




 本文深入介绍了HTTP的基础知识,包括HTTP的定义、URI、HTTP报文结构、请求方法、状态码及DNS解析过程。HTTP是一个无状态、应用层的请求/响应协议,通过URI定位资源,使用各种方法如GET、POST等进行交互。状态码分为五类,2xx表示成功,3xx表示重定向,4xx表示客户端错误,5xx表示服务器错误。DNS则是将域名解析为IP地址的系统,包括根域名、顶级域名和权威域名服务器等层次。
本文深入介绍了HTTP的基础知识,包括HTTP的定义、URI、HTTP报文结构、请求方法、状态码及DNS解析过程。HTTP是一个无状态、应用层的请求/响应协议,通过URI定位资源,使用各种方法如GET、POST等进行交互。状态码分为五类,2xx表示成功,3xx表示重定向,4xx表示客户端错误,5xx表示服务器错误。DNS则是将域名解析为IP地址的系统,包括根域名、顶级域名和权威域名服务器等层次。
本篇文章基于HTTP/1.1的RFC 7231协议标准,介绍一些基本却必备的HTTP知识,主要包括URI、HTTP报文、请求方法、响应状态码、DNS域名。由于头字段包含的内容太多,比如条件请求、范围请求、缓存控制、代理等,下一篇文章专门讲解。
需要说明的是,协议标准好比接口,Okhttp或HttpUrlConncetion就是接口的具体实现,一般而言,实现会遵循接口的规则,但是也有可能修改甚至违背标准。
HTTP的定义
The Hypertext Transfer Protocol (HTTP) is a stateless application-level request/response protocol that uses extensible semantics and self-descriptive message payloads for flexible interaction with network-based hypertext information systems.
从协议标准的定义里面我们可以看到HTTP具备的一些特点:
- 无状态(stateless):指每个请求都是互相独立、毫无关联,协议不要求客户端或服务端记录请求相关的信息。
- 应用层(application-level):位于7层或4层网络分层模型的最上层,直接面向具体应用的协议。比如除了HTTP外,还有FTP、SMTP等
- 请求-应答(request/response):永远是请求方先主动发起连接和请求,而应答方只有在收到请求后才能答复,如果没有请求那不会有任何动作。
- 自描述信息(self-descriptive message):我们总是听说HTTP是明文传输,但其实是因为最开始的HTTP是通过明文传输,因此造成我们对HTTP传输信息的误解,其实从HTTP可以很方便的转换到加密传输这点来看,HTTP传输的是自描述信息。
- 不安全:不支持身份认证和完整性校验。同样,这点也是早期HTTP暴露出来的问题,不过可以通过扩展的HTTPS进行解决。
- 简单、灵活、可扩展:比如一开始只规定了报文的基本格式,后来增加了请求方法、版本号、状态码、头字段、TLS等,还可以添加任意功能。
URI 统一资源定位符
主要用于唯一地标记资源的位置或名字。
URI格式

- scheme:协议名,表示资源应该用哪种协议来访问,比如http、https、jar、file、ftp等等。
- : // :特定的符号,不能改变。
- user:passwd@:身份信息,表示登录主机时的用户名和密码,但现在已经不推荐使用这种形式了,因为它把敏感信息以明文形式暴露出来,存在严重的安全隐患。
- authority:包含host和port,表示资源所在的主机名host必须有,port可以省略,使用默认的端口号
- path:标记资源所在位置。
- query:URI的查询参数。
- #fragment:片段标识符,它是 URI 所定位的资源内部的一个“锚点”或者说是“标签”,浏览器可以在获取资源后直接跳转到它指示的位置,仅客户端使用。
- 一个完整的例子
http://www.baidu.com:8080/user?uid=1234&name=mario&referer=xxx
URI编码
HTTP协议要求对 ASCII 码以外的字符集和特殊字符做一个特殊的操作,把它们转换成与 URI 语义不冲突的形式,被称为"escape"和"unescape",俗称"转义"。
URI 转义的规则有点“简单粗暴”,直接把非 ASCII 码或特殊字符转换成十六进制字节值,然后前面再加上一个“%”。例如,空格被转义成“%20”,“?”被转义成“%3F”。而中文、日文等则通常使用 UTF-8 编码后再转义。
HTTP报文
