








解决: Unable to instantiate SparkSession with Hive support because Hive classes are not found.
在pom.xml中添加hive库依赖即可:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.8</version>
</dependency>Hive 远程连接的方法
#在hive-server中,启动
cd /export/servers/hive
nohup bin/hive --service metastore &
nohup bin/hive --service hiveserver2 &
利用java访问hive代码:

简单的java查询hive实例代码:
package edu.spark_java.tag.etl;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import com.alibaba.fastjson.JSON;
import java.util.List;
public class MemberETL {
public static void main(String[] args) {
SparkSession session=SparkSession.builder()
.appName("member etl")
.master("local[*]")
.enableHiveSupport()
.getOrCreate();
Dataset<Row> dataset=session.sql("select sex as membersex,count(id) as sexcount from i_member.t_member group by sex");
List<String> list=dataset.toJSON().collectAsList();
System.out.println(JSON.toJSONString(list));
}
}
优化的的java查询hive实例代码:
package cn.imooc.bigdata.sparkestag.etl;
import cn.imooc.bigdata.sparkestag.support.SparkUtils;
import com.alibaba.fastjson.JSON;
import lombok.Data;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.List;
import java.util.stream.Collectors;
/**
* @author bywind
*/
public class MemberEtl {
/**
* member sex etl
* 在main函数中调用,必须声明为static
* @param session
* @return
*/
public static List<MemberSex> memberSex(SparkSession session) {
Dataset<Row> dataset = session.sql("select sex as memberSex, count(id) as sexCount " +
" from i_member.t_member group by sex");
List<String> list = dataset.toJSON().collectAsList();
// System.out.println(JSON.toJSONString(list));
List<MemberSex> collect = list.stream()
.map(str -> JSON.parseObject(str, MemberSex.class))
.collect(Collectors.toList());
return collect;
}
/**
* member reg channel
*
* @param session
* @return
*/
public static List<MemberChannel> memberRegChannel(SparkSession session) {
Dataset<Row> dataset = session.sql("select member_channel as memberChannel, count(id) as channelCount " +
" from i_member.t_member group by member_channel");
List<String> list = dataset.toJSON().collectAsList();
List<MemberChannel> collect = list.stream()
.map(str -> JSON.parseObject(str, MemberChannel.class))
.collect(Collectors.toList());
return collect;
}
/**
* mp sub etl
* 注意select语句中count(if )的语法,可以代替where子句
* @param session
* @return
*/
public static List<MemberMpSub> memberMpSub(SparkSession session) {
Dataset<Row> sub = session.sql("select count(if(mp_open_id !='null',id,null)) as subCount, " +
" count(if(mp_open_id ='null',id,null)) as unSubCount " +
" from i_member.t_member");
List<String> list = sub.toJSON().collectAsList();
List<MemberMpSub> collect = list.stream()
.map(str -> JSON.parseObject(str, MemberMpSub.class))
.collect(Collectors.toList());
return collect;
}
/**
* member heat
*
* @param session
* @return
*/
public static MemberHeat memberHeat(SparkSession session) {
// reg , complete , order , orderAgain, coupon
// reg , complete ==> i_member.t_member phone = 'null'
// order,orderAgain ==> i_order.t_order
// coupon ==> i_marketing.t_coupon_member
Dataset<Row> reg_complete = session.sql("select count(if(phone='null',id,null)) as reg," +
" count(if(phone !='null',id,null)) as complete " +
" from i_member.t_member");
// order,orderAgain
Dataset<Row> order_again = session.sql("select count(if(t.orderCount =1,t.member_id,null)) as order," +
"count(if(t.orderCount >=2,t.member_id,null)) as orderAgain from " +
"(select count(order_id) as orderCount,member_id from i_order.t_order group by member_id) as t");
// coupon
Dataset<Row> coupon = session.sql("select count(distinct member_id) as coupon from i_marketing.t_coupon_member ");
Dataset<Row> result = coupon.crossJoin(reg_complete).crossJoin(order_again);
List<String> list = result.toJSON().collectAsList();
List<MemberHeat> collect = list.stream().map(str -> JSON.parseObject(str, MemberHeat.class)).collect(Collectors.toList());
return collect.get(0);
}
public static void main(String[] args) {
SparkSession session = SparkUtils.initSession();
List<MemberSex> memberSexes = memberSex(session);
List<MemberChannel> memberChannels = memberRegChannel(session);
List<MemberMpSub> memberMpSubs = memberMpSub(session);
MemberHeat memberHeat = memberHeat(session);
MemberVo vo = new MemberVo();
vo.setMemberChannels(memberChannels);
vo.setMemberSexes(memberSexes);
vo.setMemberMpSubs(memberMpSubs);
vo.setMemberHeat(memberHeat);
System.out.println("=====" + JSON.toJSONString(vo));
}
//@Data注释,可以不用重写get、set方法
@Data
static class MemberSex {
private Integer memberSex;
private Integer sexCount;
}
@Data
static class MemberChannel {
private Integer memberChannel;
private Integer channelCount;
}
@Data
static class MemberMpSub {
private Integer subCount;
private Integer unSubCount;
}
@Data
static class MemberVo {
private List<MemberSex> memberSexes;
private List<MemberChannel> memberChannels;
private List<MemberMpSub> memberMpSubs;
private MemberHeat memberHeat;
}
@Data
static class MemberHeat {
private Integer reg;
private Integer complete;
private Integer order;
private Integer orderAgain;
private Integer coupon;
}
}
使用elasticsearch和kibana
观察docker-compose.yml中的相关部分如下:
elasticsearch:
image: elasticsearch:6.5.3
environment:
- discovery.type=single-node
ports:
- "9200:9200"
- "9300:9300"
networks:
- es_network
kibana:
image: kibana:6.5.3
ports:
- "5601:5601"
networks:
- es_network启动docker集群
访问namenode:9200 (elasticsearch)、namenode:5601(kibana的web端口)
用spark操作elasticsearch的示例代码:
package edu.spark_java.tag.etl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.elasticsearch.spark.rdd.api.java.JavaEsSpark;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
public class EsDemo {
public static void main(String[] args) {
SparkConf conf=new SparkConf().setAppName("es demo").setMaster("local[*]");
conf.set("es.nodes","namenode"); //设置elasticsearch集群
conf.set("es.port","9200"); //设置ES的端口
conf.set("es.index.auto.create","true"); //设置自动创建索引
JavaSparkContext jsc=new JavaSparkContext(conf);
List<User> list=new ArrayList<>();
list.add(new User("zhangsan",18));
list.add(new User("lisi",19));
JavaRDD<User> rdd=jsc.parallelize(list);
JavaEsSpark.saveToEs(rdd,"/user/_doc");
}
@Data //简化get、set方法
@AllArgsConstructor //简化有参数构造函数
@NoArgsConstructor //简化无参数构造函数
public static class User implements Serializable{
private String name;
private int age;
}
}
在kibana的web界面中验证数据是否添加成功:访问http://namenode:5601
在console中输入命令:POST user/_search

