







1.1 整体技术方案
为建设统一的数资源中心,加强数据资源整合:制定相关标准规范及管理制度,通过相应平台工具汇聚区内各单位公共数据及市级落地数据资源,形成数据池,同时经过数据清洗、转换、融合、治理后高质量的公共数据资源,形成数据资源中心。本次项目完善公共数据逻辑模型、物理模型的设计规范并确定公共数据库存储原则基层上,利用中心所建设的平台工具对进入市级数据湖的数据进行清洗、分层与转化,形成市级数据库。并完成对人口、法人、空间地理库数据资源的整合开发,实现对人口、法人、空间地理信息的接入、整合、开发、利用,结合H市实际,构建公共主题库,为应用提供安全高质的公共数据服务。
本次公共数据存储模型设计实施项目的框架如下图所示:
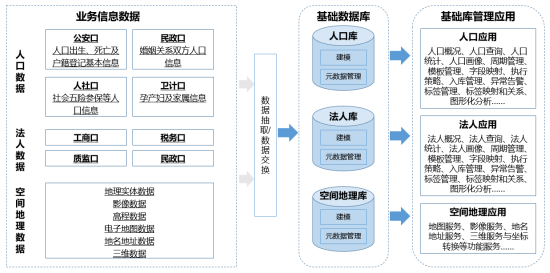
(1)业务信息数据整合
整合政务数据(国家、市级、区)、公共事业数据、行业数据(金融、电信)、物联网数据(气象、摄像头…),实现内外部数据融合。
l采集人口数据:通过公安口、民政口、人社口、卫计口等来源数据,采集人口出生、死亡、婚姻、社保、户籍等信息。
l采集法人数据:通过工商口、税务口、质检口、民政口等来源数据,采集法人登记、税务、工商登记等信息。
l采集空间地理数据:采集地图、街道、区域、小区、楼宇、景点等地名、类型、经纬度等信息。
(2)数据抽取/数据交换
数据采集模块采用集中化多租户ETL平台进行数据采集、转换、稽核工作,完成数据标准化、集中化,实现数据脉络化、关系化,实现统一的数据处理加工,包括:离线采集、实时采集、准实时采集、流媒体采集、数据导入上报。
(3)基础库
按照人、地、事、物、组织等对象方式对数据进行建模,形成全区统一共用的基础数据库。典型的基础数据库包括人口库、法人库、空间地理信息库。
l人口库:构建全市统一的、以公民身份号位为唯一标识的、可共享的综合人口信息资源库。基于综合人口库,实现全市人口信息的汇聚治理、共享交换和应用服务,为开展跨部门、跨业务、跨区域的人口应用服务和数据共享,以及人口大数据分析、辅助决策等,提供全方位的人口信息支撑。
l法人库:促进相关部门有关法人单位业务信息的关联汇聚,丰富法人单位信息资源。支撑法人单位信息资源的分布查询和深化应用。通过公共数据开放网站,分级、分类安全有序开放综合法人信息,促进社会化创新应用。
l空间地理库:基于规划、国土资源等部门提供的GIS地图服务基础上,构建自然资源和空间地理基础信息,并将遥感影像、地址数据、政务信息图层等,与人口信息、法人单位、宏观经济、社会信用进行整合,形成本市空间地理基础信息资源库,为全市政府部门和企事业单位提供统一的地理空间信息服务。
1.2 模型设计思路及规范
1.2.1 数据模型分层设计
对数据模型进行分层能对管理数据有一个更加清晰的掌控,主要有体现清晰数据结构、数据血缘追踪、减少重复开发、复杂问题简单化、屏蔽原始数据异常、屏蔽业务的影响。
每个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。便于维护数据的准确。
本次建设公共数据模型从层次上分为ODS、DW与ST层,即:数据运营层、数据仓库层和数据应用层。
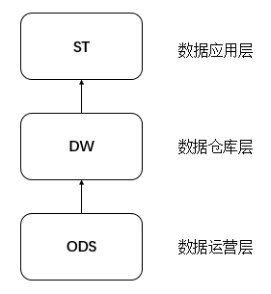
ODS层数据为近源层数据,数据源中的数据,经过ETL抽取、洗净、传输之后,装入本层。在源数据装入这一层时,要进行诸如去噪、去重、提脏、业务提取、单位统一、砍字段、业务判别等多项工作。
DW层数据为数据仓库层数据,ODS层数据经过整合,针对不同实体进行汇总后的数据进入该层。
ST层为数据应用层,数据更灵活,更贴近实际应用,用于数据展现。
1. 数据来源层→ODS层
数据主要会有两个大的来源:
