






优点: 文件不限大小 , 不依赖第三方服务, 纯脚本实现, 占用资源少,不会产生内存溢出。
广大程序爱好者可以在些脚本的基础上二次开发,借助多线程或分布式调度实现TB级数据的查找。
比如: 你要在一个上百GB的大日志文件中查询2024-05-11 09: 发生的日志 。 你使用了 sed 、grep 基本上都没有戏,因为太慢了。费话不说,直接上代码:
package main
import (
"strings"
"os"
"fmt"
"bufio"
"time"
"io"
"regexp"
)
func ReadFile(fileName , startDate string) {
count := 0
base := 100000
big_line_output := false
file,err := os.Open(fileName)
if err != nil{
return
}
defer file.Close()
reader := bufio.NewReader(file)
for {
bline, isPrefix, err := reader.ReadLine()
if err == io.EOF {
break // 读取到文件结束才退出
}
// 读取到超长行,即单行超过4k字节,直接写入文件,不对此行做处理
if isPrefix {
if len(string(bline)) == 0 {
fmt.Println("empty")
}
if !big_line_output {
fmt.Println("读到超长行内容:"+string(bline))
big_line_output = true
}
count ++
if count / base > 0 && count % base == 0 {
time.Sleep(2 * 100 * time.Millisecond)
fmt.Printf("读取第: %d 行\n",count)
}
continue
}
//fmt.Println(string(bline))
count ++
//
str := string(bline)
date := MatchDate(str)
if date == "" {
}else{
if strings.HasPrefix(date, startDate){
fmt.Printf("匹配到记录:%s", str)
}
}
if count / base > 0 && count % base == 0 {
time.Sleep(2 * 100 * time.Millisecond)
fmt.Printf("读取非超长行第: %d 行\n",count)
}
}
fmt.Printf("文件总行数:%d", count)
}
// 当前行中找出日期
func MatchDate(line string) (string) {
regex := regexp.MustCompile(`\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}`)
dateMatch := regex.FindString(line)
return dateMatch
}
func main() {
start := time.Now()
ReadFile("/app/jiangpeng/tmp/runner.log","2024-05-11 09:")
elapsed := time.Since(start)
fmt.Printf("读取文件总耗时: %s", elapsed)
}
25GB、777万行日志搜索后运行效果:
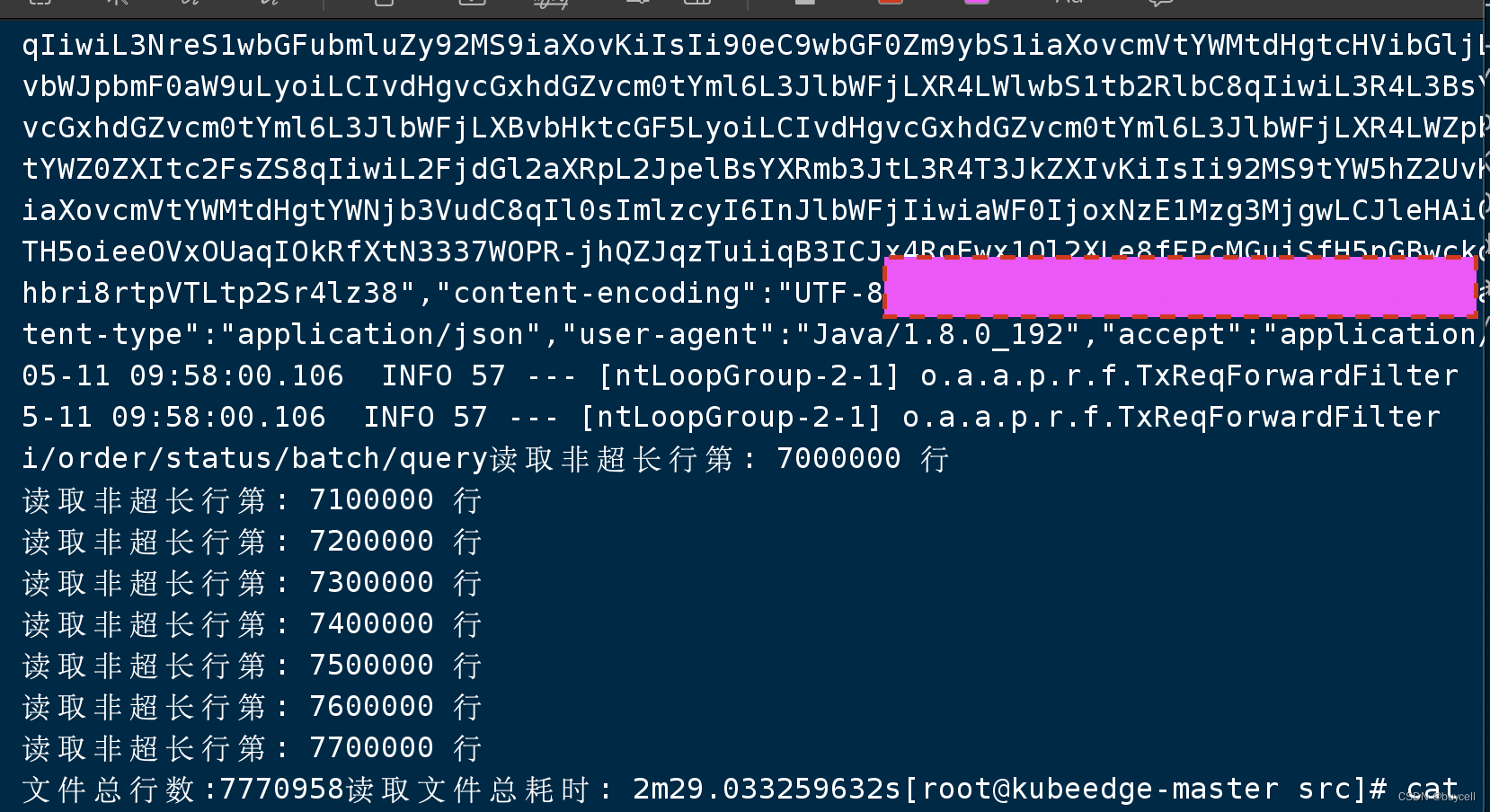
怎么样? 2分钟左右 777万行代码中完成搜索和输出,仅单机版。 效果还是很好的!















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









