







简单的多线程
一般简单的多线程主要是继承Thread或者实现Runnable接口,具体如下。
直接继承Thread类
直接继承Thread类并且覆盖重写run方法,然后new出此类使用start方法启动线程如下:public class MyThread extends Thread {
@Override
public void run() {
while(true) {
System.out.println("MyThread run()method");
}
}
public static class Test{
publicstatic void main(String[] args) {
MyThread t=new MyThread();
t.start();
}
}
}实现Runnable接口
继承Thread的坏处显而易见继承Thread后不可以继承其他类, 因为Java是单继承模式的.如下。class MyR implements Runnable{
@Override
public void run() {
System.out.println("MyRrun method");
}
}
public class MyThread {
public static void main(String[] args) {
Thread t=new Thread(new MyR());
t.start();
}
}基于ExecutorService工厂方法
ExecutorService提供了四种创建线程的方法, newCachedThreadPool,newFixedThreadPool,newScheduledThreadPool和newSingleThreadExecutor。介绍
| Executors. newCachedThreadPool() Executors. newCachedThreadPool(threadFactory) | new ThreadPoolExecutor( 0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); |
| -缓存型池子,先查看池中有没有以前建立的线程。如果有,就reuse;如果没有,就建一个新的线程加入池中。 -缓存型池子通常用于执行一些生存期很短的异步型任务。 因此在一些面向连接的daemon型SERVER中用得不多。 -能reuse的线程,必须是timeout IDLE内的池中线程,缺省timeout是60s。 超过这个IDLE时长,线程实例将被终止及移出池。 注意,放入CachedThreadPool的线程不必担心其结束,超过TIMEOUT不活动,其会自动被终止。 | |
| Executors. newFixedThreadPool(nThreads) Executors. newFixedThreadPool(nThreads, threadFactory) | new ThreadPoolExecutor( nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); |
| -newFixedThreadPool与cacheThreadPool差不多,也是能reuse就用,但不能随时建新的线程。 其独特之处:任意时间点,最多只能有固定数目的活动线程存在。 如果有新的线程要建立,只能放在另外的队列中等待,直到当前的线程中某个线程终止直接被移出池。 -和cacheThreadPool不同,FixedThreadPool没有IDLE机制。 所以FixedThreadPool多数针对一些很稳定很固定的正规并发线程,多用于服务器。 -从方法的源代码看,cache池和fixed 池调用的是同一个底层池,只不过参数不同: | |
| Executors. newSingleThreadExecutor() Executors. newSingleThreadExecutor(threadFactory) | new FinalizableDelegatedExecutorService (new ThreadPoolExecutor( 1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); |
| -单例线程,任意时间池中只能有一个线程。 -用的是和cache池和fixed池相同的底层池,但线程数目是1-1,0秒IDLE(无IDLE) | |
| Executors. newScheduledThreadPool(coreSize) Executors.newScheduledThreadPool( coreSize, threadFactory) | new ScheduledThreadPoolExecutor(corePoolSize); super( corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS, new DelayedWorkQueue(), threadFactory); |
| -调度型线程池 -这个池子里的线程可以按schedule依次delay执行,或周期执行 | |
实际Executors创建的实例均是ThreadPoolExecutor(下文有介绍),但是newScheduledThreadPool又比较特殊,因为newScheduledThreadPool返回的是ScheduledExecutorService,这个类如下:
public interface ScheduledExecutorService extends ExecutorService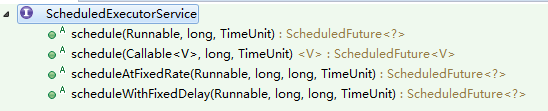
也就是说,这个ScheduledExecutorService有更为精细的调度策略。
举例
例子。
package net.jerryblog.concurrent;
public class LiftOff implements Runnable{
protected int countDown = 10; //Default
private static int taskCount = 0;
private final int id = taskCount++;
public LiftOff() {}
public LiftOff(int countDown) {
this.countDown = countDown;
}
public String status() {
return "#" + id + "(" +