查询获取到刚添加的数据:
package edu.spark_java.tag.etl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.codehaus.jackson.map.util.BeanUtil;
import org.elasticsearch.spark.rdd.api.java.JavaEsSpark;
import scala.Tuple2;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class EsDemo {
public static void main(String[] args) {
SparkConf conf=new SparkConf().setAppName("es demo").setMaster("local[*]");
conf.set("es.nodes","namenode"); //设置elasticsearch集群
conf.set("es.port","9200"); //设置ES的端口
conf.set("es.index.auto.create","true"); //设置自动创建索引
JavaSparkContext jsc=new JavaSparkContext(conf);
/*
利用java向elasticsearch添加数据
List<User> list=new ArrayList<>();
list.add(new User("zhangsan",18));
list.add(new User("lisi",19));
JavaRDD<User> rdd=jsc.parallelize(list);
JavaEsSpark.saveToEs(rdd,"/user/_doc");
*/
//查询elasticsearch数据
JavaPairRDD<String, Map<String,Object>> pairRDD=JavaEsSpark.esRDD(jsc,"/user/_doc");
Map<String,Map<String,Object>> stringmapmap=pairRDD.collectAsMap();
System.out.println(stringmapmap);
JavaRDD<User> rdd=pairRDD.map(new Function<Tuple2<String, Map<String, Object>>, User>() {
@Override
public User call(Tuple2<String, Map<String, Object>> v1) throws Exception {
User user=new User();
BeanUtils.populate(user,v1._2());
return user;
}
});
List<User> list=rdd.collect();
System.out.println(list);
}
@Data //简化get、set方法
@AllArgsConstructor //简化有参数构造函数
@NoArgsConstructor //简化无参数构造函数
public static class User implements Serializable{
private String name;
private int age;
}
}

