






处理海量数据的时候,比如仿真的数据还要去matlab二次处理,输出的时间-应力数据要存到专门的CSV/DAT文件再用别的软件处理的时候,觉得自己是没有感情的复制粘贴机器人
正常简便方法:
比如这个是你的数据:在data manager找到对应的数据点edit然后分别单独复制X和Y就行
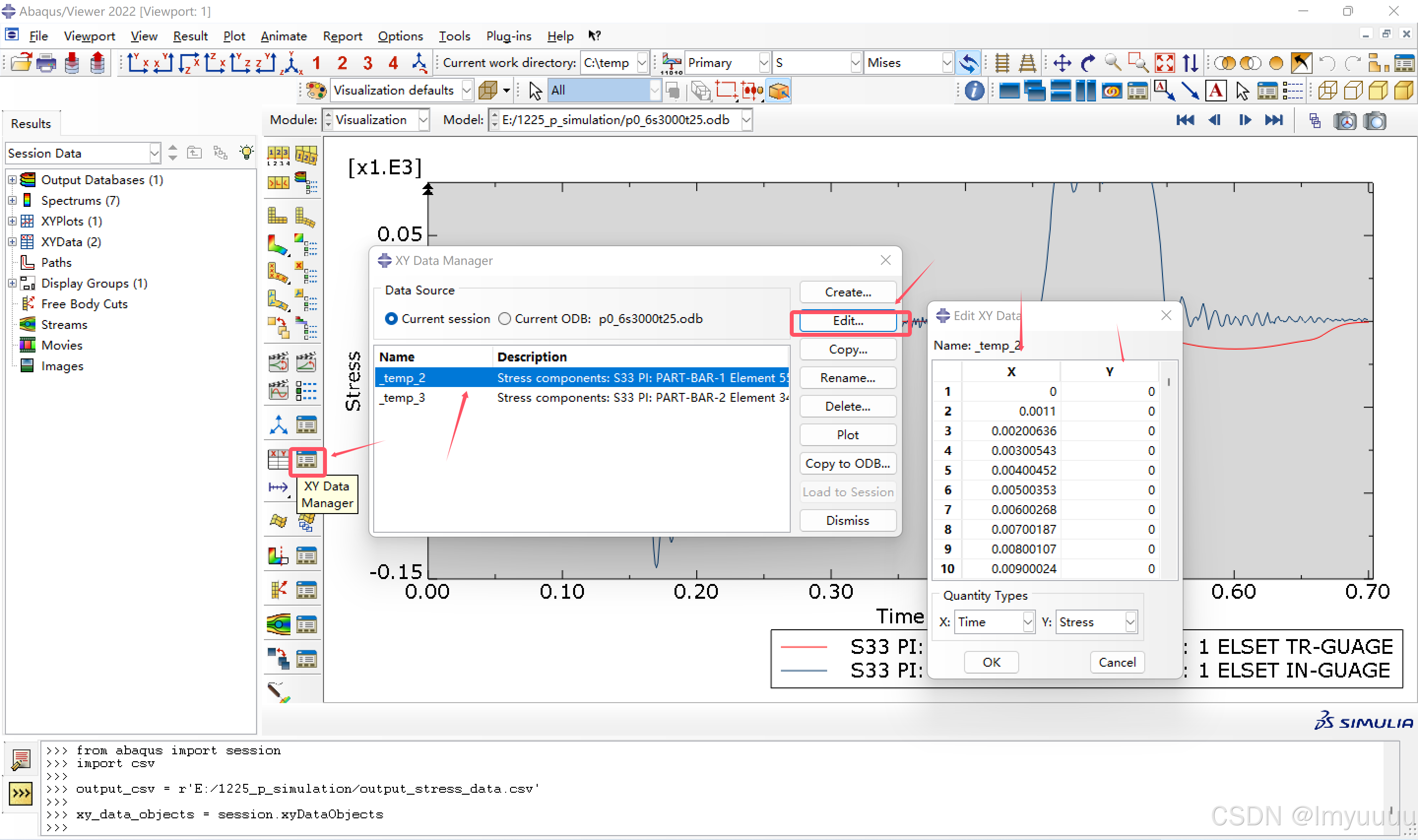
当你有100个odb以上的数据需要复制粘贴 这个方法可以说是。。
于是我想写个python脚本,如下,结果遍历时间太长,懒得一个个等,电脑还要干点别的先pass
from odbAccess import *
import csv
# 设置 ODB 文件路径和输出文件路径
odb_path = 'your_odb_file.odb' # 替换为实际路径
output_csv = 'output_stress_data.csv' # 输出的 CSV 文件路径
# 打开 ODB 文件
odb = openOdb(odb_path)
# Step 和目标单元设置
step_name = 'Step-1'
part_name = 'PART-BAR-1' # 部件名称
element_label = 55621 # 单元标签
int_point = 1 # 积分点
# 获取 Step 对象
step = odb.steps[step_name]
# 获取目标单元所在的实例
instance = odb.rootAssembly.instances[part_name]
# 根据单元标签获取目标单元
target_element = instance.getElementFromLabel(element_label)
# 打开 CSV 文件写入数据
with open(output_csv, 'wb') as csvfile:
csvwriter = csv.writer(csvfile)
# 遍历时间步
for frame in step.frames:
time = frame.frameValue # 时间
# 提取应力数据
stress_field = frame.fieldOutputs['S'] # 提取应力 FieldOutput
# 使用 getSubset 方法直接获取目标单元的数据
stress_data = stress_field.getSubset(region=target_element).values
# 查找目标积分点数据
for stress in stress_data:
if stress.integrationPoint == int_point: # 检查积分点
s33 = stress.data[2] # S33 应力分量
# 写入到 CSV 文件
csvwriter.writerow([time, s33])
from odbAccess import *
