







本次作业需要学习完transformer后完成!
目录标题
Task
做语者辨识任务,一共有600个语者,给了每一个语者的语音feature进行训练,然后通过test_feature进行语者辨识。(本质上还是分类任务Classification)
Simple(0.60824):run sample code and know how to use transformer
Medium(0.70375):know how to adjust parameters of transformer
Strong(0.77750):construct conformer
Boss(0.86500):implement self-attention pooling and additive margin softmax
助教样例code解读
数据集分析
-
mapping.json文件
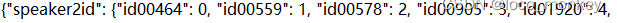
将speakers的id映射到编号0~599,因为一共有600个不同的speaker需要对语音进行分类 -
metadata.json文件
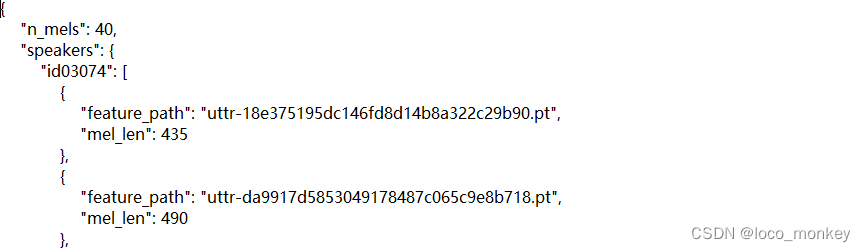
存放的是training data,本次实验没有专门设置validation data,需要从training data中划分validation data
n_mels:在对语音数据进行处理时,从每一个时间维度上选取n_mels个维度来表示这个feature
speakers:以key-value形式存放speakers的id和所有feature(每个speaker都有多个feature)
feature_path:这个feature的文件名
mel_len:每一个feature的长度(每一个可能都不一样,后期需要处理) -
testdata.json文件
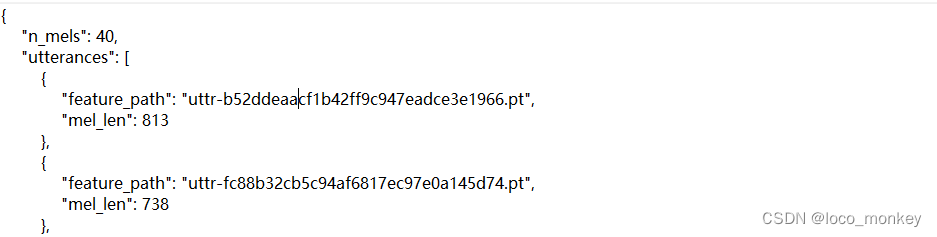
与metadata形式类似,需要我们进行语者辨识。utterance:话语; 言论
Dataset
本次实验的数据来源于 Voxceleb2语音数据集,是真实世界中语者的语音,作业中选取了600个语者,和他们的语音进行训练
import os
import json
import torch
import random
from pathlib import Path
from torch.utils.data import Dataset
from torch.nn.utils.rnn import pad_sequence
class myDataset(Dataset):
def __init__(self, data_dir, segment_len=128):
self.data_dir = data_dir
self.segment_len = segment_len
# Load the mapping from speaker neme to their corresponding id.
mapping_path = Path(data_dir) / "mapping.json" #mapping_path: Dataset\mapping.json
mapping = json.load(mapping_path.open())
#mapping: {'speaker2id': {'id00464': 0, 'id00559': 1,
self.speaker2id = mapping["speaker2id"]
#self.speaker2id: {'id00464': 0, 'id00559': 1, 'id00578': 2, 'id00905': 3,...
# Load metadata of training data.
metadata_path = Path(data_dir) / "metadata.json"
metadata = json.load(open(metadata_path))["speakers"] #metadata中存放的key是speaker_id,value是每个speaker的feature和对应长度
# Get the total number of speaker.
self.speaker_num = len(metadata.keys())
self.data = []
for speaker in metadata.keys(): #遍历每一个spearker_id
for utterances in metadata[speaker]: #通过speaker_id取出speaker的所有feature和len
"""
utterances格式:
{'feature_path': 'uttr-18e375195dc146fd8d14b8a322c29b90.pt', 'mel_len': 435}
{'feature_path': 'uttr-da9917d5853049178487c065c9e8b718.pt', 'mel_len': 490}...
"""
self.data.append([utterances["feature_path"], self.speaker2id[speaker]])
#self.data:[['uttr-18e375195dc146fd8d14b8a322c29b90.pt', 436],
# ['uttr-da9917d5853049178487c065c9e8b718.pt', 436],...
#一共600个speaker,436表示第436个speaker
def __len__(self):
return len(self.data)
def __getitem__(self, index):
feat_path, speaker = self.data[index] #feature和speaker编号[0,599]
# Load preprocessed mel-spectrogram.
mel = torch.load(os.path.join(self.data_dir, feat_path)) #加载feature
#mel.size():torch.Size([490, 40])
# Segmemt mel-spectrogram into "segment_len" frames.
if len(mel) > self.segment_len: #将feature切片成固定长度
# Randomly get the starting point of the segment.
start = random.randint(0, len(mel) - self.segment_len) #随机选取切片起始点
# Get a segment with "segment_len" frames.
mel = torch.FloatTensor(mel[start:start+self.segment_len])#截取长度为segment_len的片段 mel.size():torch.Size([128, 40])
else:
mel = torch.FloatTensor(mel) #为什么小于segment_len不填充? 填充在dataloader中完成
# Turn the speaker id into long for computing loss later.
speaker = torch.FloatTensor([speaker]).long() #将speaker的编号转为long类型
return mel, speaker
def get_speaker_number(self):
return self.speaker_num #600
Dataloader
主要任务:1.划分验证集 2.将长度小于segment_len的mel进行padding 3.生成dataloader
import torch
from torch.utils.data import DataLoader, random_split
from torch.nn.utils.rnn import pad_sequence
def collate_batch(batch): #用于整理数据的函数,参数为dataloader中的一个batch
# Process features within a batch.
"""Collate a batch of data."""
mel, speaker = zip(*batch) #zip拆包,将一个batch中的mel和speaker分开,各自单独形成一个数组
# Because we train the model batch by batch, we need to pad the features in the same batch to make their lengths the same.
#mel中元素长度不相同时,将所有的mel元素填充到最长的元素的长度,填充的值由padding_value决定
mel = pad_sequence(mel, batch_first=True, padding_value=-20) # pad log 10^(-20) which is very small value.
# mel: (batch size, length, 40)
return mel, torch.FloatTensor(speaker).long()
def get_dataloader(data_dir, batch_size, n_workers):
"""Generate dataloader"""
dataset = myDataset(data_dir)
speaker_num = dataset.get_speaker_number()
# Split dataset into training data 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









