





摘要
对于高资源语言(HRL),大型语言模型(LLM)表现出令人印象深刻的零/少镜头推理和生成质量。他们中的一些人已经接受了低资源语言(LRL)的培训,并且表现不佳。由于训练LLM的成本过高,它们通常被用作网络服务,客户端按输入和输出令牌的计数收费。令牌的数量在很大程度上取决于脚本和语言,以及LLM的子单词词汇表。我们发现LRL在定价上处于劣势,因为众所周知的LLM为LRL产生的代币比HRL多。这是因为目前大多数流行的LLM都是针对HRL词汇进行优化的。我们的目标是创造一个公平的竞争环境:降低当代LLM中处理LRL的成本,同时确保不承诺预测和生成质量。为了减少LLM处理的代币数量,我们考虑了LRL到HRL的代码混合、翻译和音译。我们使用IndicXTREME数据集进行了广泛的研究,涵盖了15种印度语,同时使用GPT-4(迄今为止发布的最昂贵的LLM服务之一1)作为商业LLM。我们观察并分析了多种语言和任务中涉及代币数量、成本和质量的有趣模式。我们表明,选择与LLM交互的最佳策略可以通过~90%,同时与原始LRL中的LLM通信相比,提供更好或类似的性能。
1 引言
大型语言模型(LLM),如GPT-4(Ope-nAI等人,2023)、ChatGPT、Llama-2(Touvron等人,2023),PaLM(Chowdhery等人,2022),interalia,以其卓越的零/少镜头推理和生成能力,对NLP的发展做出了巨大贡献。LLM还可以减少对昂贵的人工生成黄金数据的依赖,以微调各种下游任务的模型,特别是对于黄金数据稀缺的LRL。然而,我们的经验表明,这一好处被一个问题所抵消。像GPT-4这样的商业LLM服务按照与客户端交换的代币数量收费。从客户端到LLM的典型消息包括一个任务描述或指令,后面是零个或多个“上下文示例”中的少数镜头,以及要解决的有效载荷实例。
LLM的输出标记表示对有效负载实例的解析。客户端和LLM服务之间交换的令牌数量取决于LLM的(子词)词汇表以及客户端使用的语言。如果客户的语言是LRL,LLM很可能会将LRL标记大量划分为子词,因为LRL子词在当今最流行的LLM中具有少数地位(Hong et al.,2021)。因此,与HRL客户端相比,LLM的使用将是昂贵的。尽管在推理和指令跟随能力方面有了巨大的飞跃,但GPT-4以与其前身的多语言模型mBERT和XLM-R相同的方式和原因,有效地区分了LRL客户端(Conneau等人,2020)。这导致LRL客户在定价方面(如果不是在质量方面)处于不利地位。我们的目标是减少这种不平等现象。我们选择GPT-4是因为它是最昂贵(但最受欢迎)的com之一商业黑盒LLM即服务。使用GPT-4 8K上下文模型API的成本为每1000个输入令牌0.03美元,每1000个输出令牌0.06美元。对于32K上下文模型,成本高达每1000个输入令牌0.06美元,每1000个输出令牌0.12美元。因此,将维基百科(约60亿个代币)汇总到其一半大小的任务将花费72万美元和36万美元,GPT-4的上下文长度分别为32K和8K。
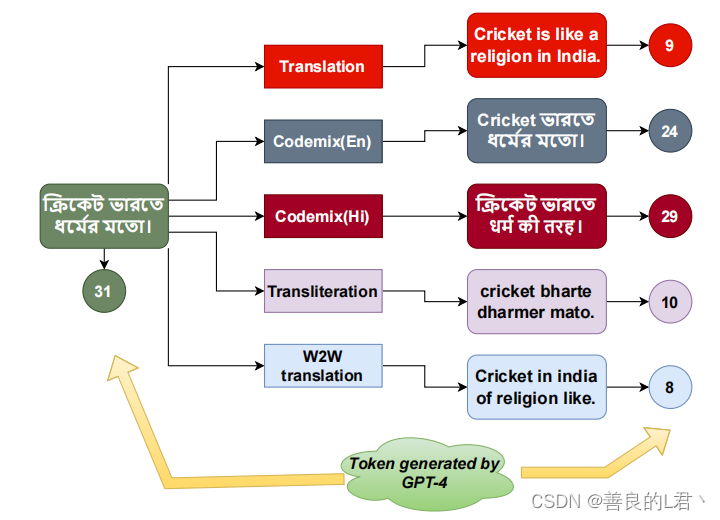
我们的初步研究表明,GPT-4为不同印度语言的源句翻译生成了双宇宙数量的标记。如果直接与LLM通信,我们还可以获得这些语言中默认LRL任务性能的概要文件。面对我们无法影响的黑匣子服务,我们可以使用的工具是预处理从客户端到LLM服务的LRL消息。具体来说,我们试图通过减少客户端和LLM之间交换的令牌数量来降低API成本,同时努力保持任务质量。这可以通过多种方式实现,如图1所示,稍后将详细介绍。
