





前面我们了解了深度优先算法,在遍历一棵树的时候会深入地遍历完树的一个分支后才会去遍历其它的分支。而广度优先算法则是从根节点开始一层一层的进行遍历,只有完全遍历完一层所有的节点后才会进入下一层的遍历。广度优先算法的一般套路如下:
- 创建一个队列并将根将节点插入到个队列中,此时根节点作为第一层,总共有一个节点。
- 在每层遍历开始前,队列的长度就是这一层的节点总数,我们记录下这个数目然后不断地将节点出队进行遍历并将其子节点插入到队列中,同时每遍历一个节点就将前面记录的数字减一。
- 当数字为零时,表明这一层的所有节点已经遍历完了,返回第二步进行迭代遍历直到队列为空为止。
我们可以结合LeetCode的题目和代码来了解一下。
LeetCode102
题目链接:
https://leetcode.com/problems/binary-tree-level-order-traversal/
题目描述:
给定一棵二叉树,对其一层层地从左到右遍历,并按层次返回所有节点的数值。
例子
给定二叉树[3,9,20,null,null,15,7],
3
/
9 20
/
15 7
其遍历结果为:
[
[3],
[9,20],
[15,7]
]
题目分析:
这是一道中等难度的题目,只需要对其进行广度优先遍历,然后按遍历的层次将每层的结果给分别记录下来即可。
代码:
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
if (!root) { return {}; }
vector<int> row;
vector<vector<int> > result;
queue<TreeNode*> q;
q.push(root);
int count = 1;
while (!q.empty()) {
if (q.front()->left) { q.push(q.front()->left); }
if (q.front()->right) { q.push(q.front()->right); }
row.push_back(q.front()->val), q.pop();
if (--count == 0) {
result.emplace_back(row), row.clear();
count = q.size();
}
}
return result;
}
};
代码分析:
在上述代码中,我们使用一个二维的数组来记录遍历的结果,数组的行数就是树的层级深度,每一行里保存的就是二叉树每一层的数据。创建一个队列用来保存下一层要遍历的节点,在初始的时候将根节点插入到队列中,变量 count 用来保存下一层里节点的数目,所以在插入根节点后其值为1。当队列不为空的时候,说明还有节点未遍历到,所以需要循环地遍历队列中的节点。遍历每个节点都将其不为空的左右子树插入到队列的尾部并将这个节点的数值插入到临时数组 raw 中。每次遍历完一个节点后,都将 count 的数值减一,当其值为0的时候代表这一层的遍历已经结束,此时数列中的所有节点就是下一层的节点。接下来将 count 的数值设为队列的长度,这样就记录下了下一层要遍历的节点数目。再将临时数组 raw 插入到 result 中并清空之后就可以继续对下一层的遍历了。
LeetCode127
题目链接: https://leetcode.com/problems/word-ladder/
题目描述: 给定一个 beginWord 和一个 endWord 以及一个单词列表。从 beginWord 开始每次只能更改单词中一个字母,并且这个更改字母后的单词必须在前面的单词列表中,找出一条从 beginWord 到 endWord 的最短路径,并返回其长度,没有此路径则返回0。
注意
- 所有的单词长度一致。
- 单词列表中没有重复。
- 所有单词为小写字母。
- beginWord 和 endWord 不相同且不为空。
例子
输入:
beginWord = "hit",
endWord = "cog",
wordList = ["hot","dot","dog","lot","log","cog"]
输出: 5
最短路径为 "hit" -> "hot" -> "dot" -> "dog" -> "cog", 长度为5
题目分析:
要使用广度优先算法,需要首先根据题目来构建一棵树。可以以 beginWord 为根节点,单词列表中所有和 beginWord 只有一个字母不同的单词都作为其子节点。而剩下的单词中和某个子节点只有一个字母不同的单词就是这个子节点的子节点。在使用广度优先算法遍历这棵树的时候,如果发现了 endWord,那么 从根节点到 endWord 的深度就是最短路径。
代码:
int ladderLength(string beginWord, string endWord, vector<string>& wordList) {
unordered_set<string> dict(wordList.begin(), wordList.end());
if(!dict.count(endWord)) return 0;
queue<string> wordQueue;
wordQueue.push(beginWord);
int level = 1;
int currentCount = 1;
int len = beginWord.size();
while(!wordQueue.empty()){
string word = wordQueue.front();
wordQueue.pop();
currentCount --;
for(int i = 0; i < len; i++){
char c = word[i];
for(int j = 'a'; j <= 'z'; j++){
word[i] = j;
if(word == endWord) return level + 1;
if(dict.count(word)){
