







在嵌入式底层开发过程中,字节对齐是非常重要的,比如通常的四字节处理,这个在芯片性能上带来显著提升,减少了内存访问次数和循环控制开销。来看一个简单的例子,普通的内存拷贝(一个字节一个字节的拷贝):
void MemoryCopy(char *dest, char *src, unsigned int size)
{
if (!dest || !src || !size) return;
for (int i = 0; i < size; i++)
{
//逐字节拷贝
dest[i] = src[i];
}
}
优化版:四字节拷贝
void MemoryCopy_s(char *dest, char *src, unsigned int size)
{
if (!dest || !src || !size) return;
unsigned int i = 0;
unsigned int count = size / 4;
for (; i < count * 4; i += 4)
{
//一次拷贝四个字节
*(unsigned int *)(dest + i) = *(const unsigned int *)(src + i);
}
//处理剩余的0~3个字节
for (; i < size; i++)
{
dest[i] = src[i];
}
}
别小看这个简单的改动,这个优化在拷贝大量数据时,比如在32位处理器上,这个性能提升是非常显著的,内存拷贝速度可轻松提高百分之几百以上,它大量地减少了循环迭代次数和内存总线事务数量,更好地利用了cpu缓存。写一个测试用例,用来测试对比上面的逐字节内存拷贝MemoryCopy和优化后的四字节拷贝MemoryCopy_s之间的性能差异。
看看到底有多大的差距,如下:
#include "stdio.h"
#include "stdlib.h"
#include "string.h"
#include "time.h"
#define MEM_SIZE (20 * 1024 * 1024) //20M内存
#define CYCLE_NUMS 256 //循环次数
void TestPerformance()
{
char *src = (char *)malloc(MEM_SIZE);
char *dest1 = (char *)malloc(MEM_SIZE);
char *dest2 = (char *)malloc(MEM_SIZE);
//初始化原始内存块数据
for (int i = 0; i < MEM_SIZE - 1; i++)
{
src[i] = (char)(rand() % 256);
}
src[MEM_SIZE - 1] = '\0';
//测试逐字节拷贝性能
clock_t start = clock();
for (int i = 0; i < CYCLE_NUMS; i++)
{
MemoryCopy(dest1, src, MEM_SIZE);
}
clock_t end = clock();
double elapsedTime1 = (double)(end - start) / CLOCKS_PER_SEC;
printf("MemoryCopy: %.6fs\n", elapsedTime1);
//测试四字节拷贝性能
start = clock();
for (int i = 0; i < CYCLE_NUMS; i++)
{
MemoryCopy_s(dest2, src, MEM_SIZE);
}
end = clock();
double elapsedTime2 = (double)(end - start) / CLOCKS_PER_SEC;
printf("MemoryCopy_s: %.6fs\n", elapsedTime2);
//验证拷贝结果是否正确
printf("copy result is %s\n", (!memcmp(dest1, dest2, MEM_SIZE)) ? "correct" : "incorrect");
double enhancement = elapsedTime1 / elapsedTime2;
printf("Performance Enhancement is %.2f(%.2f%%)\n", enhancement, (enhancement - 1) * 100);
//释放内存
free(src);
free(dest1);
free(dest2);
}
int main()
{
srand((unsigned int)time(NULL));
TestPerformance();
return 0;
}
【运行结果】测试用例模拟一个20M的内存块,对其反复拷贝256次,普通的逐字节拷贝耗时11.86秒,而四字节拷贝仅耗时2.7秒,相差4.37倍,性能提升了336.71%
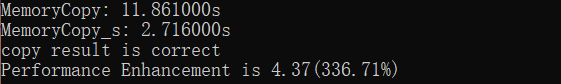
注意:测试数据与实际环境有关,仅供参考。另外,示例代码只是简单演示,并没有全面考虑架构限制、完整的四字节对齐等场景,并非完整和健壮的实现。比如,非X86环境下(某些架构Arm、MIPS),未对齐访问很有可能导致硬件异常。现代编译器的memcpy通常已经包含了这些优化。
再来看一个例子,这个写法也是大大减少了循环开销和数据相关性,允许cpu更好地利用指令级并行。
for (int i = 0; i < size; i++)
{
buf[i] = HandleData(buf[i]);
}
for (int i = 0; i < size; i += 4)
{
//循环展开,交错执行
buf[i] = HandleData(buf[i]);
buf[i + 1] = HandleData(buf[i + 1]);
buf[i + 2] = HandleData(buf[i + 2]);
buf[i + 3] = HandleData(buf[i + 3]);
}
通过展开循环的优化,外场实测可获得2倍左右的加速(数据结果与实际环境有关)。注意,这是伪代码,实际编码过程中还要注意数组buf是否可能越界,再根据实际业务适配修改。读者可根据上面的测试用例,依样画葫芦,多写几个用例来进行性能测试对比。
除此之外,还有很多,比如两个for循环要把小循环放在外层(减少跨切次数)、尽量提取和减少循环里的if条件判断、使用restrict关键字的优化、利用硬件特性(GCC的__built in_popcount内在函数)、数据预取优化__builtin_prefetch等等。
最后,再来看一个平时很常见的条件判断:
//普通
if (0 <= value && 1024 > value)
{
//do_something...
}
//优化
if ((unsigned int)value < 1024)
{
//do_something...
}
这种简单的类型转换,直接将两个比较合并为一个,因为负数转换为无符号整数会变成很大的正数,自动超出范围。这种技巧在性能关键的循环中也能带来一定的提升。当然,所有技巧还要结合实际业务来进行适配和决策。
调试环境:windows eclipse
优秀的代码不是一蹴而就的,而是多年经验和良好习惯的累积。多读,多写,多调试,多踩坑,多思考,才能厚积薄发。
文章来源公众呺 C语言算法,如有侵权,请私我联系删除。
题外话
黑客&网络安全如何学习
如果你也对网路安全技术感兴趣,但是又没有合适的学习资源,我可以把私藏的网安学习资料免费共享给你们,来看看有哪些东西。
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我们和网安大厂360共同研发的的网安视频教程,内容涵盖了入门必备的操作系统、计算机网络和编程语言等初级知识,而且包含了中级的各种渗透技术,并且还有后期的CTF对抗、区块链安全等高阶技术。总共200多节视频,100多本网安电子书,最新学习路线图和工具安装包都有,不用担心学不全。


















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









