







1 引言
在这一篇文章中,将讨论一种被广泛使用的分类算法—决策树(decision tree)。相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置,因此在实际应用中,对于探测式的知识发现,决策树更加适用。
2 决策树介绍
决策树是一种机器学习的方法,决策树的生成算法有ID3, C4.5 和 C5.0 等。决策树是一种树形结构,其中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
利用决策树来进行决策的过程很像人类在面临决策问题时的一种思考模式。
决策树是一种十分常用的分类方法,需要监督学习(Supervised Learning)。监督学习就是给出一堆样本,每个样本都有一组属性和一个分类标签,也就是分类结果已知,那么通过学习这些样本得到一个决策树,这个决策树能够对新的数据给出正确的分类。
通俗来说,决策树分类的思想类似于找对象,现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策,相当于通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见。
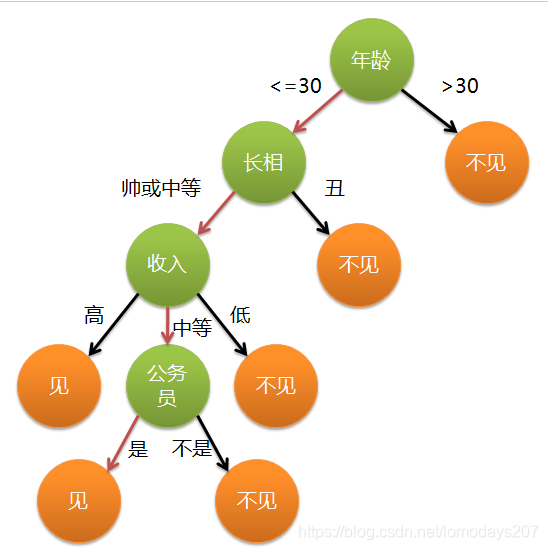
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
3 决策树的定义
有了上面直观的认识,我们可以正式定义决策树了:
1.决策树(decision tree)是一个树结构(二叉树或非二叉树)。
2.每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
3.使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
那么我们的问题来了,给你一份带分类标签的数据,怎么训练出一棵决策树?我们可以看一下上面的决策树,在决策过程中每提出的一个问题其实都是对某个属性的测试,然后沿着测试结果的分支继续测试,直到走到最终的分类结果。在每一步的测试中,我们都想通过这个测试就能得到最终的分类结果,一个极端的例子,如果能通过判断一个人的收入高低就得出是否要见的结论最好。
我们的目标是尽可能进行少的属性测试就能得到分类结果,换句话说就是每次测试都选择最优的属性测试,最优的含义就是通过这个测试能把数据集中的样本结果尽多的确定。
4 决策树的构造
决策树的生成主要分以下两步,这两步通常通过学习已经知道分类结果的样本来实现。
- 节点的分裂:一般当一个节点所代表的属性无法给出判断时,则选择将这一节点分成2个
子 节点(如不是二叉树的情况会分成n个子节点); - 阈值的确定:选择适当的阈值使得分类错误率最小 (Training Error)。
构造决策树的关键性内容是进行属性选择度量,属性选择度量是一种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式方法,它决定了拓扑结构及分裂点split_point的选择。
比较常用的决策树有ID3,C4.5 和 CART(Classification And Regression Tree),CART的分类效果一般优于其他决策树,下面介绍具体步骤。
ID3算法
从信息论知识中我们直到,期望信息越小,信息增益越大,从而纯度越高。所以ID3算法的核心思想就是以信息增益度量属性选择,选择分裂后信息增益最大的属性进行分裂。
由增熵(Entrophy)原理来决定哪个做父节点,哪个节点需要分裂,对于一组数据,熵越大说明分类结果越好。
D3算法就是在每次需要分裂时,计算每个属性的增益率,然后选择增益率最大的属性进行分裂。
C4.5算法
ID3算法存在一个问题,就是偏向于多值属性,越细小的分割分类错误率越小,所以ID3会越分越细,但是这种分割显然只对训练数据有用,对于新的数据没有意义,这就是所说的过度学习(Overfitting)。分割太细了,训练数据的分类可以达到0错误率,但是因为新的数据和训练数据不同,所以面对新数据的泛化能力就很差。
例如,如果存在唯一标识属性ID,ID的种类就比较多,则ID3会选择它作为分裂属性,这样虽然使得划分充分纯净,但这种划分对分类几乎毫无用处。
为了避免分割太细,c4.5对ID3进行了改进,C4.5中,增加的熵要除以分割太细的代价,这个比值叫做***信息增益率***,显然分割太细分母增加,信息增益率会降低。除此之外,其他的原理和ID3相同。
算法C4.5使用增益率(gain ratio)的信息增益扩充,试图克服这个偏倚。
CART算法
CART(Classification And Regression Tree)分类决策树将一个父节点分为2个子节点,是使用***基尼指数***来选择最优属性的。理想地说每一个叶节点里都只有一个类别时分类应该停止,但是很多数据并不容易完全划分,或者完全划分需要很多次分裂,必然造成很长的运行时间,所以CART可以对每个叶节点里的数据分析其均值方差,当方差小于一定值可以终止分裂,以换取计算成本的降低。
基尼GINI指数:总体内包含的类别越杂乱,GINI指数就越大(跟熵的概念很相似)。
可以想象,当我们从数据集中随机取两个样本,当这两个样本属于同一分类的概率越大,这个数据集的纯度越高,反之如果两个样本属于不同分类的概率越大,则数据集的纯度越低。基尼值就是表明随机取两个样本属于不同分类的概率,基尼值越大,数据集纯度越低。
CART和ID3一样,存在偏向细小分割,即过度学习(过度拟合问题),为了解决这一问题,对特别长的树进行剪枝处理,直接剪掉。
5 决策树总结
决策树思想,实际上就是寻找最纯净的划分方法,这个最纯净在数学上叫纯度,纯度通俗点理解就是目标变量要分得足够开(target=1的和target=0的混到一起就会不纯)。
另一种理解是分类误差率的一种衡量。实际决策树算法往往用到的是,纯度的另一面也即不纯度。不纯度的选取有多种方法,每种方法也就形成了不同的决策树方法。
比如ID3算法使用信息增益作为不纯度;
C4.5算法使用信息增益率作为不纯度;
CART算法使用基尼系数作为不纯度。
下面我们来看下sklearn上的DecisionTreeClassifier如何使用的:
#加载sklearn的自带数据集iris
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
clf = tree.DecisionTreeClassifier()
#拟合模型
clf = clf.fit(iris.data, iris.target)
#预测第一个数据的类型
#iris.data[:1, :] ——> array([[5.1, 3.5, 1.4, 0.2]])
clf.predict(iris.data[:1, :])
#array([0])
6 参考资料
1.https://www.cnblogs.com/leoo2sk/archive/2010/09/19/decision-tree.html
2.https://zhuanlan.zhihu.com/p/30059442
3.http://sklearn.apachecn.org/



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









