







大数据环境安装与测试
内存8GB,4核CPU
利用好批处理命令来管理整个集群
准备external网络:
sudo docker network create es_network集群启动:run.sh
#!/bin/bash
docker-compose -f docker-compose.yml up -d namenode hive-metastore-postgresql
docker-compose -f docker-compose.yml up -d datanode hive-metastore
docker-compose -f docker-compose.yml up -d resourcemanager
docker-compose -f docker-compose.yml up -d nodemanager
docker-compose -f docker-compose.yml up -d historyserver
sleep 5
docker-compose -f docker-compose.yml up -d hive-server
docker-compose -f docker-compose.yml up -d spark-master spark-worker
docker-compose -f docker-compose.yml up -d mysql-server
docker-compose -f docker-compose.yml up -d elasticsearch
docker-compose -f docker-compose.yml up -d kibana
my_ip=`ip route get 1|awk '{print $NF;exit}'`
echo "Namenode: http://${my_ip}:50070"
echo "Datanode: http://${my_ip}:50075"
echo "Spark-master: http://${my_ip}:8080"
docker-compose exec spark-master bash -c "./copy-jar.sh && exit"
copy-jar.sh
#!/bin/bash
cd /opt/hadoop-2.8.0/share/hadoop/yarn/lib/ && cp jersey-core-1.9.jar jersey-client-1.9.jar /spark/jars/ && rm -rf /spark/jars/jersey-client-2.22.2.jar
停止集群:stop.sh
#!/bin/bash
docker-compose stop
验证
在docker-compose.yml所在文件夹下,输入以下命令进入指定容器
sudo docker-compose exec namenode bash
业务逻辑概述:

数据同步:
同步中间件sqoop

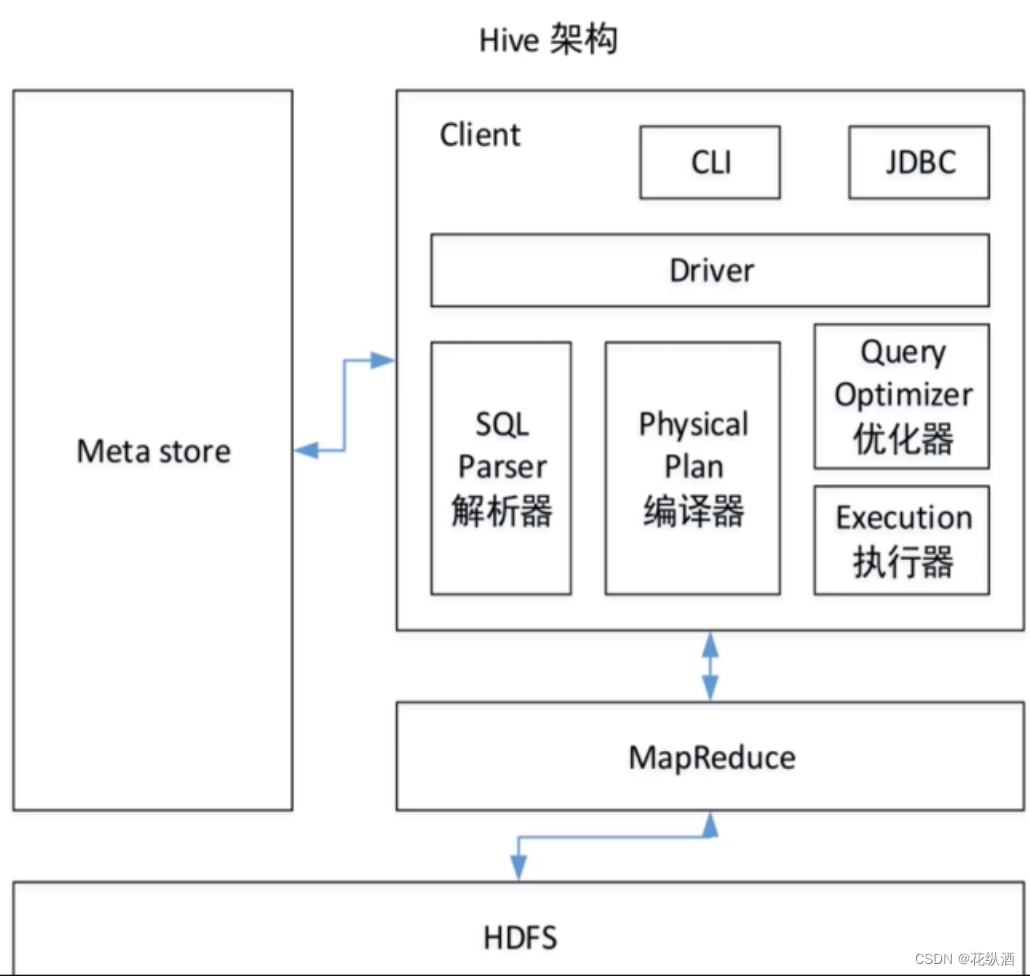
创建hive数据表定义
hive> create table student(id int,name string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
导入本地文件student到hive的default数据库的student表中
hive> load data local inpath '/opt/student' into table student;
通过上传本地文件到HDFS的HIVE的数据仓库
hadoop fs -put student.txt /user/hive/warehouse/student
通过上传本地文件到HDFS,并导入到的HIVE的数据仓库
hadoop fs -put student3 /
load data inpath 'hdfs://namenode:8020/student3' into table student;
hive创建外部表步骤:
hive> create external table stu_ext(id int,name string) row format delimited fields terminated by '\t' location 'hdfs://namenode:8020/student';
再在hdfs中创建对应目录:
hadoop fs -mkdir /student
sqoopan安装配置:
解压重命名:
tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha sqoop拷贝mysql数据库驱动到sqoop的conf目录
cp mysql-connector-java-5.1.28.jar sqoop/lib/
sqoop基本设置:(conf目录下)
cp sqoop-env-template.sh sqoop-env.sh
修改sqoop-env.sh其中内容:
export HIVE_HOME=/opt/hive
sqoop列出mysql中的数据库:
bin/sqoop list-databases --connect jdbc:mysql://10.10.10.153:3306 --username root --password 123456
利用sqoop从mysql把数据导入到hive中
必须先在hive中创建对应的数据库
hive> create database i_commodity;
OK
Time taken: 0.139 seconds
hive> create database i_marketing;
OK
Time taken: 0.081 seconds
hive> create database i_member;
OK
Time taken: 0.039 seconds
hive> create database i_operation;
OK
Time taken: 0.038 seconds
hive> create database i_order;
OK
Time taken: 0.032 seconds
从mysql导数据到hive:
bin/sqoop import --connect jdbc:mysql://10.10.10.153:3306/i_member --username root --password 123456 \
--table t_member \
--num-mappers 1 \
--hive-import \
--hive-overwrite \
--fields-terminated-by "\t" \
--hive-database i_member \
--hive-table t_member 数据平台架构

数据血缘
数据分层:
为什么:统一维护、细化
哪些层:

技术实现:















 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









