







大数据
主要总结大数据中的各种框架架构和执行流程
漫长岁月
1、HDFS✧MapReduce
之前有过对HDFS和MapReduce的详细总结请自行查看之前文章,【跳转】
2、Hive架构✧流程
Hive 简单说就是Hadoop的一个【数据仓库】工具,主要作用就是将半结构化和非结构化的数据映射成一张表,并提供简单的sql功能,底层则是MapReduce
🍯 流程

大致流程:首先通过通过客户端访问thrift服务器,连接后,发出sql语句,此时解析器会对sql进行编译成AST树,并检查是否有语法错误等,再由编译器对AST树进行编译,编译出一个个逻辑计划,再将逻辑计划交给优化器,进行逻辑的优化, 最后交给执行器,执行器会将逻辑计划变成物理计划,也就是启动底层的MapReduce,最后结果存放在HDFS中,其中MetaStore元数据库存放的其实是hive对数据映射成表的映射关系,也就是表的名字,字段列等,再我们的对sql处理的整个过程会通过获取元数据的信息获取具体的表信息。
🍯 架构
- 客户端Client
Hive允许client连接的方式有三个CLI(hive shell)、JDBC/ODBC(java访问hive)、WEBUI(浏览器访问
hive)。JDBC访问时中间件Thrift软件框架,跨语言服务开发。DDL DQL DML,整体仿写一套SQL语句。
- MetaStore元数据库
元数据包括表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是
外部表)、表的数据所在目录等。
- thrift服务器
thrift服务器主要提供对外提供接口,是一个rpc框架,内包含数据传输协议和序列化协议
- Driver
元数据存储在数据库中,默认存在自带的derby数据库(单用户局限性)中,推荐使用Mysql进行存储。
(1) 解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完
成,比如ANTLR;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2) 编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
(4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
3、HBase架构✧流程
Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩、实时读写的分布式数据库。利用Hadoop HDFS作为其文件存储系统,利用Zookeeper作为其分布式协同服务主要用来存储非结构化和半结构化的松散数据(列存 NoSQL 数据库)
💞 流程

