







 本文详细介绍了如何利用金山词霸API开发一个Android单词本项目中的英汉互译功能。从API的申请、数据请求、数据解析到实际开发,包括网络请求工具类的使用、Gson和Json格式解析、自定义控件,以及最终的程序实现。作者提供了详细的步骤和代码示例,旨在帮助初学者轻松入门。
本文详细介绍了如何利用金山词霸API开发一个Android单词本项目中的英汉互译功能。从API的申请、数据请求、数据解析到实际开发,包括网络请求工具类的使用、Gson和Json格式解析、自定义控件,以及最终的程序实现。作者提供了详细的步骤和代码示例,旨在帮助初学者轻松入门。
最近在做一个单词本的项目实战,其中涉及到一个功能,英汉互译。在众多翻译API中查找适合的API,发现金山词霸API很适合完成这样的一个功能。因为它包含发音、基本释义、例句等功能。其他API相对简单,没有发现含有例句的数据。而且金山词霸API的使用也是简单到不行,只需要申请一个Key,就可以进行查询了。
而我在使用这个API的时候遇到了很多困难,不过现在都已经完美解决。网上其他的文章对于该API的介绍和使用都非常模糊,不具体,所以,我决定自己写一篇这样的文章,来帮助更多初学者可以轻松入门。我可以保证,这篇文章讲述的信息是其他任何一篇文章都不能相比的。绝对的详细具体。
一、金山词霸API介绍
1、金山词霸API的网址是:http://open.iciba.com/?c=api ,现在也称为爱词霸。
2、API申请流程:
(1)、首先前往金山词霸API的网站。选择词霸查词。
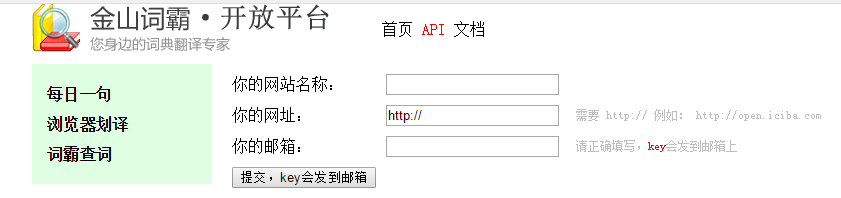
(2)、然后输入网址名称,网址和你的邮箱地址。其中,网址名称和网址可以随意填写,我们只需要获取到Key就可以了。例如:
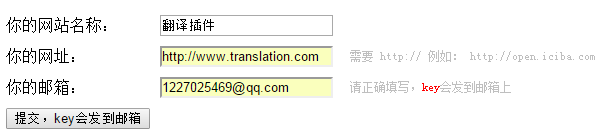
(3)点击提交按钮,你所填写的邮箱就会收到一个邮件通知,点开后就可以获取到key了。

目前的使用是不限制次数的,后期可能会有所更改。
3、请求数据
在官网上,点击文档/查词接口。
它的文档说明非常简单,甚至初学者看了之后云里雾里,不知道怎么具体使用。这就要经过一番摸索了。我进行了很多尝试,所以在这里直接把经验分享出来。
针对查词接口:返回数据默认为xml格式,可以选择json格式。但是json格式缺少例句功能,两者都需要使用key。
请求json:http://dict-co.iciba.com/api/dictionary.php?w=good&type=json&key=XXX
请求xml:http://dict-co.iciba.com/api/dictionary.php?w=good&key=XXX
其中XXX就是你刚刚申请的key,复制上去就可以了。
针对每日一词:每日一词功能是金山词霸API提供的一个非常人性化的接口,不需要使用key,直接访问即可。本程序中不会使用到该功能,但是读者可以在优化程序后添加这样的一个人性化功能,下面介绍一个如何请求数据。它默认返回json格式,可以选择xml格式,不需要使用key。
请求json:http://open.iciba.com/dsapi/?date=2018-03-09
请求xml:http://open.iciba.com/dsapi/?file=xml&date=2018-03-10
其中,date后的日期需要格式化为要求的格式,由于它返回的json格式数据非常简单,解析起来相对于xml格式数据要容易的多,一般使用第一个请求就可以了。
4、查看返回数据
返回数据按照刚才的请求网址,就可以进行访问了。英译汉以good为例,汉译英以 好 为例。
(1)、查词接口返回数据。英译汉,查询good。
①、json格式数据:
{
"word_name": "good",
"is_CRI": "1",
"exchange": {
"word_pl": ["goods"],
"word_third": "",
"word_past": "",
"word_done": "",
"word_ing": "",
"word_er": ["better"],
"word_est": ["best"]
},
"symbols": [{
"ph_en": "g?d",
"ph_am": "ɡ?d",
"ph_other": "",
"ph_en_mp3": "http:\/\/res.iciba.com\/resource\/amp3\/oxford\/0\/28\/a2\/28a24294fed307cf7e65361b8da4f6e5.mp3",