wordQueue.push(word);
dict.erase(word);
}
}
word[i] = c;
}
if(currentCount == 0){
currentCount = wordQueue.size();
level ++;
}
}
return 0;
}
代码分析:
上述代码基本就是套用我们在一开始提出来的套路。中间的 for 循环通过将当前的单词的每个字母都从 a 到 z 替换一遍来在单词列表中查找其子节点。为了加快查找速度,我们将单词列表放在了 set 中。如果在 set 中查找到了一个更改后的单词,那这个单词就是原单词的子节点,将其入队并从 set 中删除。 如果更改后的单词恰好就是 endWord,说明我们找到了这样的一条最短路径,直接返回 endWord 的深度即可。
这道题目其实还可以进一步优化,从 beginWord 到 endWord 的最短路径反过来也都是一样,所以就可以从两头开始一起向中间查找,当在中间相遇的时候就说明有一条联通的路径了。具体实现就由读者自己来尝试吧。
LeetCode743
题目链接:https://leetcode.com/problems/network-delay-time/
题目描述:
有标签为从1到 N 的 N 个网络节点,给定一个信息传输时间的列表 times, 其中times[i] = (u, v, w) 代表了信息从节点 u 传输到节点 v 花费时间为 w。从节点 K 开始发出一个信息,计算出信息传递到所有节点所需要的最小时间,如果不能传输到每个节点就返回 -1。
例子
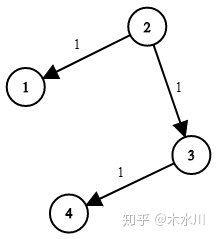
输入:times = [[2,1,1],[2,3,1],[3,4,1]], N = 4, K = 2
输出:2
题目分析:
将节点 K 看作是根节点,所有 K 能直接到达的节点就是 K 的子节点,这样就可以构建出一棵树来。对这棵树进行广度优先遍历就能按层次遍历到每个节点。由于到每个节点都需要花费时间,所以根节点到某个节点 A 的总时间就是根节点到节点 A 的父节点的时间加上 A 的父节点的时间到 A 的时间。此外还要考虑到有些节点可能会有多条路径都可以到达,这种情况下我们需要取这多条路径中时间最短的一条。
代码:
int networkDelayTime(vector<vector<int>>& times, int N, int K) {
vector<vector<pair<int,int>>> map(N + 1);
for(auto time : times) {
map[time[0]].push_back({time[1], time[2]});
}
auto cmp = [](pair<int,int> left, pair<int,int> right) { return left.second > right.second; };
priority_queue<pair<int,int>, vector<pair<int,int>>, decltype(cmp)> queue(cmp);
queue.push({K, 0});
vector<int> distance(N + 1, -1);
int count = 0;
while(!queue.empty() && count < N){
auto node = queue.top();
queue.pop();
if(distance[node.first] >= 0) continue;
distance[node.first] = node.second;
count++;
for(auto next : map[node.first]){
queue.push({next.first, next.second + node.second});
}
}
return count == N ? *max_element(distance.begin() + 1, distance.end()) : -1;
}
代码分析:
上述代码在文章开头提到的套路的基础上做了一些改进。我们首先对原始数据做一下处理,创建一个大小为 N + 1 的 vector, 将节点 i 所有能到达的节点和时间都插入到 vector 中 index 为 i 的位置中,这样可以方便后面查找子节点的操作。
接着我们创建一个优先级队列,将最短时间可以到达的节点放到最前面,将花费时间多的节点放在后面,这样如果一个节点有多条路径可以到达,先出队的肯定是花费时间最短的那条。队列在一开始先入队 {k, 0} 这个 pair,代表根节点到达自己的时间是0。
distance 数组我们用来保存到达每个节点所需要的时间,初始化为-1 表明所有的节点都还未计算出时间。count 用来记录已经计算了几个节点,当 count的值等于 N 时,表明所有的节点都计算完了,即使队列中还有数据,也肯定是那些花费时间长的路径,所以我们就可以退出接下来的循环。
在循环的中,我们从队列中取出一个节点,由于我们是优先级队列,所以如果发现这个节点在 distance 中已经有了记录就可以直接丢弃,而无需再次计算。每次计算完一个节点后,先将 count 的值加一,然后遍历所有当前节点的子节点,并更新子节点的时间后插入到队列中。
最后,只要判断一下 count 的值就可以知道是否遍历过了所有的节点。因为我们在 distance 数组中已经记录下了到每个节点所需的最少时间,所以里面的最大值就是题目的解。
总结一下,广度优先算法需要借助一个队列,这个队列我们可以根据题目要求改为优先级队列。在将根节点入队后,我们只需要在队列比不为空的前提下循环地从队列中取出节点进行遍历并将子节点入队就可以完成遍历。















 9041
9041











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