读取流程: 首先客户端向Zookeeper访问获取Meta文件,将其加载到内存中,获取rowkey存放的HRegion的HRegionServer的位置,获取位置后,为HRegion创建扫描器,再为Store中的MemStore和StoreFile创建对应的扫描器,然后进行过滤,过滤掉不存在rowkey的MemStore和StoreFile的扫描器,最后进行数据扫描,并合并成最小堆,通过rowkey查出数据。
写入流程: 首先客户端向Zookeeper访问获取Meta文件,将其加载到内存中,获取要插入数据的rowkey存放的HRegion的HRegionServer的位置,建立HRS连接后,将操作先记录到HLog日志中,在进行写入到MemFile中,当MemFile文件写满后申请一个新的MF,进行刷出满的MF,再就是当MF写出的StoreFile文件足够多或者够大时,此时会进行和并,小合并或大合并,而当HRegion足够大时,此时则对HRegion进行切分,切分成两个HRegion。
💞 架构
Client
- 客户端负责发送请求到数据库,客户端连接的方式有很多种
- hbase shell
- 类JDBC- 发送的请求主要包括
- DDL:数据库定义语言(表的建立,删除,添加删除列族,控制版本)
- DML:数据库操作语言(增删改)
- DQL:数据库查询语言(查询–全表扫描–基于主键–基于过滤器)- client维护着一些cache来加快对hbase的访问,比如regione的位置信息。
HMaster
- HBase集群的主节点,HMaster也可以实现高可用(active–standby)通过Zookeeper来维护主副节点的切换为Region server分配region并负责region server的负载均衡管理用户对table的结构DDL(创建,删除,修改)操作
- 表的元数据信息–》Zookeeper上面
- 表的数据–》HRegionServer上- 当HRegionServer下线的时候,HMaster会将当前HRegionServer上的Region转移到其他的HRegionServer
Zookeeper
- 保证任何时候,集群中只有一个master
- 存贮所有Region的寻址入口,存储所有的的元数据信息。
-实时监控Region Server的状态,将Region server的上线和下线信息实时通知Master- 存储Hbase的schema,包括有哪些table,每个table有哪些column family
HRegionServer
- 属于HBase的具体数据管理者,主要维护Master分配给它的region,并对HMaster实时保持心跳,汇报当前节点的信息
HRegion
- HRegion是HBase上的分布式存储和负载均衡的最小单元,每个region中存放表的一部分
- 每个表可以再多个region,但一个region只能存放一张表
Store
- Store是HRegion中存放列簇的,也是具体数据存放的地方,分未MemStore和StoreFile组成
- MemStore,数据优先存放此处,达到128后,便向刷出,刷出的文件会形成一StoreFile文件,StoreFile文件存放再HDFS上格式未HFile
Hlog
- 就是一个日志文件,每次的写入操作都会先记录日志文件中,一旦到达阈值也会刷出到HDFS中
4、Apache Phoenix
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs而不是HBase客户端APIs来创建表,插入数据和对HBase数据进行查询。Phoenix完全使用Java编写,作为HBase内嵌的JDBC驱动。Phoenix查询引擎会将SQL查询转换为一个或多个HBase扫描,并编排执行以生成标准的JDBC结果集。
🍤 Phoenix系统架构
重客户端架构
从其架构来看,Phoenix结构上划分为客户端和服务端两部分:
- 客户端包括应用程序开发,将SQL进行解析优化生成QueryPlan,进而转化为HBase Scans,调用
- HBase API下发查询计算请求,并接收返回结果;
服务端主要是利用HBase的协处理器(Phoenix-core包里面包含hbase-client,以及hbase-server
包),处理二级索引、聚合及JOIN计算等。
这种架构我们称之为重客户端架构,也是目前Phoenix使用最广泛的方式,但是这种方式存在一些使用上的缺陷:
- 应用程序与Phoenix core绑定使用,需要引入Phoenix内核依赖,目前一个单独Phoenix重客户端
集成包已达120多M;- 运维不便,Phoenix仍在不断优化和发展,一旦Phoenix版本更新,那么应用程序也需要对应升级
版本并重新发布;- 仅支持Java API,其他语言开发者不能使用Phoenix。
轻客户端架构
轻客户端架构将Phoenix分为三部分:
- 瘦客户端是用户最小依赖的JDBC驱动程序,与Phoenix依赖进行解耦,支持Java、Python、Go等多种语言客户端;
- QueryServer是一个单独部署的HTTP服务,接收轻客户端的RPC请求,并将SQL转发给PhoenixCore进行解析优化执行;
- Phoenix Server与重客户端架构相同。
QueryServer基于Calcite的Avatica组件实现,内部嵌入了独立的Jetty HttpServer,支持Protobuf和JSON两种RPC传输协议,其中Protobuf是默认协议,提供比JSON更高效的通信方式。
由于QueryServer是无状态的,可以部署在HBase集群的每台RegionServer上,通过HTTP负载均衡器将多个客户端的请求分发在多个QueryServer上。
5、Flume架构✧流程
Flume是一个分布式、可靠、和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
🍣 流程

大致流程: 首先整体架构是由三部分,
Source、Channel、Sink,最初由Source对数据进行收集,收集数据通过doPut将数据推入缓存区doLIst,此时会有doCommit去判断Channel通道中是否有足够空间进行传输,够则进行封装成event事件,(不够则进行回滚)封装event推给ChannelProcessor,ChannelProcessor则会将event推送给拦截器链进行处理,过滤后返回给CP,再将event交给通道选择器(ChannelSelectors),获取event改分发给那个Channel后,再由ChannelProcessor分发下到Channel通道,此时会在taskList缓存区等待SinkProcessor进行拉去,由多个sink进行不同的目的地的输送,再输送过程中由taskCommit判断是否成功传输到HDFS或其他地方,如果成功,则删除缓存和通道中的event事件,否则回滚。
🍣 架构