import csv
odb_path = 'your_odb_file.odb'
output_csv = 'output_stress_data.csv'
odb = openOdb(odb_path)
step_name = 'Step-1'
targets = [
('PART-BAR-2', 34914, 1, 'IN_GUAGE'),
('PART-BAR-1', 55621, 1, 'TR_GUAGE')
]
with open(output_csv, 'wb') as csvfile:
csvwriter = csv.writer(csvfile)
instances = {target[0]: odb.rootAssembly.instances[target[0]] for target in targets}
step = odb.steps[step_name]
for frame in step.frames:
time = frame.frameValue
s33_values = [time]
for part_name, element_label, int_point, elset_name in targets:
instance = instances[part_name]
target_element = instance.getElementFromLabel(element_label)
elset = instance.elementSets[elset_name]
stress_field = frame.fieldOutputs['S']
stress_data = stress_field.getSubset(region=elset, position=ELEMENT_NODAL).values
for stress in stress_data:
if stress.elementLabel == element_label and stress.integrationPoint == int_point:
s33_values.append(stress.data[2])
break
csvwriter.writerow(s33_values)
odb.close()
我寻思还不如直接将图输出成CSV,虽然要一个个打开odb文件,但是不用ctrlc和ctrlv和新建文件,优雅了一点,于是:
from abaqus import session
import csv
output_csv = r'E:/1225_p_simulation/output_stress_data.csv'
xy_data_objects = session.xyDataObjects
curve_names = list(xy_data_objects.keys())
curve1_name = curve_names[0]
