







 本文详细介绍了如何在MySQL中进行数据库备份与日志管理,包括使用mysqldump进行数据备份及恢复,以及数据库日志的概念和类型。同时,实验探讨了并发控制的四个隔离级别,如读未提交、读已提交、可重复读和可串行化,通过实例展示了它们在防止数据不一致问题上的作用。
本文详细介绍了如何在MySQL中进行数据库备份与日志管理,包括使用mysqldump进行数据备份及恢复,以及数据库日志的概念和类型。同时,实验探讨了并发控制的四个隔离级别,如读未提交、读已提交、可重复读和可串行化,通过实例展示了它们在防止数据不一致问题上的作用。
目录
一、备份与日志初步实验
1)了解你所使用的数据库平台的单表数据备份和整库备份方法,进行相应备份操作,并尝试利用备份数据在另一个机器上恢复数据,并在实验报告中描述上述过程。
在MySQL中使用mysqldump将数据库的单表数据以sql文件的形式存储起来,指令的格式如下图,为用户名,密码,数据库,表,存储文件的绝对路径。mysqldump指令需要在命令行窗口上直接运行,不需要进入mysql后运行。
mysqldump指令的格式:
mysqldump -u root -p --all-databses > 路径 ###备份所有数据库
mysqldump -u root -p -databases auth mysql > 路径 ###备份auth和mysql库
mysqldump -u root -p auth > 路径 ###备份auth数据库
mysqldump -u root -p mysql user > 路径 ###备份mysql的user表
mysqldump -u root -p -d mysql user > 路径 ###备份mysql库user表的结构
这里将bank整个数据库进行数据备份。
mysqldump -uroot -p bank > D:/bank.sql
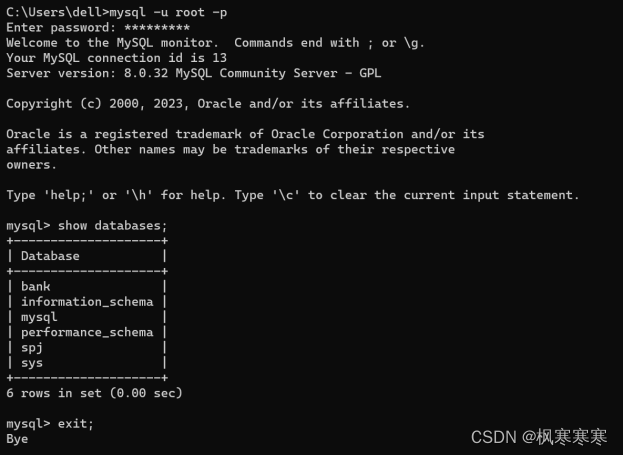