为了比较这些方法,我们定义(在等式1中)一个称为“相对性能成本比”(RTPCR)的度量,该度量指定了我们可以获得的任务性能,给定了我们使用各种预处理方法M相对于使用原始LRL文本所支付的令牌驱动成本。我们不再直接将LLM服务访问成本与内部LLM的运营成本进行比较,因为后者取决于太多难以建模的因素,如电源和冷却成本(以及与LLM服务的比较)。
与使用开源机器翻译工具的免费翻译相比,在推理之前使用LLM的显式实例翻译将产生额外的成本。另一种选择是隐式翻译,在隐式翻译中,我们指示LLM在解决有效载荷实例之前,在后台将其翻译成英语,从而节省显式翻译成本。(我们不要求LLM提供翻译版本。)我们观察到,使用隐式翻译的改进落后于隐式翻译。因此,在LLM服务之外使用专用的LRL-to-HRL翻译器可以节省成本并提高LRL任务质量。如果LRL没有高质量、开源的翻译器,那么可能会出现问题,而依靠LLM进行翻译将增加成本并降低RTPCR。我们接下来将向第三个方向出发:混合LRL和HRL单词有帮助吗?为了降低成本,我们可以使用LRL-HRL或LRL-LRL词典,因为这样的翻译通常与上下文无关。最后,作为选择性单词混合的自然伴侣,我们尝试了一种音译技术,将整个LRL消息音译成拉丁文字。毕竟,与“纯”LRL相比,用于训练LLM的巨大语料库更有可能包含重音译成拉丁文字的LRL单词,这些单词与本地LRL和HRL单词混合。
我们总结我们的贡献。(1) 我们发现了希望解决LRL问题的LLM客户面临的一个关键性价比劣势。(2) 我们使用我们引入的一种称为RTPCR的新措施,证明了GPT-4相对于15种用于不同分类任务的印度语言存在这种缺点。(3) 我们对隐式和显式客户端消息翻译进行了实验,并比较了它们的RTPCR评分,以表明免费翻译器可以降低成本并提高性能。(4) 我们对单词混合和音译进行了实验,结果表明两者都有助于降低成本,但音译可能会对性能产生影响。(5) 除了攻击性表现外,我们还提供了许多案例研究,其中有有趣的发现:不同印度语言的to ken计数差异很大,翻译成英语可能会增加和减少英语单词的数量,这取决于源语言;LLM的性能对语法相当敏感。
2 相关工作
最近的LLM,如ChatGPT、GPT-4(OpenAI等人,2023年)、LLAMA-2(Touvron等人,2023)、Palm(Chowdhery等人,2022年)、Bloom(Scao等人,2022年)等,在语言和任务上表现出令人难以置信的零和少数拍摄能力。尽管他们在高资源语言(HRL)中的表现令人印象深刻,但研究发现,低资源语言(LRL)的表现水平并不相同。
各种基准数据集,如Xtreme(Hu等人,2020年)、Xtreme-R(Ruder等人,2021年)和Xglue(Liang等人,2020)已设计用于测量Multilin Gual LLM的跨语言能力。LRLS中也提供了印度语言的基准,例如IndicXtreme(Doddapaneni等人,2023年)。基准也适用于其他语言家族,如非洲(Ade Lani等人,2022年)和印度尼西亚语(Wilie等人,2020年)。在这项工作中,我们使用IndicXtreme。MEGA(Ahuja等人,2023年)见证了将测试实例翻译成英语时任务性能的提高。他们说,他们使用Bing Trans Lator(不是开源工具)从性能角度进行实验。与他们不同,我们的重点不仅是性能,还包括成本。由于使用GPT-4对LRL的成本很高,我们正在试验不同的技术,以在不影响性能的情况下降低成本。