对比一下must、should的区别:
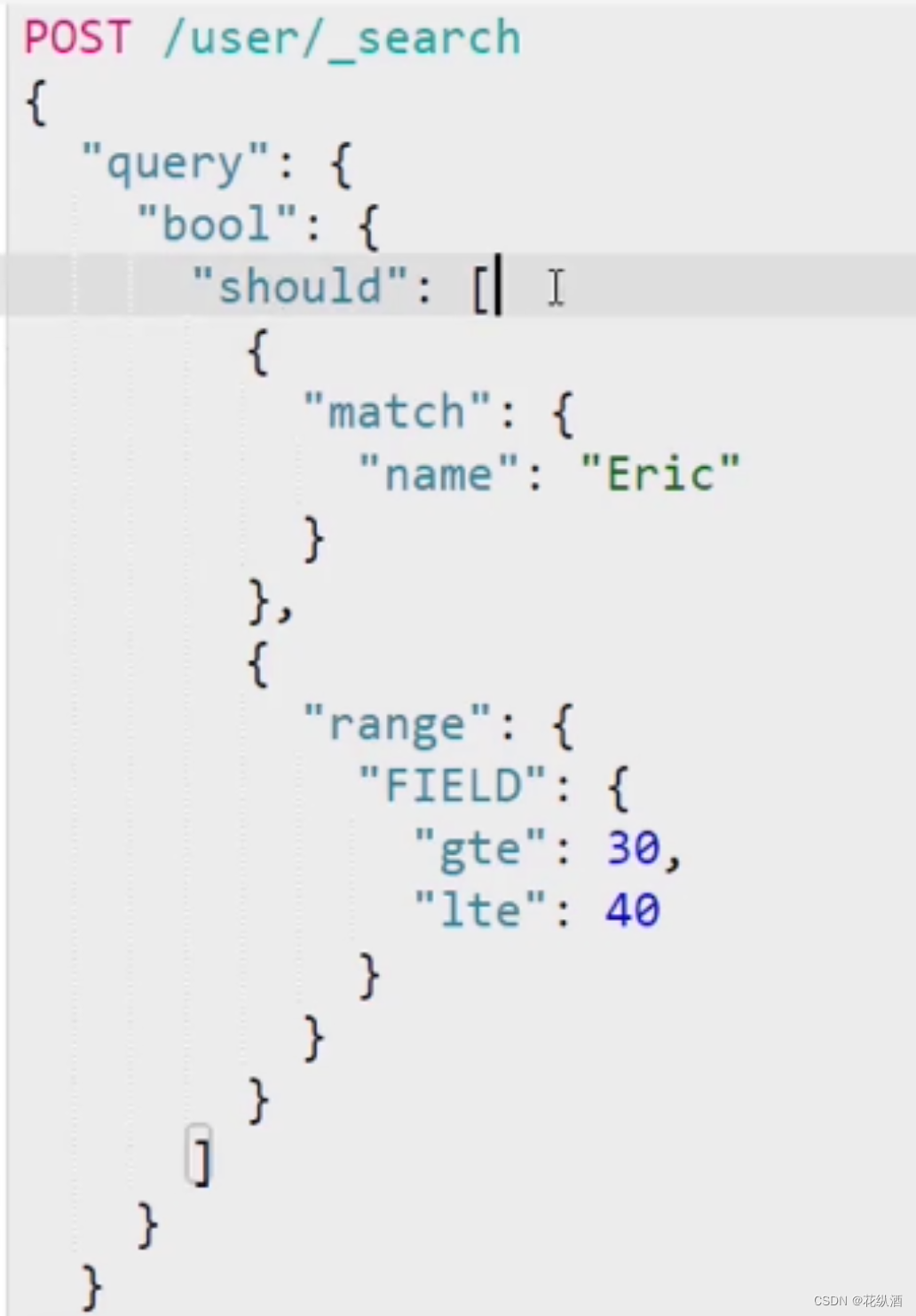
package edu.spark_java.tag.etl;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.commons.beanutils.BeanUtils;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.codehaus.jackson.map.util.BeanUtil;
import org.elasticsearch.spark.rdd.api.java.JavaEsSpark;
import scala.Tuple2;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class EsDemo {
public static void main(String[] args) {
SparkConf conf=new SparkConf().setAppName("es demo").setMaster("local[*]");
conf.set("es.nodes","namenode"); //设置elasticsearch集群
conf.set("es.port","9200"); //设置ES的端口
conf.set("es.index.auto.create","true"); //设置自动创建索引
JavaSparkContext jsc=new JavaSparkContext(conf);
/*
利用java向elasticsearch添加数据
List<User> list=new ArrayList<>();
list.add(new User("zhangsan",18));
list.add(new User("lisi",19));
JavaRDD<User> rdd=jsc.parallelize(list);
JavaEsSpark.saveToEs(rdd,"/user/_doc");
*/
//查询elasticsearch数据
JavaPairRDD<String, Map<String,Object>> pairRDD=JavaEsSpark.esRDD(jsc,"/user/_doc");
Map<String,Map<String,Object>> stringmapmap=pairRDD.collectAsMap();
System.out.println(stringmapmap);
JavaRDD<User> rdd=pairRDD.map(new Function<Tuple2<String, Map<String, Object>>, User>() {
@Override
public User call(Tuple2<String, Map<String, Object>> v1) throws Exception {
User user=new User();
BeanUtils.populate(user,v1._2());
return user;
}
});
List<User> list=rdd.collect();
System.out.println(list);
//按条件查询elasticsearch的数据,在kibana中用ctrl+i,压缩查询条件,拷贝
String query="{\"query\":{\"bool\":{\"must\":[{\"match\":{\"name\":\"lisi\"}}]}}}";
JavaPairRDD<String, String> javardd1=JavaEsSpark.esJsonRDD(jsc,"/user/_doc",query);
Map<String,String> map1=javardd1.collectAsMap();
System.out.println(map1);
}
@Data //简化get、set方法
@AllArgsConstructor //简化有参数构造函数
@NoArgsConstructor //简化无参数构造函数
public static class User implements Serializable{
private String name;
private int age;
}
}















 740
740











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









