









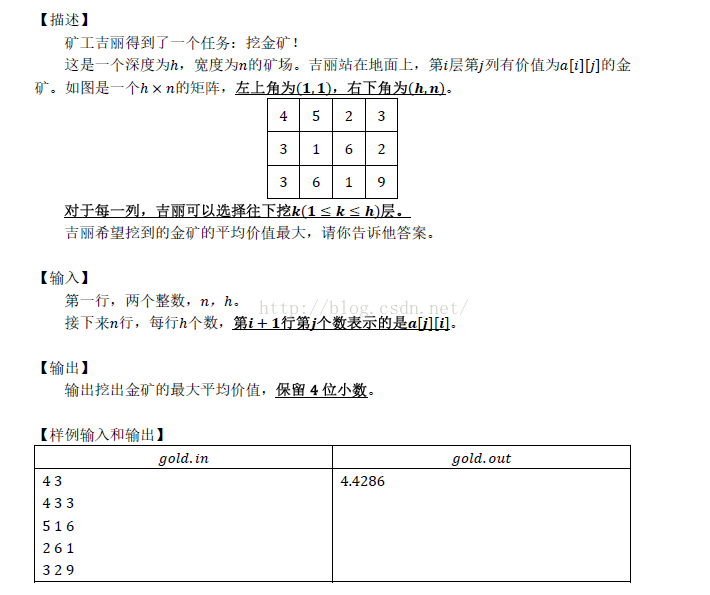
这个题目,在考场上我没有做不出来,说实话,开始的时候,我都没看出来这是个二分!这个题目因为数据范围给的很难受(n*m<=?,而不是n<=…&&m<=…),所以我们在求每一列的前缀和的时候,我们可以抽象成一维来做。
我们设答案为ans,ans=sum/h(sum为挖过的所有金矿的价值之和,h为挖过的金矿的个数)->sum-ans*h=0,基于这个式子,我们可以二分答案,在每一列取max,使得整个的答案是最优的。不断进行二分,这样就可以得出答案。
代码如下:
#include<iostream>
#include<cstdio>
#include<cstdlib>
using namespace std;
const int maxn=200005;
int num[maxn];
long long sum[maxn];
int n,h,k;
bool check(int mid)
{
double s=0,mx;
for(int i=1;i<=n;i++)
{
mx=-1e9;
for(int j=1;j<=h;j++)
mx=max(mx,(double)sum[(i-1)*h+j]-j*mid);
s+=mx;
}
if(s>=0)
return true;
else
return false;
}
int main()
{
double l=0,r=0,mid;
scanf("%d%d",&n,&h);
for(int i=1;i<=n;i++)
for(int j=1;j<=h;j++)
{
k=(i-1)*h+j;
scanf("%d",&num[k]);
if(num[k]>r) r=num[k];
if(j!=1) sum[k]=sum[k-1]+num[k];
else sum[k]=num[k];
}
while(r-l>0.000001)
{
mid=(r+l)/2;
if(check(mid))
l=mid;
else
r=mid;
}
printf("%.4lf\n",mid);
return 0;
}














 1646
1646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