(1)业务库,使用sqoop来抽取,每天定时抽取一次。在实时方面,考虑用canal监听mysql的binlog,实时接入。
(2)埋点日志,线上系统会打入各种日志,日志以文件的形式保存,选择用flume定时抽取,或spark streaming、storm来实时接入,kafka也会是一个关键的角色。
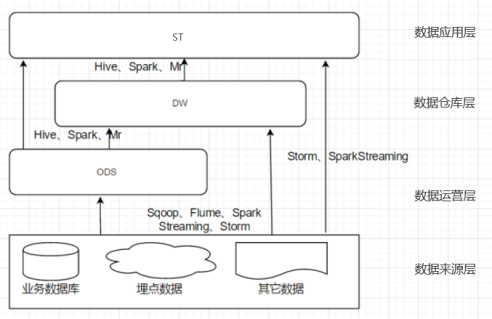
在ODS层中要进行数据清洗,比如异常字段的处理、字段命名规范化、时间字段的统一等。
2. ODS层→DW层
通过对ODS层数据进行整合,设计通用的数据仓库层,减少数据模型冗余度。规范仓库层模型,将有效提升数据模型重用度,好的DW层模型可以大大提升运营效率和数据一致性。
3. DW→ST层
ST层为数据应用层,将DW层数据根据不同需求进行多维度汇总、统计,对数据完成汇总、切片、钻取统计,为不同场景设计数据应用层模型。
1.2.2 数据模型分域设计
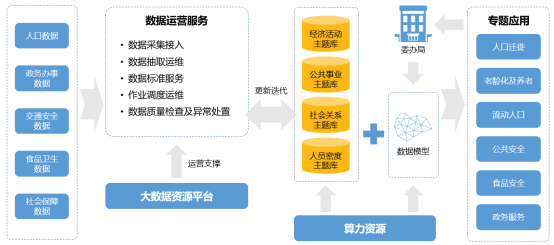
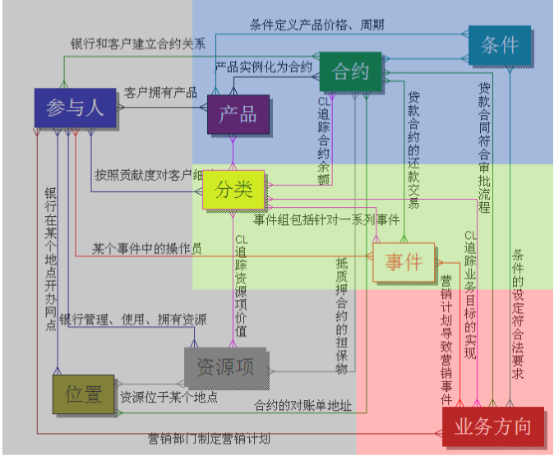
数据仓库中的数据是面向主题组织的,主题是在较高层次上将企业信息系统中的数据进行综合、归类和分析利用的一个抽象概念,每一个主题基本对应一个宏观的分析领域。公共数据库资源模型设计分域情况如下:
| 主题域 | 主题域缩写 | 相关内容 |
| 人口域 | PRTY | 个人基本信息 |
| 法人域 | GRP | 法人基本信息 |
| 事件域 | EVT | 出生、死亡、诉讼 |
| 资源域 | RES | 空间资源、服务资源、公共资源、网络资源 |
| 账务域 | ACC | 消费记录、纳税记录 |
| 关系域 | REL | 就职记录、婚姻关系 |
根据对人口、法人、空间地理库数据信息的特征,将对人口、法人、空间地理结合H市实际,构建数据模型三大公共主题域,为应用提供安全高质的公共数据服务。
人口主题域:收集城市各职能局的业务数据,对数据进行清洗、比对、关联,获得人口空间数据,建立人口库数据资源。
法人主题域:收集城市各职能局的业务数据,对数据进行清洗、比对、关联,获得法人空间数据,建立法人库数据资源。
资源主题域:通过收集城市各职能局的空间地理资源,结合业务数据,对数据进行清洗、比对、关联,获得空间地理数据,建立空间地理库数据资源。
主题域通常是联系较为紧密的数据主题的集合。可以根据业务的关注点,将这些数据主题划分到不同的主题域(也说是对某个主题进行分析后确定的主题的边界。)
模型设计示例如下:
1.2.3 物理模型设计
依据数据仓库建模理论,结合实际经验,物理模型设计时需确定数据模型在分布式系统中的存储形态,综合考虑Hadoop、MPP、一体机数据库、内存数据库四种形态各自特点,结合数据按照粒度不同、周期不同、主题不同形成的数据热度,制定数据的存储分布。
1.2.3.1 分表规则
根据情况,将公共数据模型按照如下规则进行设计:
| 表命名 | 类型名称 | 说明 |
| YYYYMMDD | 日表 | 存放当天数据 |
| YYYYMM | 月表 | 存放月末数据,或当月累计数据 |
| DM | 多周期日表 | 存放多个周期的日数据 |
| DM_YYYYMM | 多周期日表累计的月表 | 存放多个周期的日数据,每月分表 |
| DM_YYYY | 多周期日表累计的年表 | 存放多个周期的日数据,每年分表 |
| MM | 多周期月表 | 存放多个周期的月数据 |
| DS | 当周期表 | 当周期最新的数据 |
| DT_YYYYMMDD | 累计日表 | 当月累计数据 |
1.2.3.2 表命名规则
基于分主题分层的原则命名:层_主题域_表名_表类型_分表规则
例如:
人口表 DWD_PRTY_INDIV_YYYYMMDD