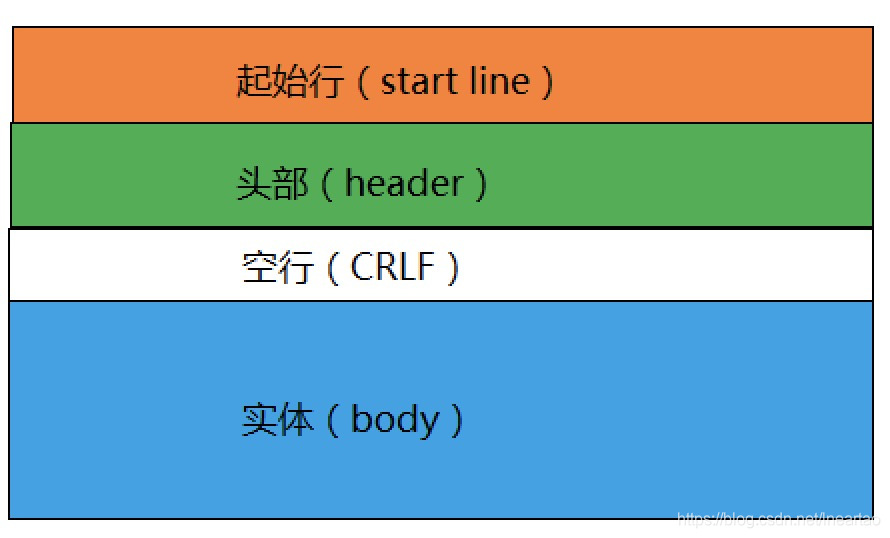
HTTP的通用报文结构如下图所示,其中请求报文对应的起始行为请求行,而响应报文对应的起始行为状态行,而且空行是分割头部和实体数据的关键,是必不可少的。
HTTP/1.1明确要求提供的头字段是Host,它必须出现在请求头里,标记虚拟主机名。
HTTP报文可以没有body,但是一定要有header,而且header后面必须有CRLF。
请求行
简要地描述了客户端想要如何操作服务器端的资源,由三个部分构成,如下图,其中SP是指空格。

- 请求方法:是一个动词,比如GET/POST,表示对资源的操作。
- 请求目标:通常是一个URI,标记了请求方法要操作的资源。
- 版本号:表示报文所使用的HTTP协议版本。
- 比如
GET / HTTP/1.1
状态行
表示服务器响应的状态,由三个部分构成,如下图

- 版本号:表示报文所使用的HTTP协议版本。
- 状态码:一个三位数,用代码的形式表示处理的结果。
- 原因:更详细的解释文字。
- 比如
HTTP/1.1 200 OK
头部
用于说明此次请求的相关信息,比如主机名、缓存、范围请求等。
头部字段是 key-value 的形式,key 和 value 之间用“:”分隔,最后用 CRLF 换行表示字段结束。比如在“Host: 127.0.0.1”这一行里 key 就是“Host”,value 就是“127.0.0.1”。如下图:

头部字段需要注意的地方:
- 字段名不区分大小写,但首字母大写可读性更好
- 字段名不允许使用空格和"_",但是可以使用"-"
- 字段名后必须紧跟":",不能有空格,但是冒号后的字段值前可以有任意空格
- 字段的顺序是没有意义的
- 字段原则上不能重复,除非这个字段本身的语义允许,比如 Set-Cookie
实体
数据类型
HTTP参考MIME来标记body的数据类型。
多用途互联网邮件扩展(Multipurpose Internet Mail Extensions),简称为 MIME。MIME共分为8大类,形式是“type/subtype”的字符串,下面列举一下常用的类型:
- text:即文本格式的可读数据,我们最熟悉的应该就是 text/html 了,表示超文本文档,此外还有纯文本 text/plain、样式表 text/css 等。
- image:即图像文件,有 image/gif、image/jpeg、image/png 等。
- audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等。
- application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有 application/json,application/javascript、application/pdf 等,另外,如果实在是不知道数据是什么类型,就会是 application/octet-stream,即不透明的二进制数据。
编码类型
HTTP在传输时为了节约带宽,有时还会压缩数据,这时需要明确编码类型,主要有三种:
- gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式
- deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
- br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
跟实体相关的头字段有 Accept、Accept-Encoding、Content-Type、Content-Encoding、Accept-Language、Content-Language、Accept-Charset、Vary,在头字段文字专门讲解。
请求方法
协议标准定义了8种方法
- GET:获取资源,可以理解为读取或下载数据
- HEAD:获取资源的元信息,没有body实体返回。使用场景,比如检查服务器是否存在某个文件,只要发个HEAD请求就好了,没必要用GET把整个文件下载下来
- POST:向资源提交数据,相当于写入或上传数据,相当于数据库的INSERT
- PUT:类似POST,相当于数据库的UPDATE
- DELETE:删除资源
- CONNECT:建立特殊的连接隧道,比如在建立HTTPS连接的隧道
- OPTIONS:列出可对资源实行的方法
- TRACE:追踪请求-响应的传输路径
- 扩展方法:MKCOL、COPY、MOVE、LOCK、UNLOCK、PATCH
