







Hadoop版本
1.hadoop有两个完全不同的版本
hadoop 1.0 架构里有:
MapReduce
HDFS
common
hadoop 2.0架构里有:
MapReduce
yarn
HDFS
common
2.hadoop2.0中MapReduce是运行在yarn上的
HDFS
思想:将一台机器上存不下的数据存到多台机器上
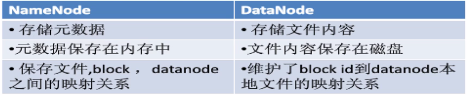
HDFS体系
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NarmeNode)和若干个数据节点(DataNode)。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求、在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的。
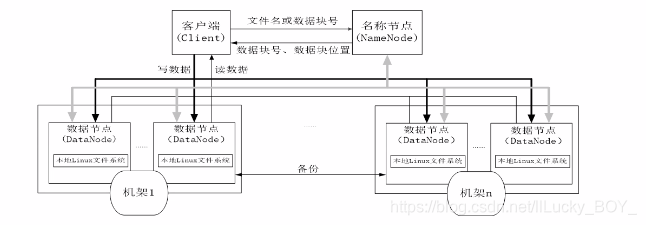
NameNode
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间(Namespace),保存了两个核心的数据结构,即Fslmage和EditLog
不适合存储小文件因为一个文件就会生成一个block一个block是150个字节
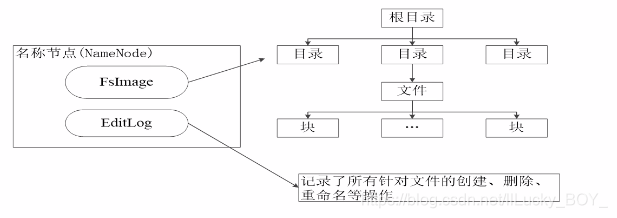
Fslmage
FsImage用于维护文件系统树以及文件树中所有的文件和文件夹的元数据
EditLog
操作日志文件EditLog中记录了所有针对文件的创建、删除、重命名等操作
这两个文件在哪,怎么看
在hadoop-2.7.2/data/tmp/dfs/name/current
seen_txid文件保存的是最新的edits的后缀数字
当直接打开这些文件的时候是乱码
oiv
看fsimage
hdfs oiv -p XML -i 要看的名字 -o 重命名的文件名
oev
看editlog
hdfs oev -p XML -i 文件名 -o 重命名文件名
NameNode的启动
1.在名称节点启动的时候,它会将Fslmage文件中的内容加载到内存中,之后再执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
2.一旦在内存中成功建立文件系统元数据的映射,则创建一个新的Fslmage文件和一个空的EditLog文件
3.名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为Fslmage文件一般都很大(GB级别的很常见),如果所有的更新操作都往Fslmage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog文件里面写就不会这样.因为EditLog 要小很多。每次执行写操作之后,且在向客户端发送成功代码之前edits文件都需要同步更新
SeconderyNameNode
1.解决NameNode运行期间EditLog不断变大的问题,当名称节点重启的时候,由于EditLog特别大,所以重启会非常的慢
2.SeconderyNode是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS元数据信息的备份,并减少名称节点重启的时间。3.SecondaryNameNode一般是单独运行在一台机器上。
4.SecondaryNameNode的工作情况:
(1) SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件.暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2) SecondaryNameNode通过HTTP GET方式从
NameNode上获取到Fslmage和EditLog文件.并下载到本地的相应目录下;
(3) SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的Fslmage保持最新;
这个过程就是EditLog和Fslmage文件合并;
(4) SecondaryNameNode执行完(3)操作之后,会通过post方式将新的Fslmage文件发送到NameNode节点上
(5) NameNode将从SecondaryNameNode接收到的新的Fslmage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
SeconderyNameNode自动合并(checkpoint)
默认一个小时或者1000000条数据
checkpoint时间设置
默认配置:hdfs-default.xml中
在hdfs-site.sh中添加:
<property>
<name>dfs.namenode. checkpoint.period</name><value>3600(每隔一小时合并一次)</value>
</property>
<property>
<name>dfs.namenode.checkpoint .txns</ name><value>1000000(操作动作次数)</value>
</property>
<property>
<name>dfs.namenode. checkpoint.check.period</name><value>60(1分钟检查一次操作次数)</value>
当namenode挂了怎么办
通过seconderynamenode把namenode恢复
模拟:
方法1:
1.用kill -9 把namenode强行挂掉
2.删除/data/tmp/dfs/name下的所有数据
3.拷贝seconderynamenode中的namesecondery的数据到namenode的name里来
4.重新启动namenode节点
方法2:
修改hdsf-site.xml
<property>
<name>dfa.namenede .checkpoint.periad</name><value>120</value>
</property>
<property>
<name>dfs.namnenode.name.dir</name>
