







文章目录
简介
PySlowfast 是 FAIR 开源的基于 PyTorch 的视频理解代码库,让研究者可以轻而易举地复现从基础至前沿的视频识别 (Video Classification) 和行为检测 (Action Detection) 算法。
论文:SlowFast Networks for Video Recognition

本文系统为Windows,装起来还是挺痛苦的,建议使用Linux系统
本人使用的显卡为MX350显存2GB,配好了,跑不动hhh
Linux搭建环境可参考这篇文章
安装
1. Python
Python版本 ≥ 3.8
2. CUDA和cuDNN
参考 这篇文章
3. PyTorch
安装PyTorch>=1.7
进入官网选择版本后执行命令,安装PyTorch同时要安装torchvision

如本人显卡为MX350,CUDA为11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
4. Python库
pip install fvcore
pip install simplejson
pip install psutil
pip install opencv-python
pip install tensorboard
pip install moviepy
pip install pytorchvideo
pip install sklearn
pip install pandas
5. PyAv
下载 ffmpeg ,关键词:win64-gpl-shared
解压到C盘并将文件夹重命名为:ffmpeg
添加环境变量Path:C:\ffmpeg\bin
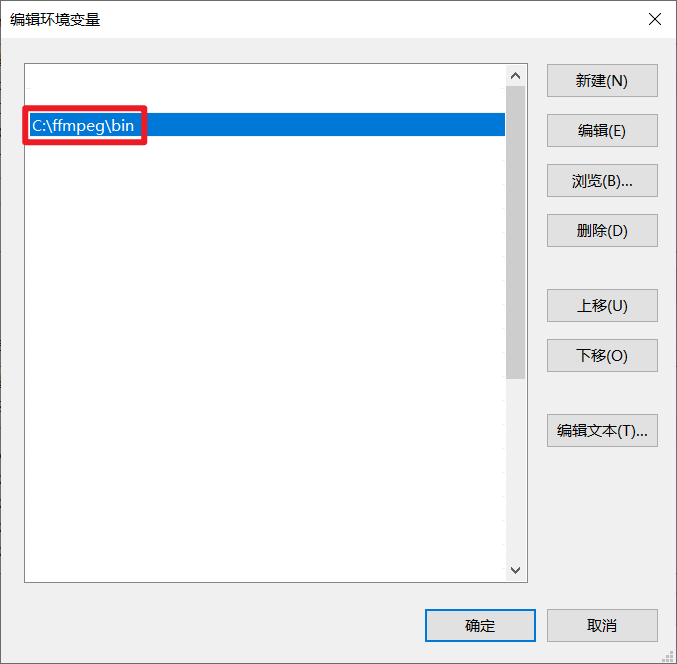
安装 PyAv
pip install av
import av
container = av.open('1.mp4')
for frame in container.decode(video=0):
frame.to_image().save('frame-%04d.jpg' % frame.index)
6. gcc 和 g++
gcc 和 g++ 是由 GNU 开发的 C 和 C++ 编程语言编译器
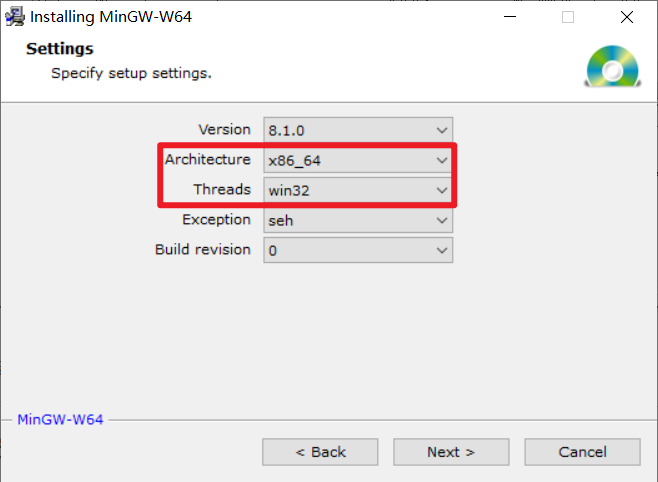
下载 MinGW-W64 并安装,记住安装路径如 C:\mingw-w64
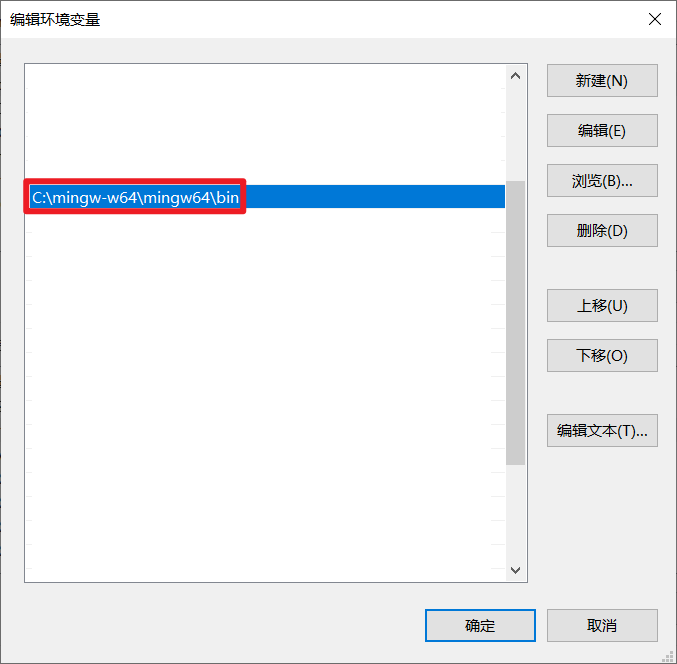
添加环境变量 Path:C:\mingw-w64\mingw64\bin
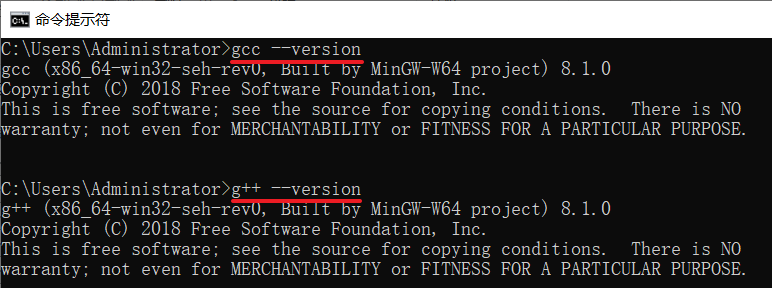
查看版本
gcc --version
g++ --version