在相应的路径中出现了bank.sql文件。
里面是形成数据库bank的一系列sql语句,包括建表语句和数据插入语句等。数据恢复时,执行该文件中的sql语句即可。
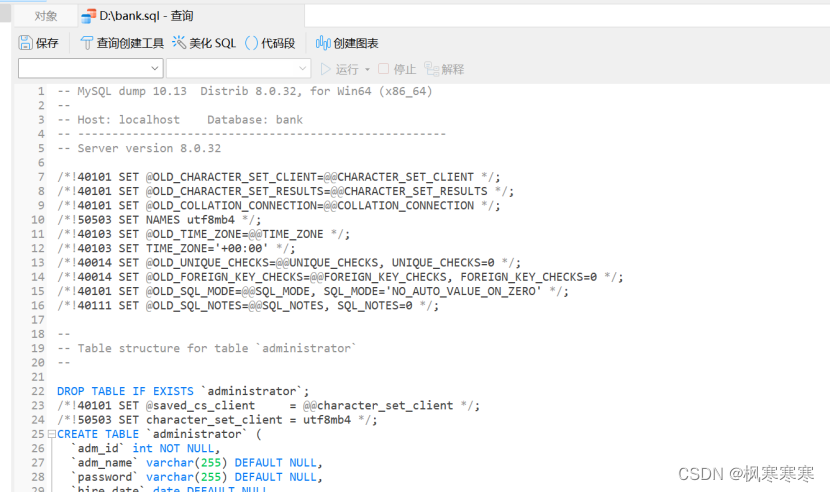
将administrator表删除。
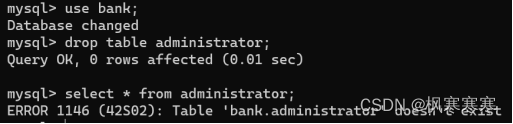
用source指令恢复数据。source指令需要进入mysql之后运行。
恢复成功。

值得一提的是在Navicat中可以直接进行数据的备份和恢复。
2)掌握数据库日志的概念,并说明数据备份、日志与故障恢复之间的关系。
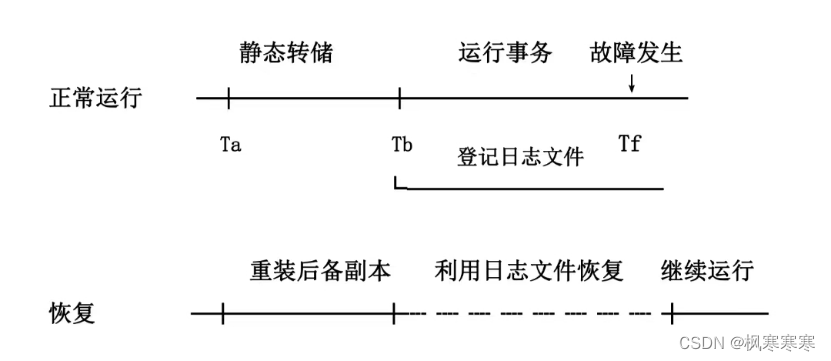
数据库日志概念:在数据库系统中,对数据的任何更新操作(如:增加、修改、删除),都要把相关操作的命令、执行时间、数据的更新等信息保存下来。这些被保存的信息就是数据库日志。也就是说,数据库日志是数据库系统中所有更新活动的操作序列。数据库日志是系统正常运行、保持数据一致性的重要手段。
数据备份、日志与故障恢复之间的关系:数据备份和日志都可以用于故障恢复。日志文件可以进行事务故障的恢复、系统故障的恢复以及协助后备副本进行截止故障恢复。
3)查阅资料,在你所使用的数据库中找到能记录数据修改操作的日志文件,针对某个表执行插入或修改操作,请在相应日志文件中找对应的插入或修改操作日志记录,至少解释其中的一条日志数据样例。
MySQL中一般有以下日志文件,分别是:
错误日志:log-err (记录启动,运行,停止mysql时出现的信息)
二进制日志:log-bin (记录所有更改数据的语句,还用于复制,恢复数据库用)
查询日志:log (记录建立的客户端连接和执行的语句)
慢查询日志: log-slow-queries (记录所有执行超过long_query_time秒的所有查询)
更新日志: log-update (二进制日志已经代替了老的更新日志,更新日志在MySQL 5.1中不再使用)
