









神经网络协同过滤模型(NCF)课程推荐系统
一、效果图
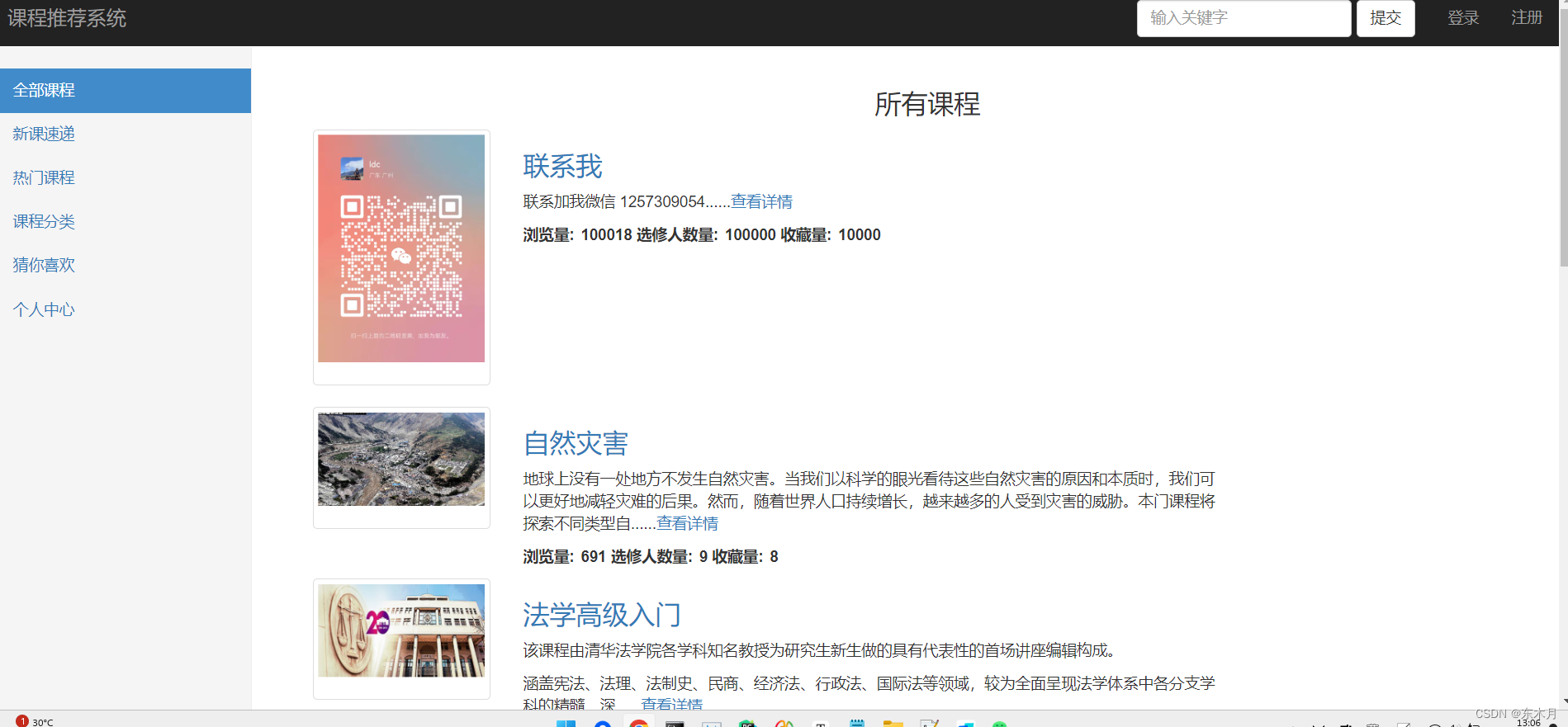
二、功能简介
本系统具有功能有:
# -*- coding: utf-8 -*-
"""
@contact: (微)信 1257309054
@file: test.py
@time: 2024/6/22 12:46
@author: LDC
"""
登录注册
热门课程
课程分类
课程推荐
个人中心
可视化大屏
后台管理
三、技术栈
开发语言是python,版本是3.8;
数据库是mysql版本是5.7;
后端使用的是django,版本是3;
前端使用的是django渲染的;
后台管理使用的是xadmin,版本是3。
神经网络框架使用的是tensorflow,版本是1.14.0。
四、启发式推荐系统
推荐系统的核心是根据用户的兴趣需求,给用户推荐喜欢的内容。常用的推荐算法有启发式推荐算法,可分为基于用户的 协同过滤,基于物品的协同过滤。
1、基于用户的协同过滤(UCF)
主要考虑的是用户和用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 5 | 4 | 1 | 5 |
--------+--------+--------+--------+--------+
b | 4 | 3 | 1 | ? |
--------+--------+--------+--------+--------+
c | 2 | 2 | 5 | 1 |
--------+--------+--------+--------+--------+
a用户给X物品打了5分,给Y打了4分,给Z打了1分
b用户给X物品打了4分,给Y打了3分,给Z打了1分
c用户给X物品打了2分,给Y打了2分,给Z打了5分
那么很容易看到a用户和b用户非常相似,但是b用户没有看过R物品,
那么我们就可以把和b用户很相似的a用户打分很高的R物品推荐给b用户,
这就是基于用户的协同过滤。
2、基于物品的协同过滤(ICF)
主要考虑的是物品和物品之间的相似度,只有找到了目标用户对某些物品的评分,那么就可以对相似度高的类似物品进行预测,将评分最高的若干个相似物品推荐给用户。
举例:
--------+--------+--------+--------+--------+
| X | Y | Z | R |
--------+--------+--------+--------+--------+
a | 5 | 5 | 1 | 5 |
--------+--------+--------+--------+--------+
b | 5 | 5 | 1 | 2 |
--------+--------+--------+--------+--------+
c | 5 | 5 | 5 | 1 |
--------+--------+--------+--------+--------+
d | 5 | ? | ? | ? |
--------+--------+--------+--------+--------+
a用户给X物品打了5分,给Y打了5分,给Z打了1分,给R打了5分
b用户给X物品打了5分,给Y打了5分,给Z打了1分,给R打了2分
c用户给X物品打了5分,给Y打了5分,给Z打了5分,给R打了1分
那么很容易看到a用户、b用户、c用户都喜欢课程X,Y,
那么当用户d也喜欢课程X时,就会把课程Y推荐给用户d
因为基于用户a、b、c的评分,系统会认为喜欢X书籍的人在很大程度上会喜欢Y书籍。
这就是基于物品的协同过滤。
3、启发式推荐算法优缺点
优点:易于实现,并且推荐结果的可解释性强。
缺点:
难以处理冷启动问题:当一个用户或一个物品没有足够的评分数据时,启发式协同过滤算法无法对其进行有效的预测,因为它需要依赖于已有的评分数据。
对数据稀疏性敏感:如果数据集中存在大量的缺失值,启发式协同过滤算法的预测准确率会受到影响,因为它需要依赖于完整的评分数据来进行预测。
推荐类型单一化:推荐结果容易陷入一个小范围的困境,如果某个用户特别喜欢小说类的课程,那么这种系统就会不断地推荐小说类课程,实际上这个用户很有可能也喜欢历史、文学、传记类的课程,但是囿于冷启动问题,无法进行推荐。
五、神经网络协同过滤模型(NCF)
为了解决启发式推荐算法的问题,基于神经网络的协同过滤算法诞生了,神经网络的协同过滤算法可以通过将用户和物品的特征向量作为输入,来预测用户对新物品的评分,从而解决冷启动问题。
对数据稀疏性的鲁棒性:神经网络的协同过滤算法可以自动学习用户和物品的特征向量,并能够通过这些向量来预测评分,因此对于数据稀疏的情况也能进行有效的预测。
更好的预测准确率:神经网络的协同过滤算法可以通过多层非线性变换来学习用户和物品之间的复杂关系,从而能够提高预测准确率。
