







在讲串匹配之前,我们要弄清楚两个概念:
S串 模式串:被匹配的主串
T串 目标串:子串
1.一般算法
在讲KMP算法之前,老师们都会给我们讲我们一般人能够想到的算法:
int Index(SString S,SString T,int pos)
{
i= pos;j=1 ;//pos表示从S串的第pos个位置开始与T串匹配
while(i<=S[0 ]&&j <=T[ 0]){
if (S[i]==T[j]){++i; ++j;}
else{i=i-j+2;j=1;}
}
if(j>T[ 0]) return i-T[0];
else return 0 ;
} //Index
当目标串与模式串出现不匹配的字符时,下一次匹配的就是目标串匹配起始位置的下一个位置
初始匹配位置位S[1]与T[1]
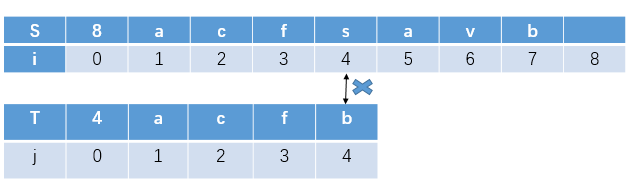
匹配到S[4],T[4]发生失配,
下一次匹配位置为S[2]与T串的起始T[1]
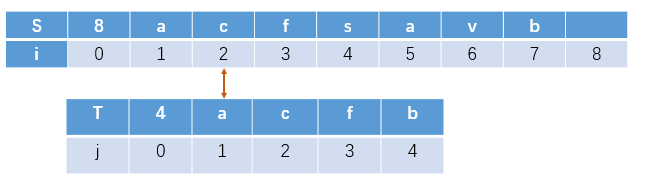
虽然这样的算法易懂,但是存在着巨大的缺陷,S串与T串前部相同码越多,发生失配后移动的位置就越多,效率越低
于是就出现了我们的KMP算法来解决这个缺陷
2.KMP算法思想
简介:
KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特—莫里斯—普拉特操作(简称KMP算法)。
KMP算法的精髓:next数组
KMP算法的要点:发生失配后只动模式串
所谓next,字面意思就是下一个,当S[m]与T[n]失配后,就让S[m]与T[next[n]]匹配
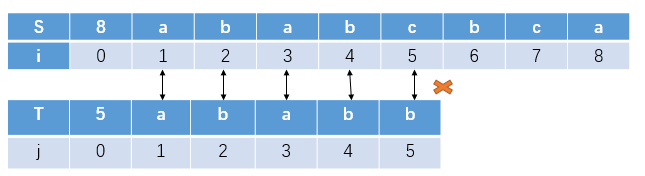
我们知道了S[1]~S[4] = T[1]~T[4]
又S[1]~S[2] = S[3]~S[4] = T[1]~T[2] = T[3]~T[4]
不考虑T[5],我们下一次的匹配模式串最优的移动方式是什么呢?
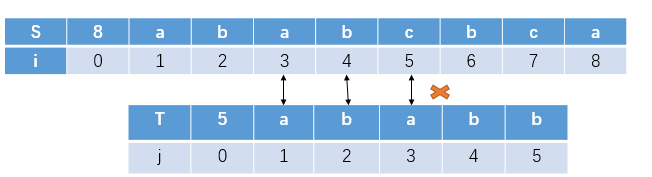
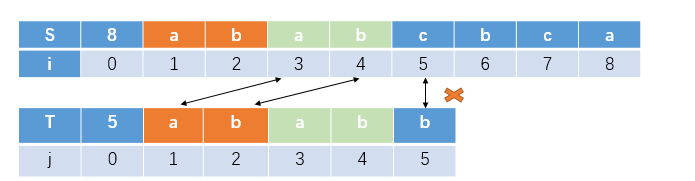
继续下一次:
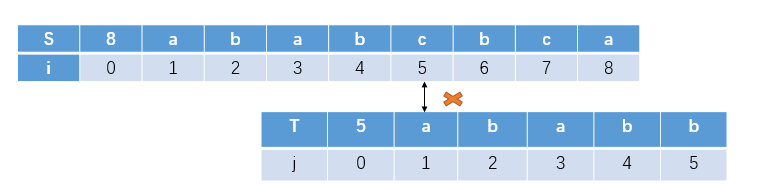
通过这个例子:我们可以看到只要模式串与目标串已匹配部分有相同的两部分,模式串下一次的匹配就是相同的子串的下一个字符
所以next的计算方式就是看当前字符的前一段字符,是否有对应相同的两段子串
注意:第一段子串以模式串第一个字符开头,第二段子串以当前字符的前一个字符结束
next = 相同字符数+1
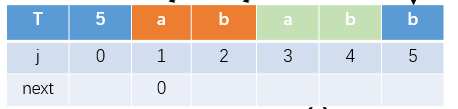
因为T[1]前无字符,故没有相同字符串,next为0
T[1]对应的next为0
就是当S串与T串第一个字符就不相同时

模式串的第0个位置与失配位置对应,但不是T[0]与S[1]比较,而是T[1]与S[2]比较

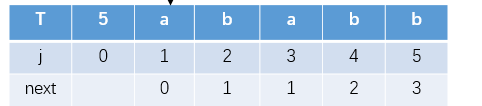
当遇到不匹配,就跳转到next对应的下标位置
例如:

可是,这里就出现了一个特殊情况:
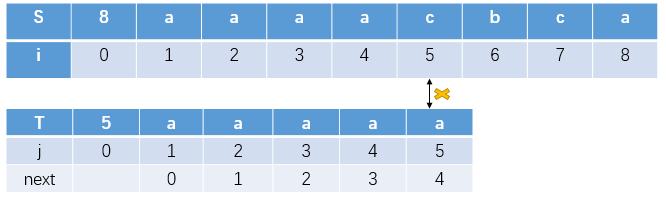
当你的T[5]与S[5]失配后,next是4,T[4]=T[5],肯定与S[5]不匹配,于是继续跳,我们最后发现,这样跳啊跳,最后我们的位置变到了0,可是,我们既然知道失配后跳转的位置依旧失配,我们为何不调整next,让他跳转的步骤少一点呢?
于是,next数组就可以修正为:

这样,我们的算法的时间复杂度就更小了
int Index KMP(SString S, SString T, int pos) {
//利用模式串T的next函数求T在主串S中第pos个
//字符之后的位置的KMP算法。其中,T非空,
// 1<=pos<=StrLength(S)
i= pos;j= 1;
while (i<= S[0] &&j<= T[0]) {
if(j==0|lS[i]= T[j]){ ++i; ++j; }
//继续比较后继字行
elsej = next[j];
//模式串向右移动
}
if(j> T[0]) return i-T[0]; //匹配成功
else return 0;
} // Index KMP
求next算法:
void get. next(SString T, int next[ ]) {
//求模式串T的next函数值并存人数组next。
i=1;
next[1] = 0;
j=0;
while (i < T[0]) {
if(j==O||T[i]==T[j]){++i; ++j;next[i]=j;}
else j = next[i];
}// get_ next















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