注意:虽然HTTP协议定义了这些方法,但是具体的实现还是得靠客户端和服务器协商定夺。比如Okhttp默认提供了6种方法,比如GET、HEAD、POST、PUT、DELETE、PATCH,而且在进行HTTPS连接的时候会通过CONNECT方法尝试建立HTTPS隧道。
方法的属性
- 安全:指请求方法不会破坏服务器上的资源,即不会对服务器上的资源做实质性的修改。HEAD、GET、OPTION、TRACE都是是安全的。
- 幂等:多次执行相同的操作,结果也是相同的。安全方法、PUT、DELETE是幂等的。
- 可缓存:协议定义了GET、HEAD和POST是可缓存的,但大多数实现仅支持GET和HEAD。(后面会专门讲解HTTP的缓存)
状态码
表示服务器对请求的处理结果。目前 RFC 标准里规定的状态码是三位数,所以取值范围就是从 000 到 999。RFC标准顺便也把状态码进行了分类,主要有五类,用数字的第一位表示分类。
1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作
- 100 Continue:表示服务器已经接受到了请求的开始部分,没有拒绝这个请求,并且正在等着客户端发送接下来的请求。一般是客户端使用了Expect头字段的时候出现。
- 101 Switching Protocols:客户端使用 Upgrade 头字段,要求在 HTTP 协议的基础上改成其他的协议继续通信,比如 WebSocket。而如果服务器也同意变更协议,就会发送状态码 101,但这之后的数据传输就不会再使用 HTTP 了。
2××:成功,报文已经收到并被正确处理
- 200 OK:最常见的成功状态码
- 201 Created:请求已经完成,并且新建了一个或多个资源,该资源通过Location字段标记返回给客户端,跟缓存的ETag和Last-Modified字段相关。
- 202 Accepted:请求被接受,但服务器正在处理,没有完成,这个请求也许不会被服务器执行完成。
- 203 Non-Authoritative Information:请求已经完成,但是中间代理修改了源服务器发出的数据。
- 204 No Content:也是成功状态码,只是响应头后没有body数据。
- 205 Reset Content:请求已经被成功处理,但是没有返回新文档,客户端应该清空输入内容。
- 206 Partial Content:是断点续传和分片下载的基础,通常还会伴随着头字段“Content-Range”,表示响应报文里 body 数据的具体范围,供客户端确认,例如“Content-Range: bytes 0-99/2000”,意思是此次获取的是总计 2000 个字节的前 100 个字节。
3××:重定向,资源位置发生变动,需要客户端重新发送请求
- 300 Multiple Choices:多重选择。链接列表。用户可以选择某链接到达目的地。最多允许五个地址。
- 301 Moved Permanently:永久重定向,含义是此次请求的资源已经不存在了,需要改用新的 URI 再次访问,在响应头里使用字段Location指明后续要跳转的 URI。
- 302 Found:临时重定向,意思是请求的资源还在,但需要暂时用另一个 URI 来访问,在响应头里使用字段Location指明后续要跳转的 URI。
- 303 See Other:类似 302,但要求重定向后的请求改为 GET 方法,访问一个结果页面,避免 POST/PUT 重复操作。
- 304 Not Modified:用于 If-Modified-Since 等条件请求,表示资源未修改,用于缓存控制。
- 307 Temporary Redirect:类似 302,但重定向后请求里的方法和实体不允许变动,含义比 302 更明确。
- 308 Permanent Redirect:类似 307,不允许重定向后的请求变动,但它是 301“永久重定向”的含义。
4××:客户端错误,请求报文有误,服务器无法处理
- 400 Bad Request:通用的错误码,表示请求报文有错误,但具体是数据格式错误、缺少请求头还是 URI 超长它没有明确说,只是一个笼统的错误。
- 403 Forbidden:实际上不是客户端的请求出错,而是表示服务器禁止访问资源。
- 404 Not Found:资源在源服务器上未找到,所以无法提供给客户端或者是不愿意告知外部存在。
- 405 Method Not Allowed:不允许使用某些方法操作资源,例如不允许 POST 只能 GET。
- 406 Not Acceptable:资源无法满足客户端请求的条件,例如请求中文但只有英文。
- 408 Request Timeout:请求超时,服务器等待了过长的时间。