法人表 DWD_PRTY_GRP_YYYYMMDD
1.2.3.3 字段命名原则
为了保证数据定义和数据自身质量,以提高处理效率,字段设计建议遵循以下原则:
l相同字段设计命名一致性,对于多个表均有的字段,设计为统一的名称
l对于表间关联常用的字段,各表应该设计成同样的字段类型。
l避免对Hash键值字段进行数据的处理。
| 字段名称 | 字段命名 | 字段类型 | 枚举值 |
| 个人姓名 | INDIV_NAME | VARCHAR(32) | |
| 个人证件号码 | INDIV_CERT_CODE | VARCHAR(32) | |
| 个人证件类型 | INDIV_CERT_TYPE | INT | 0身份证;1工商登记证;10港澳居民来往内地通行证;11台胞;12外籍人士;13个体工商户营业执照;14聚类;15特殊客户;3军人证;5企业代码证;9单位证明;99其它证件 |
| 个人证件地址 | INDIV_CERT_ADDRESS | VARCHAR(256) |
1.2.3.4 数据处理原则
对于数据加工处理,应该尽量在小表内进行,对于局部的数据加工处理为了不影响基础大表,应建立临时表作为工作空间。
对于年汇总、月汇总等粗粒度类数据汇总处理,应该在基于事先建立的日汇总等低粒度结果(包括用户、产品等维度上汇总)基础上进行,这种处理可减少上级统计对明细层数据的重复性读取。
1.2.4 逻辑模型设计
逻辑模型设计是对概念模型设计的进一步细化,根据数据的产生频率及访问频率等因素综合考虑,确定数据热度和数据关系等规则。作为概念模型到物理模型转换的中间过程,逻辑模型设计时兼顾业务理解和系统实现。
1.2.4.1 数据有效性策略
模型中设计的字段属性都应是具有分析价值的,对于无效性字段属性,应予以裁剪:
剔除:对源系统提供的仅用作生产使用,无分析价值的字段属性进行剔除;对源系统中的无效字段(如全为空值、全为Z等)进行剔除。
合并:对内容重复,同名异义、同义异名、同名同义不同值、反复存储的字段信息进行归并。
1.2.4.2 数据关系定义
概念模型设计的字段属性,与源系统相应实体的字段属性存在一定的映射关系,在逻辑模型设计时,应建立与源系统字段定义间的映射关系定义。通常的映射关系有:
源系统单张表,在概念模型设计时也为单个模型的,应针对概念模型中每个字段,建立其对应的源系统字段属性映射;
源系统多表,在概念模型设计时合并为单个模型,需要针对每个数据源表与当前模型分别映射,且每个模型的每个字段属性都应有相应的映射关系;
源系统单张表,在概念模型设计时拆分为多个模型,需将每个模型与源系统的标进行分别映射,且每个模型的每个字段属性都应有相应的映射关系。
1.2.4.3 维值定义规则
统一采用维表方式定义静态的维值,例如证件类型,用户状态等字段。
| 维值 | 维值名称 | 枚举值 | 枚举值中文 | 生效时间 | 失效时间 |
| CERT_TYPE | 证件类型 | 0 | 身份证 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 1 | 工商登记证 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 10 | 港澳居民来往内地通行证 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 11 | 台胞 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 12 | 外籍人士 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 13 | 个体工商户营业执照 