







一、认识spark
1、Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
2、Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。
3、尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。通过名为 Mesos 的第三方集群框架可以支持此行为。Spark 由加州大学伯克利分校 AMP 实验室 (Algorithms, Machines, and People Lab) 开发,可用来构建大型的、低延迟的数据分析应用程序。
二、安装详情
1、下载
https://archive.apache.org/dist/spark/spark-2.4.4/
 2、上传到安装包储存位置
2、上传到安装包储存位置

3、解压到安装目录
tar -xvf spark-2.4.4-bin-hadoop2.7.tgz -C /opt/module/
 4、重命名文件
4、重命名文件
mv spark-2.4.4-bin-hadoop2.7/ spark-2.4.4/

5、复制配置文件
 6、修改配置文件
6、修改配置文件
(1)spark-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_121
export HADOOP_HOME=/opt/module/hadoop-2.5.0-cdh5.3.6
export SPARK_MASTER_IP=192.168.1.101
export SPARK_WORKED_MEMORY=1g
export HADOOP_CONF_DIR=/opt/module/hadoop-2.5.0-cdh5.3.6/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/module/hadoop-2.5.0-cdh5.3.6/bin/hadoop classpath)
 (2)slaves
(2)slaves
删除之前的localhost,添加以下内容
 7、拷贝spark到另外两个节点
7、拷贝spark到另外两个节点
scp -r spark-2.4.4/ root@hadoop102:/opt/module/
scp -r spark-2.4.4/ root@hadoop103:/opt/module/
8、配置环境变量

#SPARK_HOME
export SPARK_HOME=/opt/module/spark-2.4.4
export PATH=$PATH:$SPARK_HOME/bin
export PATH=$PATH:$SPARK_HOME/sbin
使环境变量生效
source /etc/profile
9、在sbin启动spark
./start-all.sh
注意:spark
(1)启动Master
sbin/start-master.sh
(2)启动spark-shell
bin/spark-shell
(3)启动Worker
sbin/start-slave.sh spark://master的主机名:7077
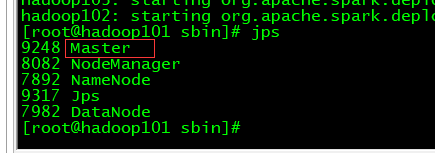
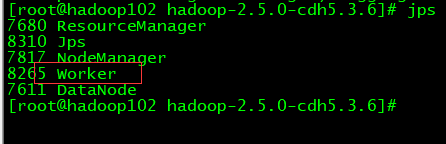
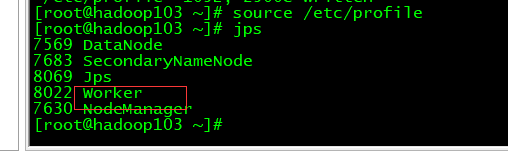
10、web端查看

11、跑一个自带的程序来测试一下,计算PI值:
./spark-submit --class org.apache.spark.examples.SparkPi --master spark://hadoop101:7077 ../examples/jars/spark-examples_2.11-2.4.4.jar 100

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