可解释性和灵活性:神经网络的协同过滤算法可以通过调整网络结构和参数来优化预测准确率,并且可以通过可视化方法来解释预测结果。
所以基于神经网络协同过滤模型是目前推荐系统的主流形态。
六、算法实现
安装库:
pip install numpy
pip install pandas
pip install tensorflow
1、全部代码
# -*- coding: utf-8 -*-
"""
@contact: 微信 1257309054
@file: recommend_ncf.py
@time: 2024/6/16 22:13
@author: LDC
"""
import os
import django
import joblib
import numpy as np
import pandas as pd
import tensorflow as tf
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
from keras.models import load_model
os.environ["DJANGO_SETTINGS_MODULE"] = "course_manager.settings"
django.setup()
from course.models import *
def get_all_data():
'''
从数据库中获取所有物品评分数据
[用户特征(点赞,收藏,评论,
物品特征(收藏人数,点赞人数,浏览量,评分人数,平均评分)
]
'''
# 定义字典列表
user_item_list = []
# 从评分表中获取所有课程数据
item_rates = RateCourse.objects.all().values('course_id').distinct()
# 获取每个用户的评分数据
for user in User.objects.all():
user_rate = RateCourse.objects.filter(user=user)
if not user_rate:
# 用户如果没有评分过任何一本课程则跳过循环
continue
data = {'User': f'user_{user.id}'}
for br in item_rates:
item_id = br['course_id']
ur = user_rate.filter(course_id=item_id)
if ur:
data[f'item_{item_id}'] = ur.first().mark # 对应课程的评分
else:
data[f'item_{item_id}'] = np.nan # 设置成空
user_item_list.append(data)
data_pd = pd.DataFrame.from_records(user_item_list)
print(data_pd)
return data_pd
def get_data_vector(data):
'''
对矩阵进行向量化,便于神经网络学习
'''
user_index = data[data.columns[0]]
data = data.reset_index(drop=True)
data[data.columns[0]] = data.index.astype('int')
scaler = 5 # 评分最高为5,把用户的评分归一化到0-1
df_vector = pd.melt(data, id_vars=[data.columns[0]],
ignore_index=True,
var_name='item_id',
value_name='rate').dropna()
df_vector.columns = ['user_id', 'item_id', 'rating']
df_vector['rating'] = df_vector['rating'] / scaler
df_vector['user_id'] = df_vector['user_id'].apply(lambda x: user_index[x])
print(df_vector)
return df_vector
def evaluation(y_true, y_pred):
'''
模型评估:获取准确率、精准度、召回率、F1-score值
y_true:正确标签
y_pred:预测标签
'''
accuracy = round(classification_report(y_true, y_pred, output_dict=True)['accuracy'], 3) # 准确率
s = classification_report(y_true, y_pred, output_dict=True)['weighted avg']