curve2_name = curve_names[1]
curve1_data = xy_data_objects[curve1_name].data
curve2_data = xy_data_objects[curve2_name].data
with open(output_csv, 'wb') as csvfile:
csvwriter = csv.writer(csvfile)
for i in range(len(curve1_data)):
x = curve1_data[i][0]
y2 = curve2_data[i][1]
y1 = curve1_data[i][1]
csvwriter.writerow([x, y2, y1])
#这里是我特殊需求,我需要先输出y2列再y1,正常按自己想要的顺序改就行,而且我也是特殊需求需要去掉题头,如果需要题头如下:
from abaqus import session
import csv
# 定义输出文件路径
output_csv = r'E:/1225_p_simulation/output_stress_data.csv'
# 获取屏幕上的所有 XY 数据对象
xy_data_objects = session.xyDataObjects
# 提取两条曲线的名称
curve_names = xy_data_objects.keys()
curve1_name = list(curve_names)[0]
curve2_name = list(curve_names)[1]
# 获取两条曲线的数据
curve1_data = xy_data_objects[curve1_name].data
curve2_data = xy_data_objects[curve2_name].data
# 打开 CSV 文件以写入
with open(output_csv, 'wb') as csvfile: # 使用 'wb' 以避免空行(兼容 Python 2)
csvwriter = csv.writer(csvfile)
# 写入表头
csvwriter.writerow(['X', 'Y1', 'Y2'])
# 合并并写入数据
for i in range(len(curve1_data)):
x = curve1_data[i][0]
y1 = curve1_data[i][1]
y2 = curve2_data[i][1]
csvwriter.writerow([x, y1, y2])
在odb下面点黄色按钮这,然后改好代码粘贴在2这里,敲两下回车差不多得了,成功把生产节拍从1min提高到10s,泪目。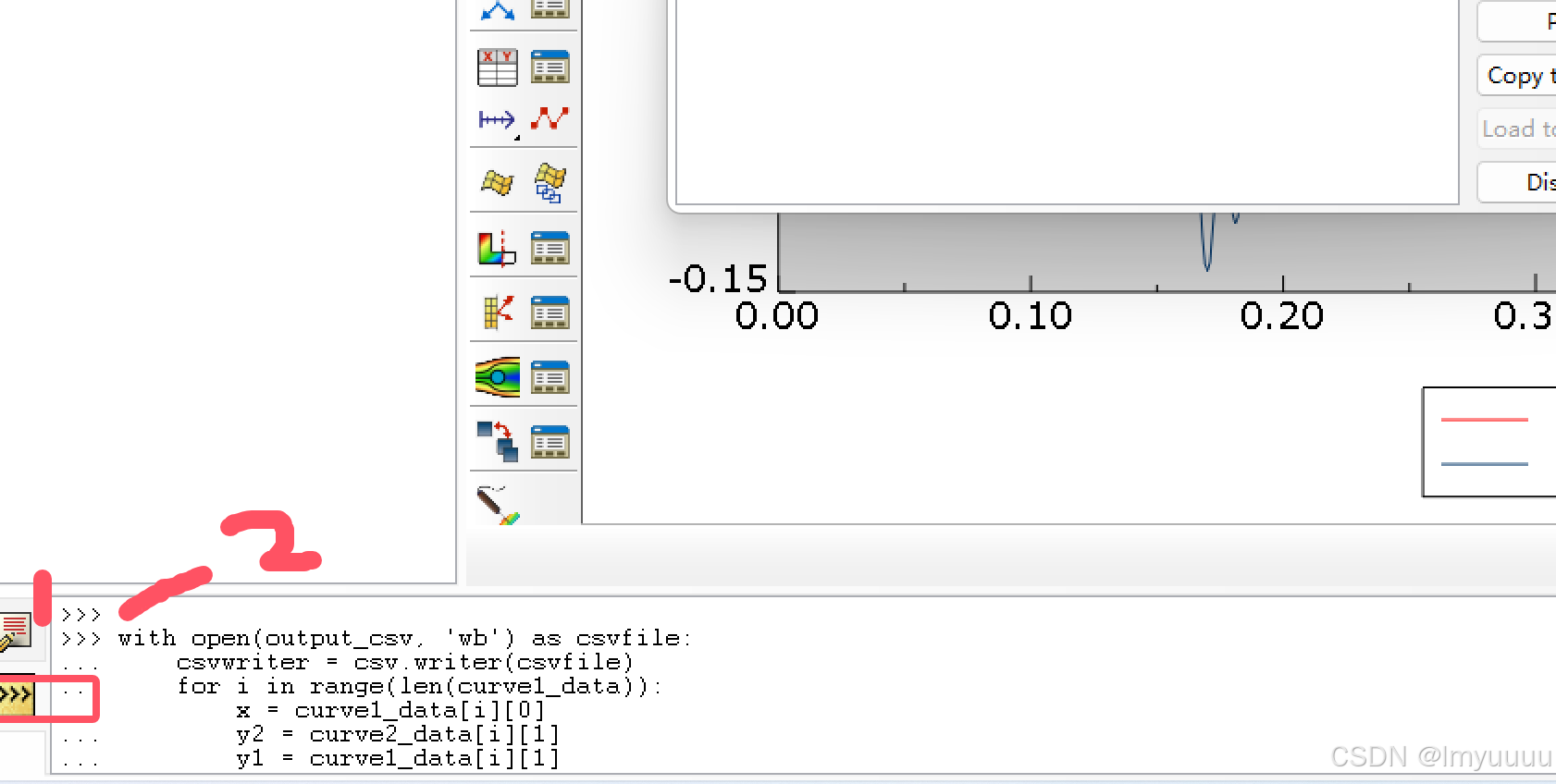


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