使用以下命令:
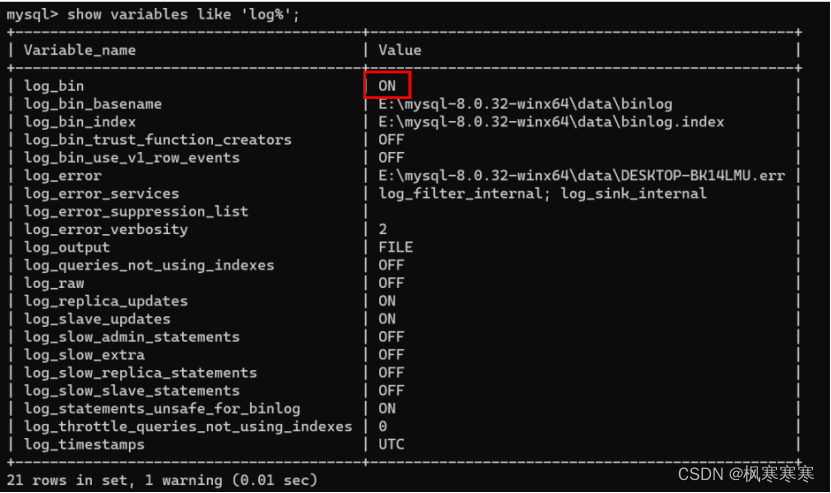
show variables like 'log%';(是否启用了日志)
mysql> show master status;(查看当前的日志文件名)
 对bank数据库的bank表进行更改:
对bank数据库的bank表进行更改:

使用指令:
mysqlbinlog.exe --no-defaults --base64-output=decode-rows -v E:\mysql-8.0.32-winx64\data\binlog.000036 > D:/test.txt
将二进制日志文件存储为test.txt,其中-v 后面是日志文件地址,>后面是输出日志的文件目录。
查看test.txt文件的最后几行:
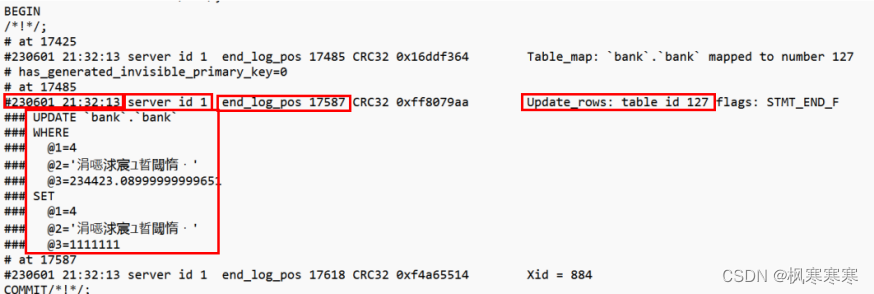
上方红框分别表示:时间、服务器id、此事务在日志中的结束位置、更新的表id、更新指令。在更新指令中,虽然在sql语句中只输入了一个条件,即bank_id=4,但是在日志中会显示出这条数据更改前的全部信息,也会显示出更改后的全部信息。也就是日志中不仅存储了该事务更改的这条数据的更改后的信息,也存储了更改前的信息,可用于故障的恢复。
二、 并发控制实验
1)通过取消所用DBMS的查询分析器的自动提交功能,创建两个不同用户,分别登录查询分析器,同时打开两个客户端;
查看MySQL的自动提交功能情况,发现自动提交已打开:
show variables like 'autocommit';
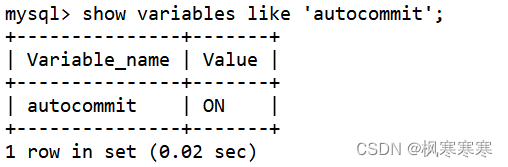
关闭自动提交功能并且再次查看自动提交功能情况:
set autocommit=0;

创建两个新用户,赋予他们bank数据库的所有权限:

同时打开两个客户端:
注意:在user_1和user_2的客户端都应重新检查autocommit属性是否开启。
使用指令