precision = round(s['precision'], 3) # 精准度
recall = round(s['recall'], 3) # 召回率
f1_score = round(s['f1-score'], 3) # F1-score
print('神经网络协同推荐(NCF):准确率是{},精准度是{},召回率是{},F1值是{}'.format(accuracy, precision, recall, f1_score))
return accuracy, precision, recall, f1_score
def get_data_fit(df_vector):
'''
数据训练,得到模型
'''
scaler = 5 # 特征标准化:最高分为5,需要归一化到0~1
dataset = df_vector # 已向量化的数据集
# 使用LabelEncoder将字符串标签转换为整数标签
user_encoder = LabelEncoder()
item_encoder = LabelEncoder()
dataset['user_id'] = user_encoder.fit_transform(dataset['user_id'])
dataset['item_id'] = item_encoder.fit_transform(dataset['item_id'])
# Split the dataset into train and test sets
train, test = train_test_split(dataset, test_size=0.2, random_state=42) # 划分训练集与测试集
# train = dataset
# Model hyperparameters
num_users = len(dataset['user_id'].unique())
num_countries = len(dataset['item_id'].unique())
embedding_dim = 64 # 64维向量标识
# 创建NCF模型
inputs_user = tf.keras.layers.Input(shape=(1,))
inputs_item = tf.keras.layers.Input(shape=(1,))
embedding_user = tf.keras.layers.Embedding(num_users, embedding_dim)(inputs_user)
embedding_item = tf.keras.layers.Embedding(num_countries, embedding_dim)(inputs_item)
# 合并 embeddings向量
merged = tf.keras.layers.Concatenate()([embedding_user, embedding_item])
merged = tf.keras.layers.Flatten()(merged)
# 添加全连接层
dense = tf.keras.layers.Dense(64, activation='relu')(merged)
dense = tf.keras.layers.Dense(32, activation='relu')(dense)
output = tf.keras.layers.Dense(1, activation='sigmoid')(dense)
# 编译模型
model = tf.keras.Model(inputs=[inputs_user, inputs_item], outputs=output)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
# 模型训练
model.fit(
[train['user_id'].values, train['item_id'].values],
train['rating'].values,
batch_size=64,
epochs=100,
verbose=0,
# validation_split=0.1,
)
item_rates = RateCourse.objects.all().values('course_id').distinct()
# 获取每个用户的评分数据
result_df = {}
for user in User.objects.all():
user_rate = RateCourse.objects.filter(user=user)
if not user_rate:
# 用户如果没有评分过任何一本课程则跳过循环
continue