类似地,最近的一项研究(Huang等人,2023年)发现,用英语编写的提示比用其他低资源语言编写的提示表现更好。节俭的GPT(Chen等人,2023年)试图在不同的层面上解决GPT-4的成本问题,例如选择较低但在上下文中更有效的示例,用于很少的推断,隐藏以前的查询和未来使用的响应,或LLM级联,其中廉价的LLM首先尝试检查响应是否合理,如果之前的响应不令人满意,则仅适用于昂贵的响应。他们有过英语方面的经验,那里的单词没有太多的碎片。LRLS提出了一个陡峭的挑战,首先,我们需要通过控制LRL单词的过度碎片化来降低成本。
因此,可以应用FrugelGPT进一步提高成本。据我们所知,我们首先研究了以各种不同方式准备LRL输入实例并将其与LLM API成本相关时对性能的影响。
3 方法
在这项工作中,我们主要使用以下技术对原始LRL输入实例进行预处理,以减少生成的令牌数量。
3.1 Native
在这里,我们按照原始语言脚本中的原样传递查询实例。我们将此方案与以下所有方案进行比较。
3.2 翻译
在这里,我们在通过GPT-4之前翻译LRL输入实例。翻译时,我们考虑三种可能性。
使用开源MT:我们依靠现成的机器翻译工具将LRL翻译成英语。为此,我们使用IndicTrans2(Gala等人,2023)。
明确使用GPT-4:我们首先用GPT-4作为翻译器将LRL句子翻译成英语;然后我们将翻译的英语句子传递给GPT-4进行推理。
隐式使用GPT-4:在这里,我们的提示(参见附录图6)指示GPT-4“在其前提下”将LRL实例翻译成英语。如果它在理解LRL的立场方面面临困难。希望能节省一些费用,因为我们不要求英文翻译。
隐式翻译的主要问题是我们无法控制它选择翻译哪些LRL实例,也无法控制翻译的质量或效果。在这两种显式翻译方法之间,从成本的角度来看,开源机器翻译工具显然更好,但对于一些LRL来说,这种机器翻译可能并不容易获得。在这种情况下,使用GPT-4的显式翻译可能会有所帮助,但它会带来API调用提前进行翻译的额外成本负担。
3.3混合词
在这种方法中,如果一个LRL单词在LLM子单词词汇表中被过度分割(详见附录B中的算法1),那么我们将用相应的英语翻译替换该单词。我们将新输入称为Wordmix(En),因为它现在是一个“合成”文本,包含LRL和英语(或者更有利的LRL,比如印地语-Wordmix)单词的混合,因此得名。请注意,在单词混合法中,我们不需要任何翻译工具;一本LRL-HRL或LRL-LRL词典就足够了。极端情况是所有LRL单词都被单独翻译成英语——W2W。有关Wordmix(Hi)和W2W的结果,请参阅附录A。
3.4平移
在这种方法中,我们将LRL脚本音译为英语(拉丁脚本)。由于我们现在将处理拉丁脚本中的原始LRL输入实例,因此假设生成的令牌(如图1所示)将少于原始LRL脚本。因此,成本应该会降低。使用音译的另一个动机是GPT-4(和其他流行的LLM,尽管大多未公开)的训练语料库可能包括社交媒体或市场数据,其中包括大量拉丁文字的LRL文本。
3.5 RTPCR
为了在成本和性能方面相对于原生脚本对这些技术进行排名,我们设计了一个称为RTPCR(relative performance To cost Ratio)的指标:这里,Perf(M)和Perf(Native)分别表示方法M和自然LRL脚本的任务特定性能。类似地,Cost(M)和Cost(Native)分别表示方法M和本机LRL脚本所产生的成本。当M的性能优于本机时,RTPCR将很高,并且M的成本低于本机。相反,低RTPCR值表明M在性能方面滞后,但比使用本机文本产生的成本更高。表4显示了不同技术的RTPCR值。
