







目录
引言
ChatGPT4相比于ChatGPT3.5,有着诸多不可比拟的优势,比如图片生成、图片内容解析、GPTS开发、更智能的语言理解能力等,但是在国内使用GPT4存在网络及充值障碍等问题,如果对ChatGPT4.0感兴趣,可以私信博主为您解决账号和环境问题。同时,如果您有一些AI技术应用的需要,也欢迎私信博主,我们聊一聊思路和解决方案
什么是提示工程(Prompt Engineering)
提示工程也叫「指令工程」。
- Prompt 就是你发给大模型的指令,比如「讲个笑话」、「用 Python 编个贪吃蛇游戏」、「给男/女朋友写封情书」等
- 貌似简单,但意义非凡
- 「Prompt」 是 AGI 时代的「编程语言」
- 「Prompt 工程」是 AGI 时代的「软件工程」
- 「提示工程师」是 AGI 时代的「程序员」
- 学会提示工程,就像学用鼠标、键盘一样,是 AGI 时代的基本技能
- 提示工程「门槛低,天花板高」,所以有人戏称 prompt 为「咒语」
- 但专门的「提示工程师」不会长久,因为每个人都要会「提示工程」,AI 的进化也会让提示工程越来越简单
Prompt 调优
找到好的 prompt 是个持续迭代的过程,需要不断调优。
如果知道训练数据是怎样的,参考训练数据来构造 prompt 是最好的。「当人看」类比:
- 你知道 ta 爱读红楼梦,就和 ta 聊红楼梦
- 你知道 ta 十年老阿里,就多说阿里黑话
- 你知道 ta 是日漫迷,就夸 ta 卡哇伊
不知道训练数据怎么办?
- 看 Ta 是否主动告诉你。例如:
- OpenAI GPT 对 Markdown 格式友好
- OpenAI 官方出了 Prompt Engineering 教程,并提供了一些示例
- Claude 对 XML 友好。
- 只能不断试了。有时一字之差,对生成概率的影响都可能是很大的,也可能毫无影响……
「试」是常用方法,确实有运气因素,所以「门槛低、 天花板高」。
高质量 prompt 核心要点:具体、丰富、少歧义
Prompt 的典型构成
不要固守「模版」。模版的价值是提醒我们别漏掉什么,而不是必须遵守模版才行。
- 角色:给 AI 定义一个最匹配任务的角色,比如:「你是一位软件工程师」「你是一位小学老师」
- 指示:对任务进行描述
- 上下文:给出与任务相关的其它背景信息(尤其在多轮交互中)
- 例子:必要时给出举例,学术中称为 one-shot learning, few-shot learning 或 in-context learning;实践证明其对输出正确性有很大帮助
- 输入:任务的输入信息;在提示词中明确的标识出输入
- 输出:输出的格式描述,以便后继模块自动解析模型的输出结果,比如(JSON、XML)
「定义角色」为什么有效?
- 模型训练者并没想到过会这样,完全是大家「把 AI 当人看」玩出的一个用法
- 实在传得太广,导致现在的大模型训练数据里充满了角色定义,所以更有效了
- 有一篇论文证实的现象,可以说明为啥「你是一个 xxx」特别有效
防止 Prompt 攻击
攻击方式 1:著名的「奶奶漏洞」
正情况下大模型会拒绝回答一些危险的问题,但是用户在进行prompt 的时候,可以让大模型不经意的回答了有害问题。
攻击方式 2:Prompt 注入
用户在进行prompt 的时候,向大模型提出更换大模型已定义的角色,让他回答用户自身需要的一些问题。
防范措施 1:Prompt 注入分类器
就像安检一样,在提交Prompt前,让大模型先判断这个Prompt是否有害。
防范措施 2:直接在输入中防御
当人看:每次默念动作要领。在Prompt前面添加必要的提示要求。