下载 mingw-get-setup.exe 并安装,记住安装路径如 C:\MinGW
添加环境变量 Path:C:\MinGW\bin
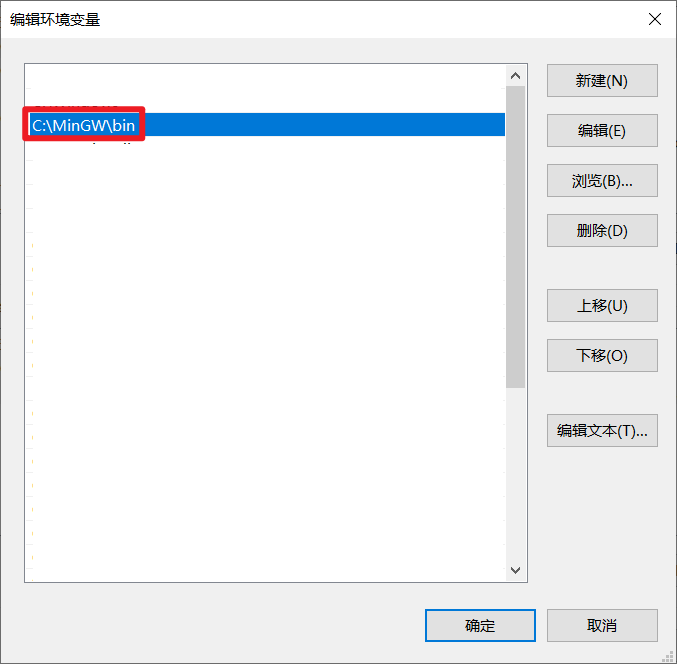
执行命令安装 GCC 和 G++
mingw-get install gcc
mingw-get install g++
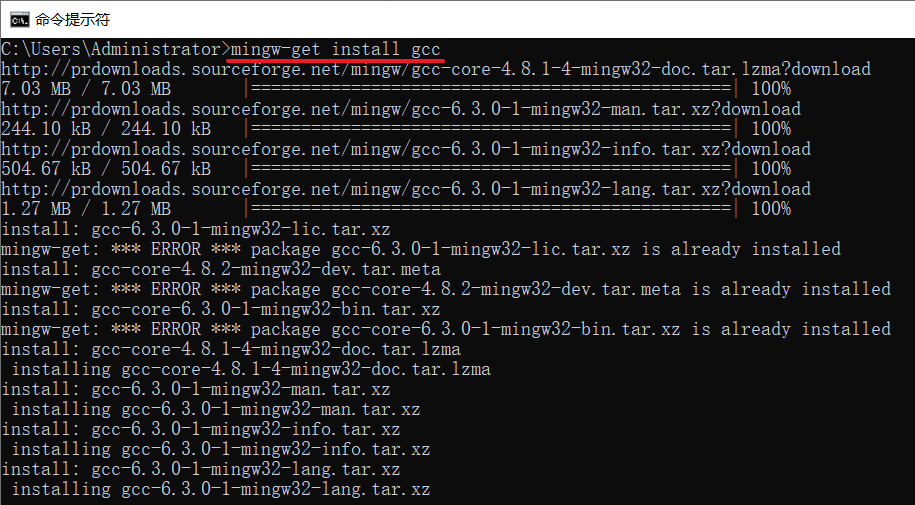
查看版本
gcc --version
g++ --version
7. Visual Studio 2015
可能需要也可能不需要,只要后面 ninja 编译能通过就行
8. Visual Studio 2019
下载 Visual Studio 2019 Community 社区版
IDE安装路径:C:\Program Files (x86)\Microsoft Visual Studio\2019\Community
工作负荷勾选【使用 C++ 的桌面开发】
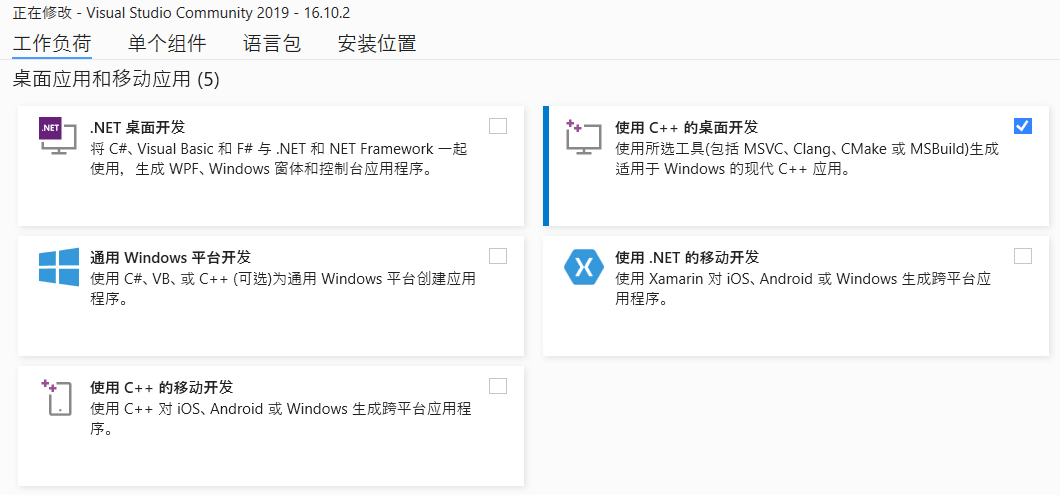
配置环境变量 Path(版本号会有所不同):C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Tools\MSVC\14.29.30037\bin\Hostx64\x64
执行命令:cl
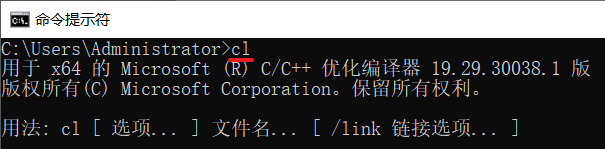
如果之前装了其他版本的Visual Studio,需要重置编译器(如上版本号是14.29.30037,则把call命令最后版本替换为14.29):
SET MSSdk=1
SET DISTUTILS_USE_SDK=1
call "C:\Program Files (x86)\Microsoft Visual Studio\2019\Community\VC\Auxiliary\Build\vcvarsall.bat" amd64 -vcvars_ver=14.29
9. ninja
git clone https://github.com/ninja-build/ninja.git
打开 Visual C++ 2015 x86 x64 Cross Build Tools Command Prompt.exe
cd ninja
python configure.py --bootstrap
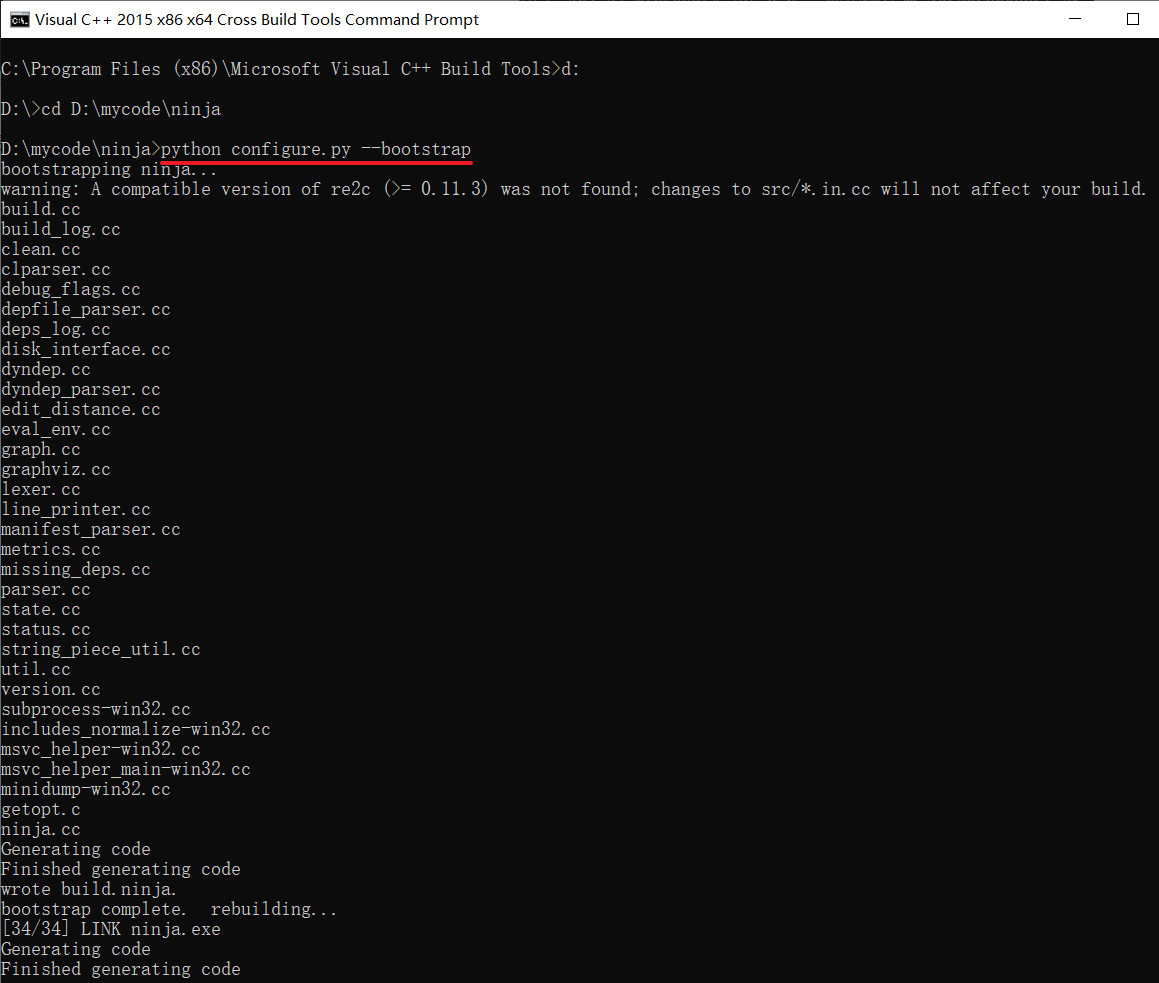
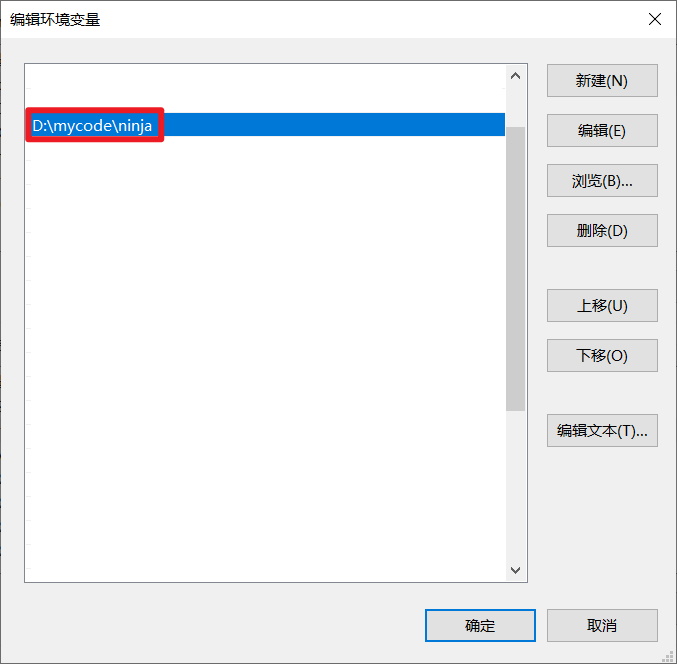
配置环境变量 Path:D:\mycode\ninja
10. Detectron2
git clone https://github.com/facebookresearch/detectron2