4 实验和结果
4.1 数据集和评估指标
我们对IndicXTREME(Dodapaneni et al.,2023)基准数据集中可用的所有分类任务进行了实验(详细信息见表1)。这些任务包括两个单句分类任务(IndicSentiment、Alexa意图分类)和三个多句分类任务,即IndicCOPA、IndicXNLI和IndicXParaphrase。整个测试设置涵盖了15种印度语言。我们将准确度分数作为性能矩阵报告。附录讨论了与不同提示设计(图6)和GPT-4 API超参数(表6)相关的所有细节。
4.2 拉丁文脚本减少了令牌生成
在图2中,我们显示了如果一个句子以其自己的脚本通过GPT-4,通过开源MT和GPT-4翻译成英语,并转换成英语脚本,则每个单词生成的平均标记数。一般的观察结果是,当处理拉丁脚本(翻译或音译)中的实例时,令牌生成会大大减少。归约可以是2×到7×之间的任何值,具体取决于语言。另一个有趣的观察结果是,德拉威语的减少率更高,如马来阿拉姆语、泰米尔语、泰卢固语、卡纳达语等,而北印度语言的减少率相对较低,如印地语和孟加拉语。这可能意味着GPT-4在北印度语言方面比在南印度语言方面训练得更好。这里需要注意的另一件事是,尽管音译不一定能产生一个有效的英语单词,但它仍然有助于减少标记生成的数量。
4.3 翻译效果更好
在表2中,我们比较了GPT-4在不同技术下的准确性。我们还显示,与本机脚本相比,性能的变化(%)每个准确度值都很低。从表中可以清楚地看出,总的来说,翻译提高了GPT-4性能,无论是GPT-4的翻译、像IndicTrans这样的开源MT还是GPT-4进行的隐式翻译。然而,印度语翻译在大多数情况下占据了上风。从这一观察中可以清楚地看出,GPT-4比LRL更能理解英语文本。其次,考虑到我们的单词混合技术有点粗糙,并且可以通过改进单词替换启发式来进一步改进,单词混合(En)也表现出了与原生脚本相当的性能。Wordmix(Hi)的表现也与Wordmix(En)类似,但考虑到成本降低,后者更有成效(详细信息见附录A)。另一方面,在翻译中,表现会下降,这是意料之中的,因为我们不是在把这个词翻译成英语,而是在修改剧本。
4.4 开源MT降低成本
在表3中,我们比较了GPT-4推理的不同技术所产生的成本。由于成本与输入和输出生成的令牌成比例,我们使用每个查询实例生成的平均令牌作为成本的代理。在报告不同技术的每个实例的平均令牌生成的同时,我们还显示了与本机脚本相比,令牌生成的年龄变化百分比。在这里,观察结果很清楚:除了通过GPT-4进行翻译外,所有技术都降低了成本。这是意料之中的,因为在这种方法中,我们首先使用GPT-4显式翻译实例,然后使用GPT--4再次使用翻译后的实例进行分类。因此,在这里,我们需要承担使用GPT-4的翻译成本的额外负担.另一方面,通过IndicTrans(开源MT)进行翻译可将成本降低90%。但在没有这种免费MT的情况下,可以使用单词混合或音译,这也大大降低了成本。话虽如此,音译会影响性能(见表2)。
4.5 RTPCR有助于找到最佳性价比
表4显示了与Native脚本相比不同方法的RTPCR。在这里,IndicTrans的翻译显然是赢家,原因显而易见。这种情况下的翻译是免费的,当我们使用英语翻译的查询实例时,我们在表2中看到的GPT-4性能得到了改进。RTPCR得分最低的是使用GPT-4的翻译,因为尽管翻译后性能有所提高,但我们为翻译支付的成本超过了性能增益。传输的RTPCR也很高——尽管性能有所下降,但与使用本机脚本相比,它显著降低了成本。用于wordmix和通过GPT-4的隐式翻译的RTPCR也优于原生(RTPCR为1),因为wordmix的性能与原生类似,但降低了成本。另一方面,GPT-4的隐式翻译成本与原生脚本相同,但隐式翻译的性能增益更多。