show variables like 'autocommit';
set autocommit=0;
查看并关闭。
2)通过SQL语言设计具体例子展示不同隔离级别的应用场景,验证各种隔离级别的并发控制效果,即是否存在并发操作带来的数据不一致问题,包括丢失修改、不可重复读和读“脏”数据等。
四级隔离级别:
读未提交(read uncommitted):
对应一级封锁协议,即事务T在修改数据R之前必须加X锁,直到事务结束才释放。可以防止丢失修改,不能保证可重复读和不读脏数据。
读已提交(read committed):
对应二级封锁协议,即在一级封锁协议基础上,增加事务T在读取数据R之前必须先对其加S锁,读完就可释放S锁。可以防止丢失修改和读脏数据,但是不保证可重复读。
可重复读(repeatable read):
对应增强的二级封锁协议,即在一个事务内,多次读同一个数据,在这个事务还没结束时,其他事务不能访问该数据(包括了读写),这样就可以在同一个事务内两次读到的数据是一样的,因此称为是可重复读隔离级别,读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务(包括了读写),这样避免了不可重复读和脏读,但是有时可能会出现幻读。
可串行化(serializable):
对应三级封锁协议,即在一级封锁协议的基础上,增加事务T在读取数据R之前必须对其加S锁,直到事务结束才释放。它要求事务串行化执行,事务只能一个接着一个地执行,但不能并发执行,如果仅仅通过“行级锁”是无法实现序列化的,必须通过其他机制保证新插入的数据不会被执行查询操作的事务访问到。序列化是最高的事务隔离级别,同时代价也是最高的,性能很低,一般很少使用,在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻读。
-
读未提交(read uncommitted):
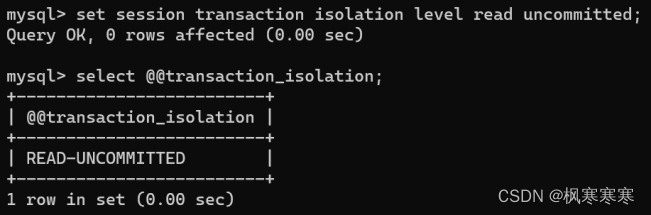