cd detectron2
python setup.py clean --all
python setup.py build --force develop
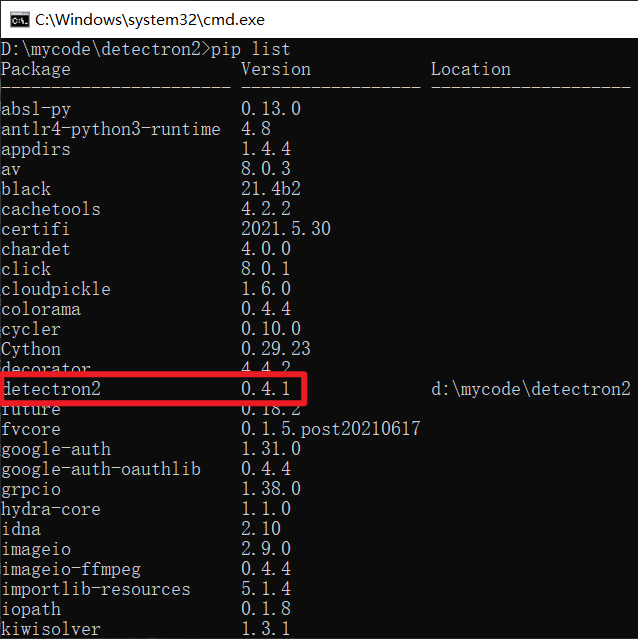
测试图片 test.jpg

直接点击下方超链接下载 模型库 里的模型,测试图片test.jpg放在image文件夹中,新建文件夹output,模型文件放在model文件夹中
目标检测(Object Detection)
python demo/demo.py --config-file configs/COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml --input image/test.jpg --output output/1.jpg --opts MODEL.WEIGHTS 'model/model_final_b275ba.pkl'

实例分割(Instance Segmentation)
python demo/demo.py --config-file configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml --input image/test.jpg --output output/2.jpg --opts MODEL.WEIGHTS 'model/model_final_f10217.pkl'

人体关键点检测(Person Keypoint Detection)
python demo/demo.py --config-file configs/COCO-Keypoints/keypoint_rcnn_R_50_FPN_3x.yaml --input image/test.jpg --output output/3.jpg --opts MODEL.WEIGHTS 'model/model_final_a6e10b.pkl'

全景分割(Panoptic Segmentation)
python demo/demo.py --config-file configs/COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml --input image/test.jpg --output output/4.jpg --opts MODEL.WEIGHTS 'model/model_final_cafdb1.pkl'

11. SlowFast
git clone https://github.com/facebookresearch/SlowFast.git
cd SlowFast
python setup.py build develop