(countDown > 0 ? countDown : "LiftOff!") + ") ";
}
@Override
public void run() {
while(countDown-- > 0) {
System.out.print(status());
Thread.yield();
}
}
}
使用CacaheThreadPool,如下:
package net.jerryblog.concurrent;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class CachedThreadPool {
public static void main(String[] args) {
ExecutorService exec = Executors.newCachedThreadPool();
for(int i = 0; i < 10; i++) {
exec.execute(new LiftOff());
}
exec.shutdown();
}
}上面的程序中,有10个任务,采用CachedThreadPool模式,exec没遇到一个LiftOff的对象(Task),就会创建一个线程来处理任务。现在假设遇到到第4个任务时,之前用于处理第一个任务的线程已经执行完成任务了,那么不会创建新的线程来处理任务,而是使用之前处理第一个任务的线程来处理这第4个任务。接着如果遇到第5个任务时,前面那些任务都还没有执行完,那么就会又新创建线程来执行第5个任务。否则,使用之前执行完任务的线程来处理新的任务。
使用FixedThreadPool,如下:
package net.jerryblog.concurrent;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class FixedThreadPool {
public static void main(String[] args) {
//三个线程来执行五个任务
ExecutorService exec = Executors.newFixedThreadPool(3);
for(int i = 0; i < 5; i++) {
exec.execute(new LiftOff());
}
exec.shutdown();
}
}使用ScheduledThreadPool
public class SingleThreadExecutor {
public static void main(String[] args) {
ExecutorService exec = Executors.newScheduledThreadPool(2)();
for (int i = 0; i < 5; i++) {
exec.execute(new LiftOff());
}
exec.shutdown();
}
}使用SingleThreadPool
package net.jerryblog.concurrent;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class SingleThreadExecutor {
public static void main(String[] args) {
ExecutorService exec = Executors.newSingleThreadExecutor();
for (int i = 0; i < 2; i++) {
exec.execute(new LiftOff());
}
exec.shutdown();
}
}Executor的execute()方法
execute() 方法将Runnable实例加入pool中,并进行一些pool size计算和优先级处理。
execute() 方法本身在Executor接口中定义,有多个实现类都定义了不同的execute()方法。如ThreadPoolExecutor类(cache,fiexed,single三种池子都是调用它,因为上面三种方式的实质就是使用ThreadPoolExecutor)的execute方法如下:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
else if (!addIfUnderMaximumPoolSize(command))
reject(command); // is shutdown or saturated
}
}

返回Future,调用Future的get方法,可以获取任务的返回值。从方法字面意思可以看出方法的用处和特点。
基于ThreadPoolExecutor + BlockingQueue
构造方法
ThreadPoolExecutor(int corePoolSize, int maximumPoolSize,long keepAliveTime, TimeUnit unit,BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler)
参数意义
corePoolSize: 线程池维护线程的最少数量。
maximumPoolSize:线程池维护线程的最大数量。
keepAliveTime: 在当前线程数大于corePoolSize的时候,允许线程存活时间;超时后,这个线程就会销毁。
unit: 线程池维护线程所允许的空闲时间的单位,纳秒,微妙,毫秒和秒。
workQueue: 线程池所使用的缓冲队列。
handler: 线程池对拒绝任务的处理策略。
从这些参数可以看出,ThreadPoolExecutor是一种自定义策略的灵活的线程池处理处理器,而上面提到的Executors的静态方法创建的ExecutorService实质就是利用ThreadPoolExecutor,也就是ThreadPoolExecutor是ExecutorService的实现。
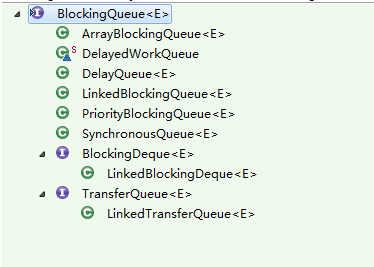
workQueue的选择
直接提交。工作队列的默认选项是 SynchronousQueue,它将任务直接提交给线程而不保持它们。在此,如果不存在可用于立即运行任务的线程,则试图把任务加入队列将失败,因此会构造一个新的线程。此策略可以避免在处理可能具有内部依赖性的请求集合时出现锁定。直接提交通常要求无界 maximumPoolSizes 以避免拒绝新提交的任务。
