titles as c
on b.emp_no = c.emp_no
group by a.dept_no, c.title -- 先按照a.dept_no分组,再按照c.title做count
order by a.dept_no;15. group by……having
如果要把 某一个column条目数 >= 5的行挑出来怎么办
select * from film_category
group by category_id
having count(film_id) >= 5;having是用在group by以后的筛选语法,等效于where
16. right函数
right函数用法:https://www.cnblogs.com/poloyy/p/12894641.html
17. length函数和replace函数
要测出”10,a,b"里面有几个逗号
select
(length(
"10,A,B"
)-length(replace("10,A,B",",","")));length函数用法:
https://www.cnblogs.com/poloyy/p/12894097.html
replace函数用法:
https://www.cnblogs.com/poloyy/p/12894025.html
-- 如果替换的字符为空,不是null,是""















 822
822











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