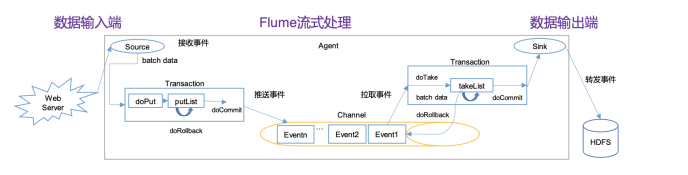
Source
- source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中。 Flume提供了很多内置的Source, 支持 Avro, log4j, syslog 和http post(body为json格式)。可以让应用程序同已有的Source直接打交道,如AvroSource,SyslogTcpSource。 如果内置的Source无法满足需要, Flume还支持自定义Source。
Channel
- Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件。介绍两个较为常用的Channel, MemoryChannel和FileChannel。
Sink
- Sink从Channel中取出事件,然后将数据发到别处,可以向文件系统、数据库、 hadoop存数据,
也可以是其他agent的Source。在日志数据较少时,可以将数据存储在文件系统中,并且设定一定
的时间间隔保存数据。
6、Ganglia组件
Ganglia是UC Berkeley发起的一个开源集群监视项目,设计用于测量数以千计的节点。Ganglia的核心包含gmond、gmetad以及一个Web前端。主要是用来监控系统性能,如:cpu 、mem、硬盘利用率,I/O负载、网络流量情况等,通过曲线很容易见到每个节点的工作状态,对合理调整、分配系统资源,提高系统整体性能起到重要作用。
🎁 工作组件

Ganglia 监控套件包括三个主要部分:
gmond,gmetad,和网页接口ganglia-web
- Gmond :是一个守护进程,他运行在每一个需要监测的节点上,收集监测统计,发送和接受在同一个组播或单播通道上的统计信息 如果他是一个发送者(mute=no)他会收集基本指标,比如系统负载(load_one),CPU利用率。他同时也会发送用户通过添加C/Python模块来自定义的指标。 如果他是一个接收者(deaf=no)他会聚合所有从别的主机上发来的指标,并把它们都保存在内存缓冲区中。
- Gmetad:也是一个守护进程,他定期检查gmonds,从那里拉取数据,并将他们的指标存储在RRD存储引擎中。他可以查询多个集群并聚合指标。他也被用于生成用户界面的web前端。
- Ganglia-web :顾名思义,他应该安装在有gmetad运行的机器上,以便读取RRD文件。 集群是主机和度量数据的逻辑分组,比如数据库服务器,网页服务器,生产,测试,QA等,他们都是完全分开的,你需要为每个集群运行单独的gmond实例。
一般来说集群中每个节点需要一个接收的gmond,每个网站需要一个gmetad
7、Sqoop架构✧流程
基于 Hadoop 之上的数据传输工具 Sqoop 是 Apache 的顶级项目,主要用于在 Hadoop 和关系数据库、数据仓库、No SQL 系统间传递数据。通过 Sqoop 我们可以方便地将数据从关系数据库导入到HDFS、HBase、Hive,或者将数据从 HDFS 导出到关系数据库。使用 Sqoop 导入导出数据的处理流程。
🎨 导入导出流程

导入流程:首先Sqoop会从数据库中获取表的元信息(表名,字段,数据类型…),将获取的表映射成一个同名的javaBean对象,存放在Sqoop的记录容器中,Sqoop启动MapReduce进行作业,Map从数据库中获取表数据,并从记录容器中获取javaBean,进行反序列化,进行传输,最后序列化成文本存放到HDFS中

导出流程: 前一部分都是相同的,当Sqoop启动MapReduce时,则Map会去HDFS获取文档数据,此时获取记录容器中的JavaBean进行反序列化成对象进行传输,有Map进行切分传输,并转换成sql,insert语句进行插入数据库表中
8、DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。

🥝 架构流程

架构及其流程: 首先DataX主要三部分由FrameWork+plugin读写组件组成,三者组成一个流程,此流程被称为一个JOB,一个JOB对应一个进程完成作业同步,具体流程,则是,数据由ReaderPlugin读入,会通过DataXJob(节点管理者)进行数据的切分,切分成一个个Task(最小单元)任务,再由Scheduler模块进行分组通过并发数进行划分,分成一个个TaskGroup,每个任务组默认五个并发,又任务组启动组内的Task,直到每个任务组都完成,否则会抛出异常,返回值非0,全部成功则成功退出JOB
举例:
DataX调度流程:
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个200张分表的mysql数据同
步到odps里面。 DataX的调度决策思路是:
- DataXJob根据分库分表切分成了200个Task。
- 根据20个并发,DataX计算共需要分配4个TaskGroup。
- 4个TaskGroup平分切分好的200个Task,每一个TaskGroup负责以5个并发共计运行50个Task。
















 594
594











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