无界队列。使用无界队列(例如,不具有预定义容量的 LinkedBlockingQueue)将导致在所有 corePoolSize 线程都忙的情况下将新任务加入队列。这样,创建的线程就不会超过 corePoolSize。(因此,maximumPoolSize 的值也就无效了。)当每个任务完全独立于其他任务,即任务执行互不影响时,适合于使用无界队列;例如,在 Web 页服务器中。
有界队列。当使用有限的 maximumPoolSizes 时,有界队列(如 ArrayBlockingQueue)有助于防止资源耗尽,但是可能较难调整和控制。队列大小和最大池大小可能需要相互折衷:使用大型队列和小型池可以最大限度地降低CPU 使用率、操作系统资源和上下文切换开销,但是可能导致人工降低吞吐量。如果任务频繁阻塞(例如,如果它们是 I/O 边界),则系统可能为超过您许可的更多线程安排时间。使用小型队列通常要求较大的池大小,CPU 使用率较高,但是可能遇到不可接受的调度开销,这样也会降低吞吐量。
其实现如下:
handler的选择
1.在默认的 ThreadPoolExecutor.AbortPolicy 中,处理程序遭到拒绝将抛出运行时 RejectedExecutionException。
2.在 ThreadPoolExecutor.CallerRunsPolicy 中,线程调用运行该任务的 execute 本身。此策略提供简单的反馈控制机制,能够减缓新任务的提交速度。
3.在 ThreadPoolExecutor.DiscardPolicy 中,不能执行的任务将被删除。
4.在 ThreadPoolExecutor.DiscardOldestPolicy 中,如果执行程序尚未关闭,则位于工作队列头部的任务将被删除,然后重试执行程序(如果再次失败,则重复此过程)。
处理流程
当一个任务通过execute(Runnable)方法欲添加到线程池时:
l 如果此时线程池中的数量小于corePoolSize,即使线程池中的线程都处于空闲状态,也要创建新的线程来处理被添加的任务。
l 如果此时线程池中的数量等于 corePoolSize,但是缓冲队列 workQueue未满,那么任务被放入缓冲队列。
l 如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量小于maximumPoolSize,建新的线程来处理被添加的任务。
l 如果此时线程池中的数量大于corePoolSize,缓冲队列workQueue满,并且线程池中的数量等于maximumPoolSize,那么通过 handler所指定的策略来处理此任务。
也就是:处理任务的优先级为:核心线程corePoolSize、任务队列workQueue、最大线程maximumPoolSize,如果三者都满了,使用handler处理被拒绝的任务。
ThreadPoolExecutor类的execute方法如:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) {
if (runState == RUNNING && workQueue.offer(command)) {
if (runState != RUNNING || poolSize == 0)
ensureQueuedTaskHandled(command);
}
else if (!addIfUnderMaximumPoolSize(command))
reject(command); // is shutdown or saturated
}
}举例
public class CallableDemo {
publicstaticvoid main(String[] args) {
ExecutorService executorService = Executors.newCachedThreadPool();
List<Future<String>> resultList = new ArrayList<Future<String>>();
//创建10个任务并执行
for (int i = 0; i < 10; i++) {
//使用ExecutorService执行Callable类型的任务,并将结果保存在future变量中
Future<String> future = executorService.submit(new TaskWithResult(i));
//将任务执行结果存储到List中
resultList.add(future);
}
//遍历任务的结果
for (Future<String> fs : resultList) {
try {
System.out.println(fs.get()); //打印各个线程(任务)执行的结果
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
//启动一次顺序关闭,执行以前提交的任务,但不接受新任务。如果已经关闭,则调用没有其他作用。
executorService.shutdown();
}
}
}
}
class TaskWithResult implements Callable<String> {
privateint id;
public TaskWithResult(int id) {
this.id = id;
}
/**
* 任务的具体过程,一旦任务传给ExecutorService的submit方法,则该方法自动在一个线程上执行。
*
* @return
* @throws Exception
*/
public String call() throws Exception {
System.out.println("call()方法被自动调用,干活!!! " + Thread.currentThread().getName());
//一个模拟耗时的操作
for (int i = 999999; i > 0; i--) ;
return"call()方法被自动调用,任务的结果是:" + id + " " + Thread.currentThread().getName();
}
}
参考:
http://wawlian.iteye.com/blog/1315256
http://blog.csdn.net/carolzhang8406/article/details/6732570
http://blog.csdn.net/wangwenhui11/article/details/6760474
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