python setup.py clean --all
python setup.py build --force develop
报错 error: Could not find suitable distribution for Requirement.parse(‘PIL’)
将 setup.py 中的 PIL 改为 pillow
总结
| 库 | 功能 |
|---|---|
| PyTorch | 深度学习框架 |
| fvcore | FAIR团队开发计算机视觉框架中的核心功能 |
| torchvision | pytorch中的数据集,模型和图片转换工具 |
| simplejson | JSON编解码器 |
| PyAV | FFmpeg的Python接口 |
| psutil | 跨平台进程和系统监控 |
| opencv-python | 计算机视觉库 |
| tensorboard | TensorFlow的可视化工具包 |
| moviepy | 视频编辑库 |
| PyTorchVideo | 视频理解研究的深度学习库 |
| Detectron2 | 检测和分割算法库 |
参考文献:
术语
视频识别基准(Benchmarks)
- Kinetics:视频识别。根据版本不同,该数据集包含多达65万个视频片段的URL链接,涵盖400/600/700个人类动作类。这些视频包括弹奏乐器等人和物互动,以及握手和拥抱等人与人之间的互动。每个动作类至少有400/600/700个视频剪辑。每个剪辑都带有一个单独的动作类,持续约10秒。
- Charades:一个指导我们研究非结构化视频活动识别和日常人类活动常识推理的数据集。
- AVA:行为检测。AVA数据集对430个电影剪辑中的80个小视觉动作进行了细致注释,这些动作在空间和时间上都是本地化的,产生了1.62万个动作标签,每个人有多个标签。剪辑是从15分钟的连续电影片段中提取的,为对活动进行时间推理打开了大门。数据集被分成235个视频用于训练,64个视频用于验证,131个视频用于测试。
X3D:扩展高效视频识别架构
初试
下载 SLOWFAST_32x2_R101_50_50.pkl 放到 SlowFast\demo\AVA
新建 ava.json 放到 SlowFast\demo\AVA
{"bend/bow (at the waist)": 0, "crawl": 1, "crouch/kneel": 2, "dance": 3, "fall down": 4, "get up": 5, "jump/leap": 6, "lie/sleep": 7, "martial art": 8, "run/jog": 9, "sit": 10, "stand": 11, "swim": 12, "walk": 13, "answer phone": 14, "brush