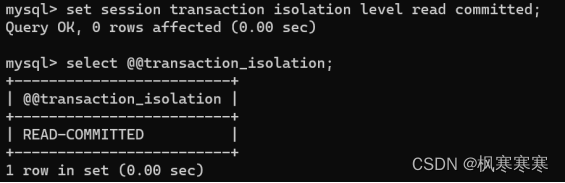
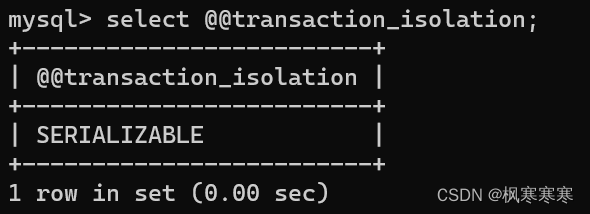
设置为read uncommitted并查看。
set session transaction isolation level read uncommitted;
select @@transaction_isolation;
注意:两个用户的客户端都需执行更改隔离级别的命令。
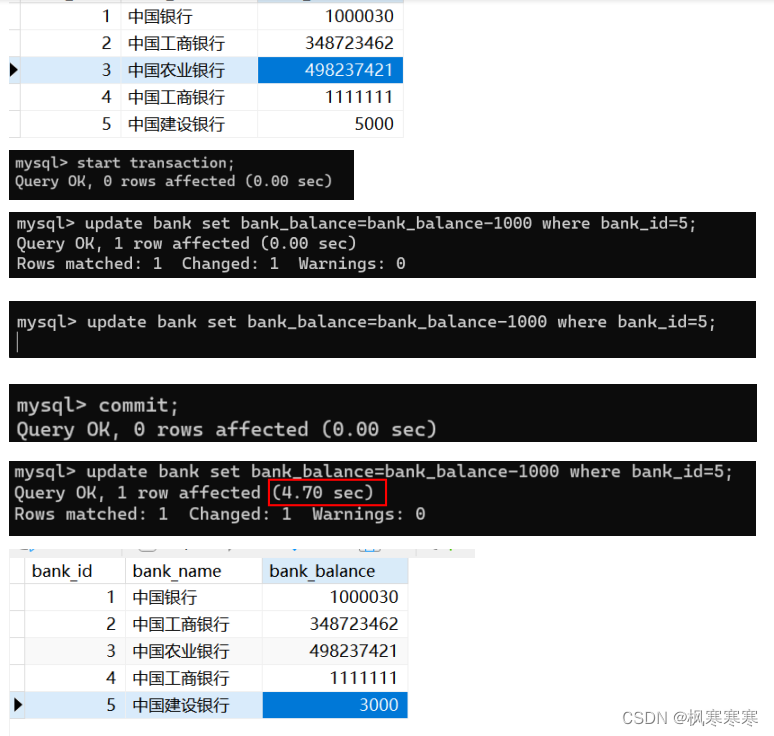
(1)丢失修改验证:
user_1和user_2对bank中bank_id为5的数据,bank_balance做-1000操作。
user_1正常执行完,但没有自动提交,user_2在等待user_1提交后解锁才能修改数据。说明read uncommitted情况下不会发生丢失修改。
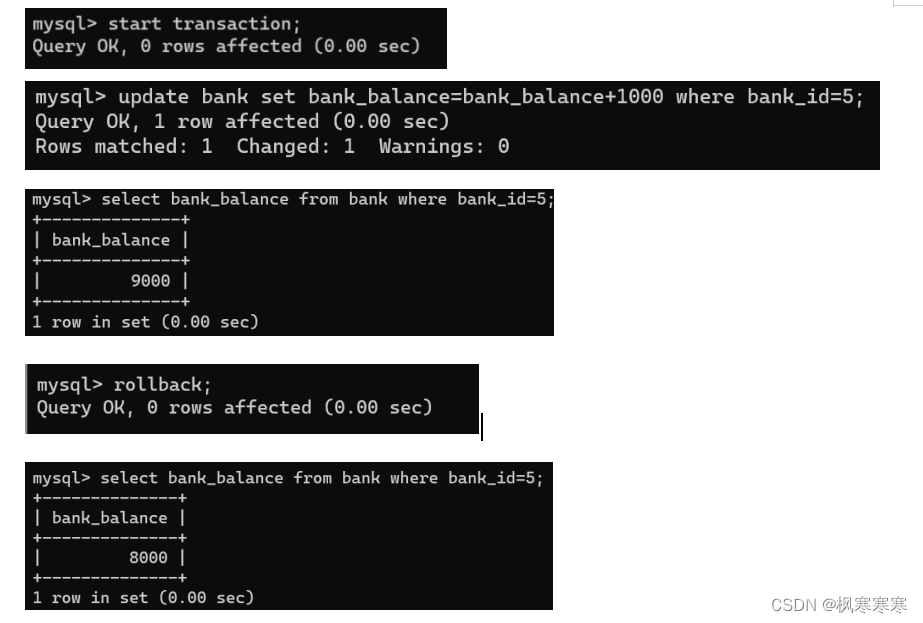
(2)读脏数据验证:
user_2对bank_id为5的数据的bank_balance做+1000操作。
user_1读这条数据。
user_2 rollback。
user_1再次读这条数据。
user_1第一次读取到的数据是9000,是做过+1000后的数据,但是还未提交,是脏数据。
第二次读到的数据是8000,是rollback后的数据。说明read uncommitted情况下不保证读脏数据不会发生。
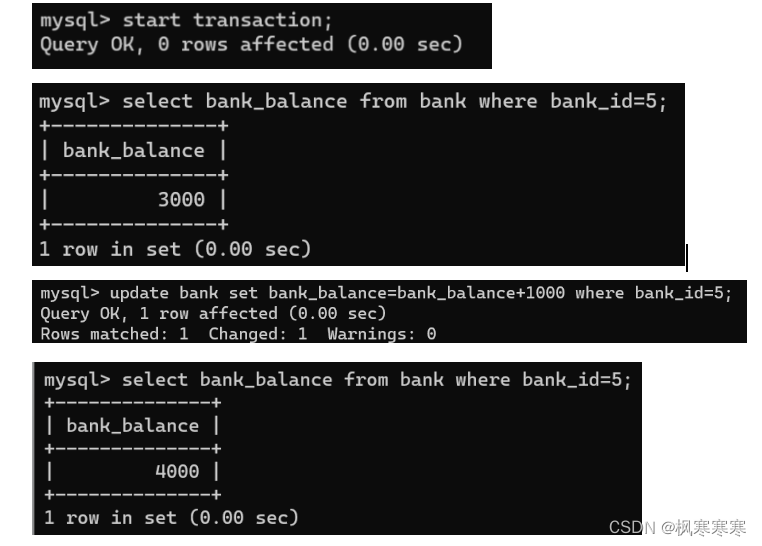
(3)不可重复读验证:
user_1读数据bank_id为5的数据的bank_balance。
user_2对该数据做+1000操作并提交。
user_1再次读这条数据。
user_1在一次事务中两次读取的数据不一样。说明read uncommitted情况下不保证不可重复读不会发生。
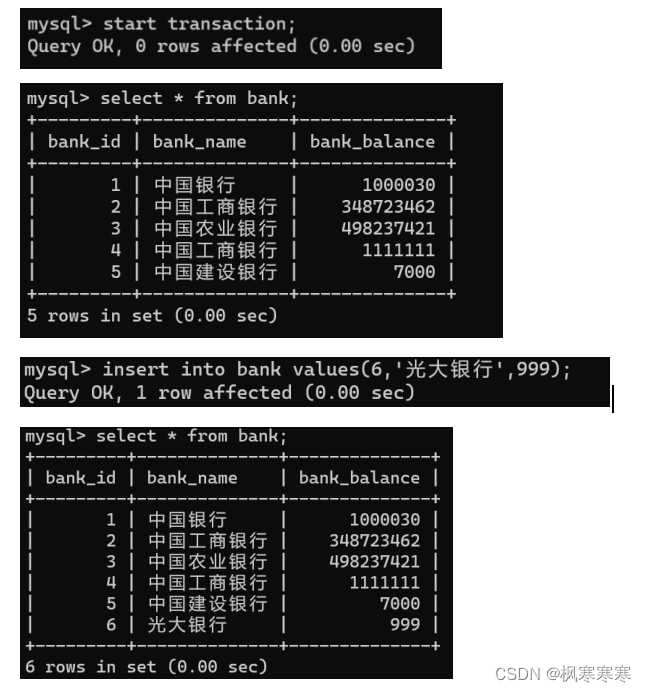
