









Database Management Systems
Part 3: Storage and Indexing
chapter 8
chapter 9
Chapter 10 Tree-structured Indexing
ISAM: Indexed sequential access method -- static index structure effective when the file is infrequently updated --> B+ tree: dynamic
leaf pages contain data entries; non-leaf pages contain index entries of the form (search key value, page id)
intuition: build an auxiliary structure recursively until the smallest one fits on one page, one-level index -> tree structure: traversal with one I/O (at most; some page, e.g. the root are likely to be in the buffer pool) per level. Given the typical fanout (>100), trees rarely have more than 3-4 levels.
ISAM:
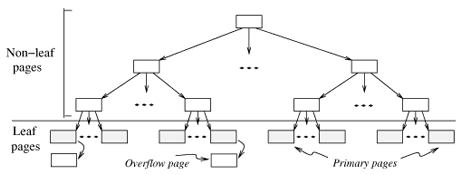
page allocation in ISAM: data pages, index pages, overflow pages
primary leaf pages are allocated sequentially, because the number of such pages is known when the tree is created and does not change under inserts and deletes (so no 'next leaf page' pointers are needed)
once the ISAM file is created, inserts and deletes affect only leaf pages --> insertion: may add overflow pages; deletion: simply removing the entry (and remove empty overflow pages, but leave empty primary page as it is)
overflow chain may be long (and data in the overflow chain usually not sorted to make inserts fast): to alleviate this problem, the tree is initially created so that about 20 percent of each page is free
advantage over B+ trees: leaf pages allocated in sequence, not locking index-level pages
B+ tree: balanced, leaf paged linked with page pointers into a doubly linked list, minimum occupancy of 50% for each node except the root (often without adjusting because files typically grow rather than shrink)
B+ tree typically maintain 67% space occupancy
non-leaf nodes with m index entries contain m+1 pointers to children; pointer p_i points to a subtree in which all key values are such that k_i <= k < k_(i+1)
finding i requires to search within the node, either linear or binary (depending on the number of entries)
algorithms: search, insert (and split or redistribute), delete (and merge or redistribute)
duplicate keys: use overflow pages; typically use alternative approach: search for left-most data entry with the given key and possibly retrieve more than one leaf page (but some problems with deletion, e.g. consider rid to be part of the search key, Sec 10.7)
B+ tree in practice:
height of B+ tree (= number of disk I/O) depends on number of data entries and size of index entries (fan-out): log_fanout (# of data entries) --> need to maximize fanout
index entry: search key value + page pointer --> key compression: need not store search key values in their entirety, e.g. prefix key compression
bulk-loading for creating a B+ tree index on an existing collection of data records (Sec 10.8.2)
if B+ tree is a clustered index, then operations such as splits, merges, and redistributions can change rids (which is typically represented by some combination of physical page number and slot number, allowing for moving records within a page but not across pages) --> such operations require compensating updates to other indexes on the same data.















 215
215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