- 409 Conflict:多个请求发生了冲突,可以理解为多线程并发时的竞态。
- 410 Gone:资源在源服务器上找不到,而且这种情况是永远的。跟404有点像,所以现在基本都是用404替代。
- 411 Length Required:只响应特定长度的请求。
- 413 Request Entity Too Large:请求报文里的 body 太大。
- 414 Request-URI Too Long:请求行里的 URI 太大。
- 415 Unsupported Media Type:服务器不支持该媒体类型。
- 417 Expectation Failed:服务器不能满足客户端在请求中指定的请求头,与Expect头字段相关。
- 426 Upgrade Required:服务器拒绝服务,除非客户端根据服务器要求的协议版本进行升级,服务器会在Upgrade头字段返回要求客户端升级的协议版本,比如当前客户端使用HTTP/1.1,服务器要求使用HTTP/3.0。
- 429 Too Many Requests:客户端发送了太多的请求,通常是由于服务器的限连策略。
- 431 Request Header Fields Too Large:请求头某个字段或总体太大。
5××:服务器错误,服务器在处理请求时内部发生了错误
- 500 Internal Server Error:一个通用的错误码,服务器究竟发生了什么错误我们是不知道的,用于隐藏信息。
- 501 Not Implemented:表示客户端请求的功能还不支持。
- 502 Bad Gateway:通常是服务器作为网关或者代理时返回的错误码,表示服务器自身工作正常,访问后端服务器时发生了错误,但具体的错误原因也是不知道的。
- 503 Service Unavailable:表示服务器当前很忙,暂时无法响应服务,这是一个临时状态,所以 503 响应报文里通常还会有一个“Retry-After”字段,指示客户端可以在多久以后再次尝试发送请求。
- 504 Gateway Timeout:通常是服务器作为网关或者代理时返回的错误码,表示服务器自身工作正常,访问后端服务器时发生了超时。
- 505 HTTP Version Not Supported:服务器不支持或拒绝服务该HTTP协议版本。
DNS
网络地址是通过IP地址进行标记,比如IPv4或IPv6,但是这些数字不方便人类记忆,所以想出了把IP地址和特定的字符串映射依赖,通过某个字符串就能访问某个IP地址。增加的这个映射关系需要通过某种方式解析出来,就衍生出了DNS。
域名的形式,用“.”分隔,最右边的被称为“顶级域名”,然后是“二级域名”,层级关系向左依次递减,比如 www.baidu.com
域名的总长度限制在253个字符以内,每一级域名长度不能超过63个字符,域名是大小写无关的。
DNS的核心系统是一个三层的树状、分布式服务
- 根域名服务器: 管理顶级域名的服务器,返回“com”、“net”等顶级域名的IP地址
- 顶级域名服务器: 管理各自域名下的权威域名服务器,比如com顶级域名服务器可以返回baidu.com域名服务器的IP地址
- 权威域名服务器: 管理自己域名下主机的IP地址,比如baidu.com可以返回www.baidu.com的IP地址
除了核心系统之外,还有一类被称为非权威域名服务器,这些都是大公司或网络运行商自己建立的DNS服务器,作为用户DNS查询的代理,代替用户访问核心DNS系统,它们可以缓存之前的查询结果,如果有记录就直接返回。
如果每次网络请求都通过查询根域名服务器进行DNS查询,那么会造成网络请求慢且增加域名解析的压力,所以引入了缓存机制。主要的缓存有四级
- 客户端缓存,比如java.net.InetAddress里面就会进行DNS缓存
- 操作系统缓存,会对DNS解析结构进行缓存
- 本地hosts文件缓存,操作系统还有一个特殊的主机映射文件“/etc/hosts”,如果在操作系统缓存中找不到,那么就会来找这个文件
- 非权威域名服务器缓存
DNS的解析过程:客户端缓存 --> 操作系统缓存 --> 本地hosts文件缓存 --> 非权威域名服务器缓存 --> 根域名服务器(非缓存) --> 顶级域名服务器(com) --> 二级域名服务器地址(apple.com)。当每一级找到了目标地址会立即返回,所以有一种tricky的HTTP性能优化手段,HTTP的请求不使用域名而使用IP地址,这就绕过了DNS解析,但是这就无法享受到基于域名实现的负载均衡。

















 7747
7747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