(4)幻读验证:
user_1读bank表所有数据。
user_2对bank表添加数据(6,光大银行,999),提交。
user_1再次读bank表中所有数据。
use_1第一次查询时没有光大银行的数据,user_2添加数据并提交后,user_1查询到了光大银行的数据。说明read uncommitted情况下不保证幻读不会发生。
以类似的测试方法,测试验证其他的隔离级别。下面不再一一赘述。
-
读已提交(read committed):
(1)丢失修改验证:
结果与read uncommitted相同。read committed不会发生丢失修改。
(2)读脏数据验证:
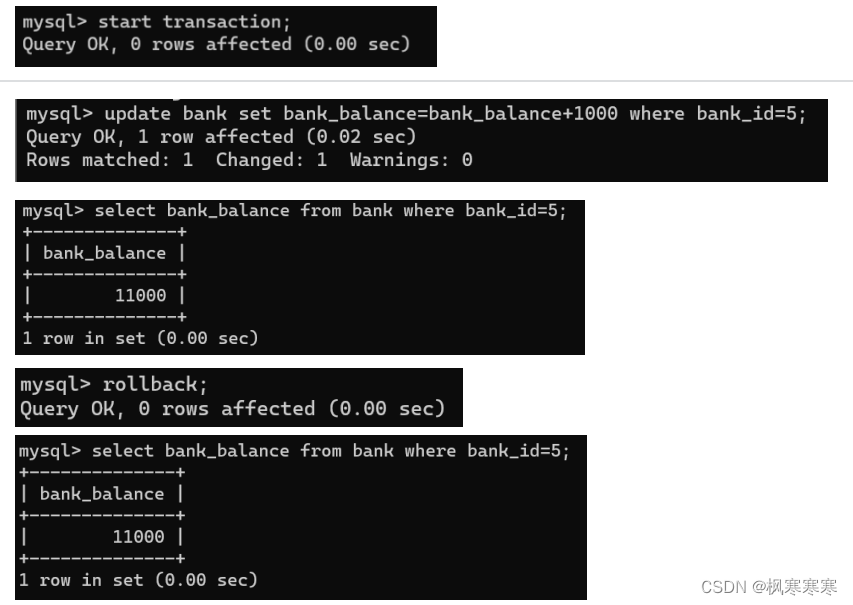
两次读取的数据一样,不会发生读脏数据的情况,在read commit情况下,只有修改该数据的事务被提交后,其他事务才可以读取更改后的数据。
(3)不可重复读验证:
与read uncommitted结果相同。在同一个事务中,两次读取数据不一样,因此read commit也不能保证可重复读。
(4)幻读验证:
与read uncommitted结果相同。在同一个事务中,两次读取的数据条数不同,说明在read commit情况下,不能保证不出现幻读。
-
可重复读(repeatable read):
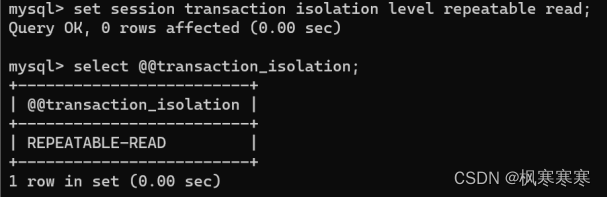
(1)丢失修改验证:
结果与read uncommitted相同。Repeatable read不会发生丢失修改。
(2)读脏数据验证:
结果与read committed相同两次读取的数据一样,在repeat read情况下,不会发生读脏数据。
(3)不可重复读验证:
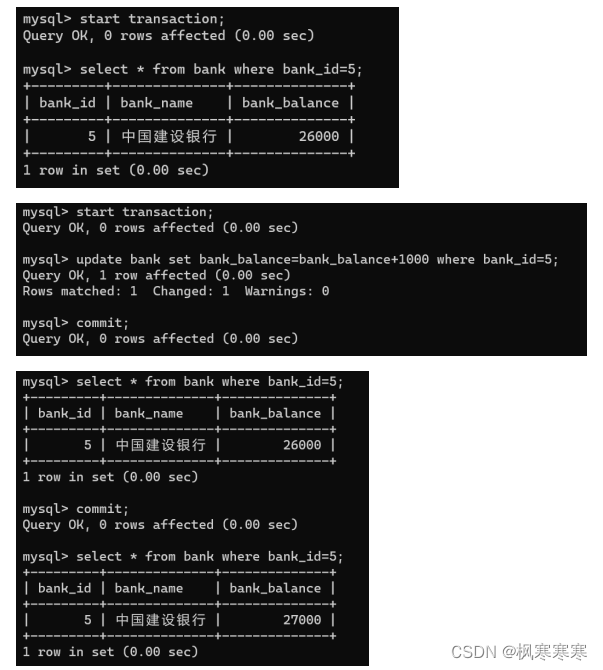
User_2读数据,user_1改数据并提交,user_2再次读数据,读取的数据是未更改的数据,user_2提交后结束事务,再次读数据,此时读到的才是修改后的数据。说明在repeatable read情况下,可以保证可重复读。
