







1 树的广度优先遍历算法
广度优先遍历算法,又叫宽度优先遍历,或横向优先遍历,是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。
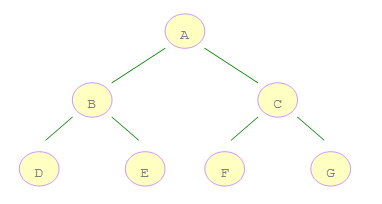
如上图所示的二叉树,A 是第一个访问的,然后顺序是 B、C,然后再是 D、E、F、G。
那么,怎样才能来保证这个访问的顺序呢?
借助队列数据结构,由于队列是先进先出的顺序,因此可以先将左子树入队,然后再将右子树入队。
这样一来,左子树结点就存在队头,可以先被访问到。
//广度优先遍历
void breadthFirstTravel(Node* root){
queue<Node *> nodeQueue; //使用C++的STL标准模板库
nodeQueue.push(root);
Node *node;
while(!nodeQueue.empty()){
node = nodeQueue.front();
nodeQueue.pop();
printf(format, node->data);
if(node->lchild){
nodeQueue.push(node->lchild); //先将左子树入队
}
if(node->rchild){
nodeQueue.push(node->rchild); //再将右子树入队
}
}
}2 树的深度优先遍历算法
深度优先遍历算法是遍历算法的一种。是沿着树的深度遍历树的节点。
当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点。这一过程一直进行到已发现从源节点可达的所有节点为止。
如果还存在未被发现的节点,则选择其中一个作为源节点并重复以上过程,整个进程反复进行直到所有节点都被访问为止。
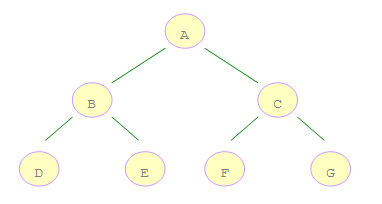
如上图所示的二叉树:
A 是第一个访问的,然后顺序是 B、D,然后是 E。接着再是 C、F、G。
那么,怎么样才能来保证这个访问的顺序呢?
分析一下,在遍历了根结点后,就开始遍历左子树,最后才是右子树。
因此可以借助堆栈的数据结构,由于堆栈是后进先出的顺序,由此可以先将右子树压栈,然后再对左子树压栈,
这样一来,左子树结点就存在了栈顶上,因此某结点的左子树能在它的右子树遍历之前被遍历。
//深度优先遍历
void depthFirstTravel(Node* root){
stack<Node *> nodeStack; //使用C++的STL标准模板库
nodeStack.push(root);
Node *node;
while(!nodeStack.empty()){
node = nodeStack.top();
printf(format, node->data); //遍历根结点
nodeStack.pop();
if(node->rchild){
nodeStack.push(node->rchild); //先将右子树压栈
}
if(node->lchild){
nodeStack.push(node->lchild); //再将左子树压栈
}
}
}















 2738
2738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