<value>/home/hduser/software/hadoop-2.7.2/data/tmp/dfs/name</value>
</property>
2.用kill -9 把namenode强行挂掉
3.删除/data/tmp/dfs/name下的所有数据
4.将seconderyname里的namesecondery拷贝到同级目录下要恢复的主机中,删除In_use.lock文件
5.hdfs namenode -importCheckpoint
6.重启namenode
DataNode
1.数据节点是分布式文件系统HDFS的工作节点.负责数据的存储和读取.会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表
2.每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中
MapReduce
不是实时计算(离线计算)
MapReduce的作业主要包括:(1)从磁盘或从网络读取数据,即IO密集工作;(2)计算数据,即CPU密集工作
yarn
资源管理任务调度
计算机的集群结构
集群:机架,节点
机架是由交换机互联
节点用过网络互联
hadoop中的集群节点类型
1.NameNode:负责协调集群中的数据存储2.DataNode:存储被拆分的数据块
3.SecondaryNameNode:帮助NameNode收集文件系统运行的状态信息
三个节点分为两类:主节点(名称节点)
从节点(数据节点)
请求数据顺序:首先访问主节点(namenode)
之后,
块
HDFS默认一个块128MB,一个文件被分成多个块.以块作为存储单位块的大小远远大于普通文件系统.可以最小化寻址开销
优点:
1.支持大规模文件存储
2.简化系统设计
3.适合数据备份
HDFS缺点
1.命名空间的限制:名称节点是保存在内存中的,因此,名称节点能够容纳的对象(文件、块)的个数会受到内存空间大小的限制。
2.性能的瓶颈:整个分布式文件系统的吞吐量,受限于单个名称节点的吞吐量。
3.隔离问题:由于集群中只有一个名称节点.只有一个命名空间.因此.无法对不同应用程序进行隔离。
4.集群的可用性:一旦这个唯一的名称节点发生故障,会导致整个集群变得不可用。
数据存放策略
1.第一个副本:放置在上传文件的数据节点;如果是集群外提交,则随机挑选一台磁盘不太满、CPU不太忙的节点
2.第二个副本:放置在与第一个副本相同的机架的不同节点上
3.第三个副本:与第一个副本不同机架的随机节点上
块的大小是怎么定的(面试题)
1.可改变块的大小:
2.如果寻址时间约为10ms,寻址时间为传输时间的1%为最佳状态
所有传输时间=10/0.01=1000ms
而目前磁盘的传输速率为100MB/s
1*100=100mb
因为进位问题所以是128mb
HDFS的shell操作
格式:hdfs dfs -
secondnamenode如果不配置的话默认是本机(一般在一个单独的机器上)
datanode是存储数据的
namenode是存储元数据(目录)
Secondarynamenode是预先合并FSimage和EditLog为了加快namenode重启的时间
resourcemanager是资源管理和任务调度
nodemanager是实际执行任务的
特有的命令
cp,mv只能从HDFS内拷贝到HDFS的另一个地方
hdfs fs 查看都有什么命令
hdfs dfs -help tail 查看tail怎么用
hdfs dfs -moveFromLocal abc /:从本地剪切粘贴到HDFS
hdfs dfs -copyFromLocal a.txt /user/hduser/a2.txt 复制a.txt到HDFS并改名
注:效果和put一样
hdfs dfs -copyToLocal /a.txt /home/hduser/
hdfs dfs -get /a.txt /home/hduser/
get和copyToLocal一样
hdfs dfs -appendToFile cc.txt /user/hduser/a.txt将cc.txt文件里的内容追加到a.txt末尾
hdfs dfs -getmerge /user/hduser/* ./aaaa2.txt合并几个文件中的内容到一个文件中
集群安全模式
hdfs dfsadmin -safemode get 查看安全模式状态
enter 进入
leave 离开
wait 等待
安全模式下无法写入数据可以读数据
进入安全模式:
重启namenode的时候
白名单
配置步骤:
1.在hadoop/etc/hadoop下创建dfs.hosts文件
2.在文件中写入信任的主机名
3.在namenode的hdfs.site.xml配置文件中增加dfs.hosts属性
<property>
<name>dfs.hosts</name>
<value>/home/hduser/software/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
4.配置文件分发:
xsync hdfs-site.xml
5.刷新namenode:
hdfs dfsadmin -refreshNodes
6.刷新Resourcemanager:
yarn rmadmin -refreshNodes
7.检验:在浏览器中查看
黑名单
1.在hadoop/etc/hadoop下创建dfs.hosts.exclude文件
2.在文件中写入要退役的主机名
3.在namenode的hdfs.site.xml配置文件中增加dfs.hosts.exclude属性
4.配置文件分发:
xsync hdfs-site.xml
5.刷新namenode:
hdfs dfsadmin -refreshNodes
6.刷新Resourcemanager:
yarn rmadmin -refreshNodes
7.这样退役节点的状态就是decommission in progress(退役中)
说明数据节点正在复制块到其他节点
复制完之后为 decommission
注:当副本数小于等于3时是无法退役成功的
当只有三个节点的时候无法生成四个副本所以要将副本数配成3
修改副本数
hdfs dfs -setrep 3 文件绝对路径















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