(4)幻读验证:
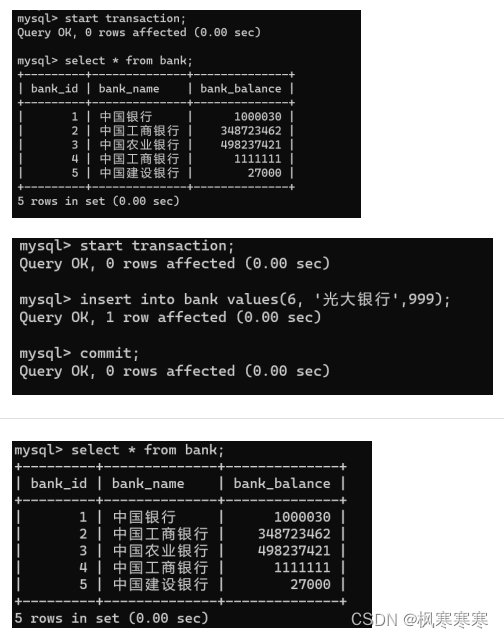
user_2的事务插入数据前后,user_1的事务查询都是一样的。似乎没有出现幻读现象。
但是可重复读中其实只是在读数据的时候解决了幻读问题,而在其他情况下依旧会出现幻读错误。
比如在user_1中虽然读不到bank_id=6的数据,但是可以更改bank_id=6的数据。

在事务提交后,再次查询,是更改后的数据。
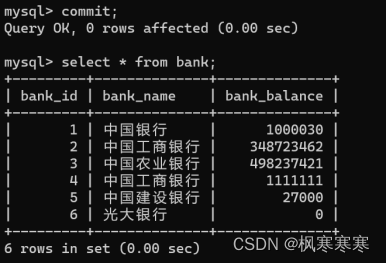
所以在repeatable read情况下,严格意义上的幻读现象不能够避免。
-
可串行化(serializable):
(1)丢失修改验证:
结果与read uncommitted相同。在serializable情况下,不会发生丢失修改。
(2)读脏数据验证、不可重复读验证、幻读验证:
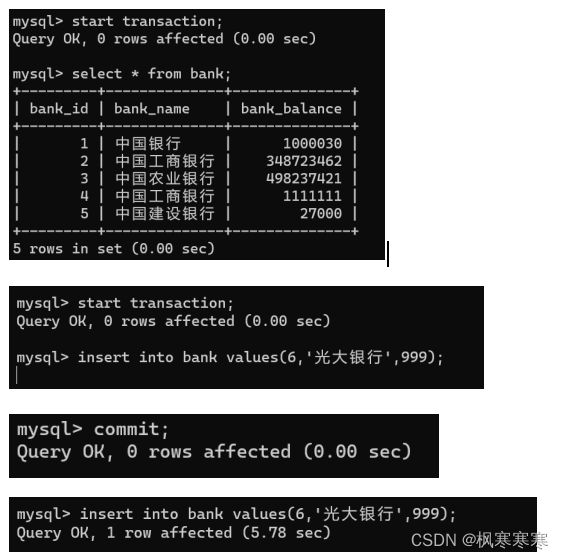
user_2的事务读数据,user_1的事务插入数据,但是user_2的事务没有完成,user_1必须等待,直到user_2事务完成才能插入数据。事务只能串行处理从根本上杜绝了丢失修改、读脏数据、不可重复读、幻读的问题。但也失去了数据库操作的并行性,极大的影响效率。
| 隔离级别 | 丢失修改 | 读脏数据 | 不可重复读 | 幻读 |
| Read uncommitted | 解决 | 不解决 | 不解决 | 不解决 |
| Read committed | 解决 | 解决 | 不解决 | 不解决 |
| Repeatable read | 解决 | 解决 | 解决 | 不解决 |
| Serializable | 解决 | 解决 | 解决 | 解决 |



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