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 14 | 聚类 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 15 | 特殊客户 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 3 | 军人证 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 5 | 企业代码证 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 9 | 单位证明 | 1900/1/1 | 2099/1/1 |
| CERT_TYPE | 证件类型 | 99 | 其它证件 | 1900/1/1 | 2099/1/1 |
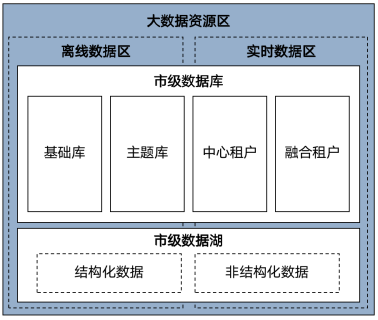
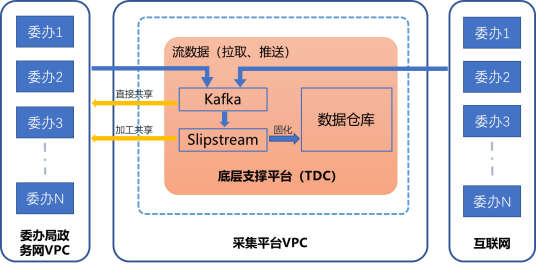
1.3 人口库法人库数据采集
1.3.1 数据采集执行过程
本项目需采集的数据分为两部分,数据湖中的人口数据和法人数据。
数据采集方式有两种:
u通过数据数据湖中的数据需要经过一系列治理后,形成高质量的数据入库。
u通过各部门政务应用系统与数据资源池的直接双向交互,无需通过数据湖进行中转,通过平台的调度引擎可进行交换链路的灵活设置。
抽取流程如下图:
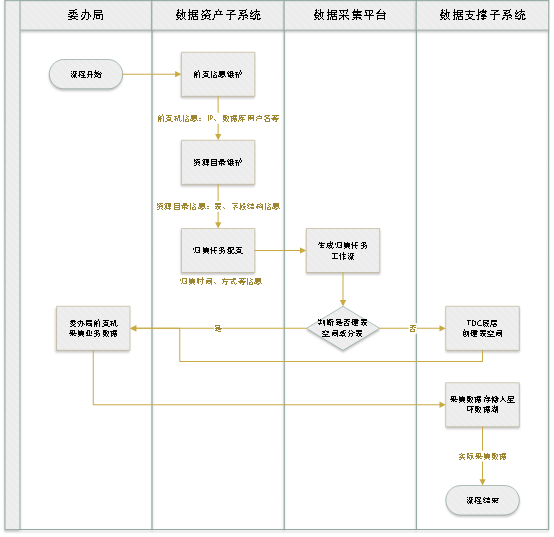
为适应大数据中心多类型数据源采集的需要,事件数据需支持多种类型的数据采集方式,数据采集可采用多种丰富的数据源接口,包括:
l常用标准协议接口如Socket等
lFTP文件接口
lJDBC/ODBC接口
l消息队列(KAFKA)接口
lHadoop生态圈的开源技术Flume
1.3.1.1 数据抽取方式
数据抽取主要采用自动采集的方式,支持全量抽取和增量抽取。
l全量抽取:数据湖或源系统的某个数据表或文件,全量进行抽取。
l条件抽取:数据湖或源系统的某个数据表或文件,可根据预设条件进行数据抽取
l增量抽取:监测数据湖或源系统的某个数据表或文件,仅针对增量部分进行抽取。
源数据库支持如下三种方式,根据需要进行抽取:
n文件
n数据库
n流数据
市级数据湖归集的数据处理办法:
(1)批数据处理:
各类批数据通过数据采集功能进入数据支撑平台,经过存储、清洗、汇总和关联汇总等,产生应用数据,并实现数据共享或开放。
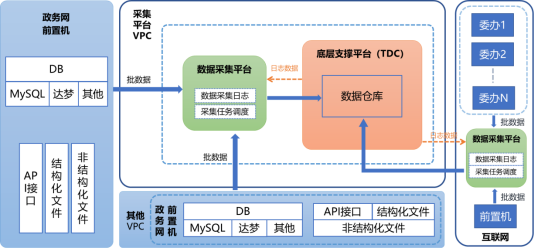
(2)流数据处理:
流数据通过数据采集功能进入数据支撑平台后,根据不同需求,可实现实时数据计算后的开放,也可实现通过实时数据分析后汇总产生应用数据,进而实现数据共享或开放。
1.3.1.2 自动入库
从数据湖和特殊应用的数据库自动采集法人数据,使用中间数据库的方式接收源端(数据湖等)按照要求提供的数据,当系统时钟到预设的自动读取中间数据库时间时,计算机自动读取中间数据库中的数据,也可以手工启动读取数据。调度可设置前置条件及时间调度方式,自动入库时间调度方式:
关注我的技术公众号,每个工作日都有优质技术文章推送和电子版方案下载。
微信扫一扫下方二维码即可关注:

文件下载地址:https://download.csdn.net/download/llooyyuu/88025749
知识星球文档下载地址:
https://t.zsxq.com/0fYlHQZEC


















 1577
1577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