总结:目前并没有 100% 好用的防范方法。
高质量 prompt 技巧总结
- 把大模型当“”人”,看,不同的大模型有不同的沟通偏好。如:chatgpt对 Markdown 格式的文本识别度很高。 Claude 对 XML 友好。
- 发出的指令要尽量具体、丰富、少歧义。
- 定义角色。现有的大模型里的很多数据都是基于角色定义训练的。
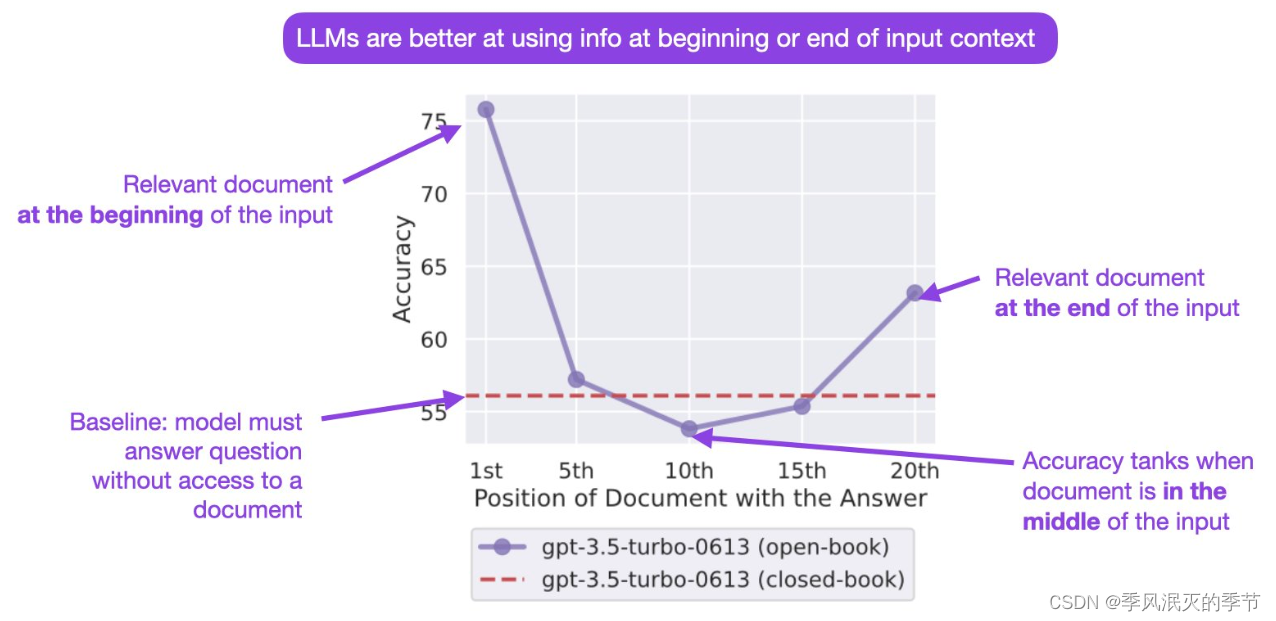
- 大模型对prompt的 开始和结束词语更敏感。将重要的事情在末尾描述三遍是一个不错的做法。
- 必要的时候举例描述或直接给出模板,能提升大模型回答的准确性。
- 思维链模型:将一个复杂的问题拆分成多个小问题,一步步 提问 比 直接将这个复杂的问题丢给 大模型,要可靠的多。
- 自洽性: 同一个问题,换个角度多问几次,取出现次数最高的结果。
- 注意做好prompt攻击防范。
OpenAI API 的几个重要参数
其它大模型的 API 基本都是参考 OpenAI,只有细节上稍有不同。
OpenAI 提供了两类 API:
- Completion API:续写文本,多用于补全场景。https://platform.openai.com/docs/api-reference/completions/create
- Chat API:多轮对话,但可以用对话逻辑完成任何任务,包括续写文本。https://platform.openai.com/docs/api-reference/chat/create
说明:
- Chat 是主流,有的大模型只提供 Chat
- 背后的模型可以认为是一样的,但也不完全一样
- Chat 模型是纯生成式模型做指令微调之后的结果,更多才多艺,更听话
def get_chat_completion(session, user_prompt, model="gpt-3.5-turbo"):
_session = copy.deepcopy(session)
_session.append({"role": "user", "content": user_prompt})
response = client.chat.completions.create(
model=model,
messages=_session,
# 以下默认值都是官方默认值
temperature=1, # 生成结果的多样性。取值 0~2 之间,越大越发散,越小越收敛
seed=None, # 随机数种子。指定具体值后,temperature 为 0 时,每次生成的结果都一样
stream=False, # 数据流模式,一个字一个字地接收
response_format={"type": "text"}, # 返回结果的格式,json_object 或 text
top_p=1, # 随机采样时,只考虑概率前百分之多少的 token。不建议和 temperature 一起使用
n=1, # 一次返回 n 条结果
max_tokens=100, # 每条结果最多几个 token(超过截断)
presence_penalty=0, # 对出现过的 token 的概率进行降权
frequency_penalty=0, # 对出现过的 token 根据其出现过的频次,对其的概率进行降权
logit_bias={}, # 对指定 token 的采样概率手工加/降权,不常用
)
msg = response.choices[0].message.content
return msg















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