teeth": 15, "carry/hold (an object)": 16, "catch (an object)": 17, "chop": 18, "climb (e.g., a mountain)": 19, "clink glass": 20, "close (e.g., a door, a box)": 21, "cook": 22, "cut": 23, "dig": 24, "dress/put on clothing": 25, "drink": 26, "drive (e.g., a car, a truck)": 27, "eat": 28, "enter": 29, "exit": 30, "extract": 31, "fishing": 32, "hit (an object)": 33, "kick (an object)": 34, "lift/pick up": 35, "listen (e.g., to music)": 36, "open (e.g., a window, a car door)": 37, "paint": 38, "play board game": 39, "play musical instrument": 40, "play with pets": 41, "point to (an object)": 42, "press": 43, "pull (an object)": 44, "push (an object)": 45, "put down": 46, "read": 47, "ride (e.g., a bike, a car, a horse)": 48, "row boat": 49, "sail boat": 50, "shoot": 51, "shovel": 52, "smoke": 53, "stir": 54, "take a photo": 55, "text on/look at a cellphone": 56, "throw": 57, "touch (an object)": 58, "turn (e.g., a screwdriver)": 59, "watch (e.g., TV)": 60, "work on a computer": 61, "write": 62, "fight/hit (a person)": 63, "give/serve (an object) to (a person)": 64, "grab (a person)": 65, "hand clap": 66, "hand shake": 67, "hand wave": 68, "hug (a person)": 69, "kick (a person)": 70, "kiss (a person)": 71, "lift (a person)": 72, "listen to (a person)": 73, "play with kids": 74, "push (another person)": 75, "sing to (e.g., self, a person, a group)": 76, "take (an object) from (a person)": 77, "talk to (e.g., self, a person, a group)": 78, "watch (a person)": 79}
修改 SLOWFAST_32x2_R101_50_50.yaml
#TENSORBOARD:
# MODEL_VIS:
# TOPK: 2
DEMO:
ENABLE: True
LABEL_FILE_PATH: "D:/mycode/SlowFast/demo/AVA/ava.json" # Add local label file path here.
# WEBCAM: 0
INPUT_VIDEO: "D:/mycode/SlowFast/demo/AVA/1.mp4"
OUTPUT_FILE: "D:/mycode/SlowFast/demo/AVA/2.mp4"
DETECTRON2_CFG: "COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"
DETECTRON2_WEIGHTS: detectron2://COCO-Detection/faster_rcnn_R_50_FPN_3x/137849458/model_final_280758.pkl
执行命令
python tools/run_net.py --cfg demo/AVA/SLOWFAST_32x2_R101_50_50.yaml
若速度较慢,可手动下载 model_final_280758.pkl 放到 C:\Users\Administrator\.torch\iopath_cache\detectron2\COCO-Detection\faster_rcnn_R_50_FPN_3x\137849458 中
2GB显存,加载失败,报错RuntimeError: CUDA out of memory. Tried to allocate 58.00 MiB (GPU 0; 2.00 GiB total capacity; 1.03 GiB already allocated; 39.17 MiB free; 1.08 GiB reserved in total by PyTorch)



















 2888
2888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