4.6 结果分析
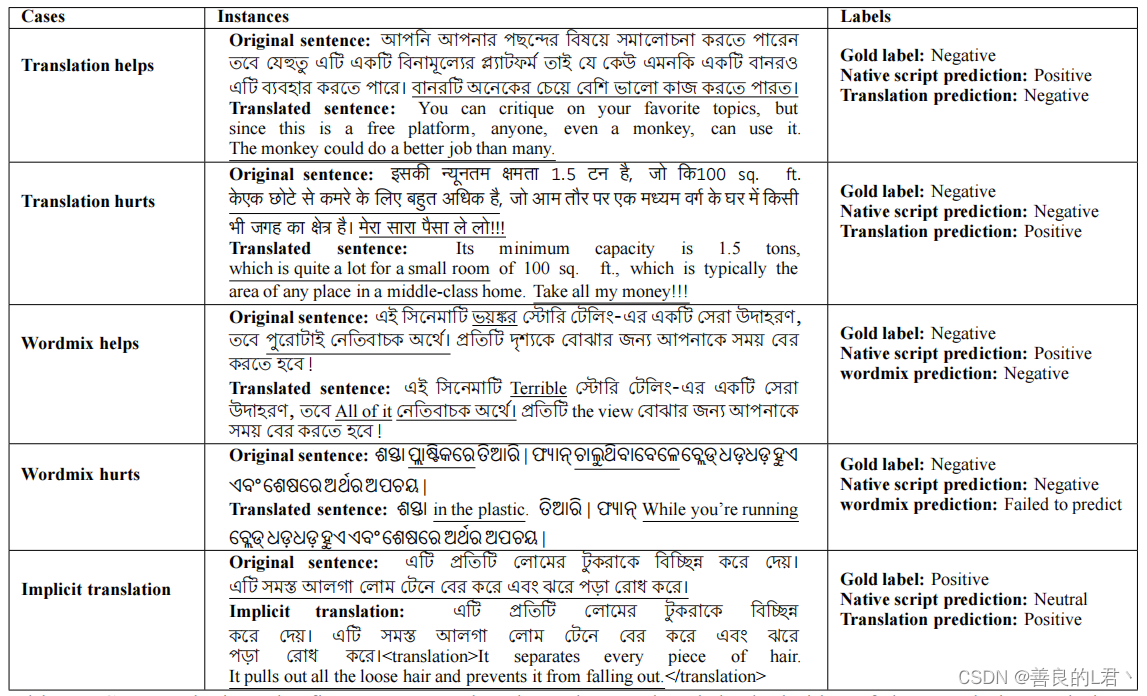
在表5中,我们展示了一些例子,涵盖了我们方法中的不同案例。前两个例子与翻译方法有关。
如前所述,翻译可以提高推理性能;然而,这完全取决于翻译的质量。在第一个例子中,孟加拉语的原句以讽刺的方式表达了负面情绪;GPT-4发现用孟加拉语理解它很有挑战性,因此产生了错误的分类。然而,当我们将其翻译成英语并且翻译质量相当好时,GPT-4能够正确地对其进行分类。在第二个例子中,尽管翻译在表面上看起来很好,但它忽略了原始印地语句子中潜在的固有负面情绪,导致了错误的预测。接下来的两种情况与单词混合技术有关。在这里,第一个讲的是一部电影中最糟糕的故事ভয়¿র (可怕)和েসরা উদাহরণ(很好的例子);GPT-4专注于错误的积极预测。尽管如此,当我们更换ভয়¿র 在“糟糕”的情况下,GPT-4会产生正确的结果。这种方法的一个问题是,我们在不考虑上下文的情况下,将原句中的任何单词替换为其翻译,有时会产生无意义的句子。下面的例子显示了这样一种情况,其中单词混合产生了一个不连贯的奥迪亚英语单词混合句子,而GPT-4无法预测任何内容。最后的例子对应于引用时使用GPT-4的隐式翻译。在这里,孟加拉语的原始句子产生了错误的预测,但当我们指示GPT-4在后台将孟加拉语句子翻译成英语,以防在推理时发现难以理解母语脚本时,它会产生正确的结果。为了澄清,我们并没有明确地推出翻译来减少输出令牌的生成;这只是为了验证和说明该技术的有效性。
5 结论
本文研究了使用领先的商业LLM GPT-4解决不同印度语言的五个分类数据集的成本。虽然GPT-4在这些任务上做得很好,但LRL单词变得高度碎片化,导致API调用的成本很高。本研究旨在保留GPT-4的性能优势,同时降低API成本。为此,我们尝试了不同的预处理技术,包括翻译、单词混合和音译。我们的研究发现,将整个LRL句子翻译成英语大大有助于降低成本,同时甚至提高性能(提供免费的MT系统将LRL翻译成HRL)。在没有这种MT系统的情况下,可以使用GPT-4甚至LRL-HRL字典隐式翻译来替换高度碎片化的单词以降低成本。在未来,我们希望更深入地探索wordmix,同时使用与源LRL相关的其他HRL。我们还计划专注于生成任务。
6局限性
尽管成本很高,但GPT-4被广泛认为比BLOOM(Scao et al.,2023)和GPT-neo等开源计数器部件提供了更好的质量。GPT-4经过比较,在包括文本处理和理解在内的多种应用场景中都优于BARD 3.出于这个原因,为了控制成本,我们只试验了一种商业LLM,GPT-4。尽管这将显著增加实验成本,但将其他付费LLM纳入实验设置将使我们的观察更加复杂。此外,我们的单词混合技术,即在不考虑句子上下文的情况下,将LRL单词与翻译一起重新放置,是粗糙的。它有时会影响句子结构。在考虑句子上下文的同时重读一个单词或短语会更合适。在这项工作中,我们只关注印度语言。尽管我们涵盖了多达15种语言,但一个直接的解释可以用来检验世界各地其他LRL的假设。此外,在任务方面,研究翻译或混词文本生成任务的效果可能会有进一步的发现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