user = f'user_{user.id}'
result_df[user] = {}
for br in item_rates:
item_id = br['course_id']
item = f'item_{item_id}'
pred_user_id = user_encoder.transform([user])
pred_item_id = item_encoder.transform([item])
result = model.predict(x=[pred_user_id, pred_item_id], verbose=0)
result_df[user][item] = result[0][0]
result_df = pd.DataFrame(result_df).T
result_df *= scaler
print('全部用户预测结果', result_df)
# 预测测试集并转成整形列表
y_pred_ = np.floor(model.predict(x=[test['user_id'], test['item_id']], verbose=0) * scaler).tolist()
y_pred = []
for y in y_pred_:
y_pred.append(int(y[0]))
y_true = (test['rating'] * scaler).tolist()
evaluation(y_true, y_pred) # 模型评估
joblib.dump(user_encoder, 'user_encoder.pkl') # 保存用户标签
joblib.dump(item_encoder, 'item_encoder.pkl') # 保存课程标签
model.save('ncf.dat') # 模型保存
def get_ncf_recommend(user_id, n=10):
'''
# 获取推荐
user_id:用户id
n:只取前十个推荐结果
'''
scaler = 5 # 特征标准化:最高分为5,需要归一化到0~1
model = load_model('ncf.dat') # 加载模型
# 加载标签
user_encoder = joblib.load('user_encoder.pkl')
item_encoder = joblib.load('item_encoder.pkl')
result_df = {}
item_rates = RateCourse.objects.all().values('course_id').distinct()
for item in item_rates:
item_id = item['course_id']
user = f'user_{user_id}'
item = f"item_{item_id}"
pred_user_id = user_encoder.transform([user])
pred_item_id = item_encoder.transform([item])
result = model.predict(x=[pred_user_id, pred_item_id], verbose=0)
if not RateCourse.objects.filter(user_id=user_id, course_id=item_id):
# 过滤掉用户已评分过的
result_df[item_id] = result[0][0] * scaler
result_df_sort = sorted(result_df.items(), key=lambda x: x[1], reverse=True) # 推荐结果按照评分降序排列
print('预测结果', result_df_sort)
recommend_ids = []
for rds in result_df_sort[:n]:
recommend_ids.append(rds[0])
print(f'前{n}个推荐结果', recommend_ids)
return recommend_ids
if __name__ == '__main__':
data_pd = get_all_data() # 获取数据
df_vector = get_data_vector(data_pd) # 数据向量化
data_recommend = get_data_fit(df_vector) # 获取数据训练模型
user_id = 1
recommend_ids = get_ncf_recommend(user_id) # 获取用户1的推荐结果

















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