"ph_am_mp3": "http:\/\/res.iciba.com\/resource\/amp3\/1\/0\/75\/5f\/755f85c2723bb39381c7379a604160d8.mp3",
"ph_tts_mp3": "http:\/\/res-tts.iciba.com\/7\/5\/5\/755f85c2723bb39381c7379a604160d8.mp3",
"parts": [{
"part": "adj.",
"means": ["好的", "优秀的", "有益的", "漂亮的,健全的"]
}, {
"part": "n.",
"means": ["好处,利益", "善良", "善行", "好人"]
}, {
"part": "adv.",
"means": ["同well"]
}]
}]
}②、xml格式数据:
<?xml version="1.0" encoding="UTF-8"?>
<dict num="219" id="219" name="219">
<key>good</key>
<ps>g?d</ps>
<pron>http://res.iciba.com/resource/amp3/oxford/0/28/a2/28a24294fed307cf7e65361b8da4f6e5.mp3</pron>
<ps>ɡ?d</ps>
<pron>http://res.iciba.com/resource/amp3/1/0/75/5f/755f85c2723bb39381c7379a604160d8.mp3</pron>
<pos>adj.</pos>
<acceptation>好的;优秀的;有益的;漂亮的,健全的;
</acceptation>
<pos>n.</pos>
<acceptation>好处,利益;善良;善行;好人;
</acceptation>
<pos>adv.</pos>
<acceptation>同well;
</acceptation>
<sent>
<orig>
Best is the superlative form of good and worst is the superlative form of bad.
</orig>
<trans>
“best”是“good”的最高级形式,“worst” 是“bad”的最高级形式.
</trans>
</sent>
<sent>
<orig>
Good has captured the essence of the runaway, but does not pursue its most disturbing consequences.
</orig>
<trans>
Good抓住了这场失控的本质, 但没有进一步追踪这个事件最让人担忧的后果.
</trans>
</sent>
<sent>
<orig>
The state of the stream is revealed by the bad, fail, eof, and good operations.
</orig>
<trans>
流的状态由bad 、 fail 、 eof 和good操作提示.
</trans>
</sent>
<sent>
<orig>
Good Christian, good parent, good child, good wife, good husband.
</orig>
<trans>
虔诚的基督徒, 慈爱的父母, 孝顺的儿女, 贤良的妻子, 尽职的丈夫.
</trans>
</sent>
<sent>
<orig>
Good habits nurture good characters; good characters mold good fates.
</orig>
<trans>
好习惯育成好品格, 好品格塑造好命运.
</trans>
</sent>
</dict>可以清楚的看到xml格式数据比json数据多了例句数据,所以,在英译汉的功能中我们优先选择xml格式数据。
(2)、查词接口返回数据。汉译英,查询“好”。
①、json格式数据:
{
"word_id": "2143763",
"word_name": "好",
"symbols": [{
"symbol_id": "2144972",
"word_id": "2143763",
"word_symbol": "hǎo",
"symbol_mp3": "http:\/\/res.iciba.com\/hanyu\/zi\/19a73d32bf61c88bc4ed86c40f26bc9c.mp3",
"parts": [{
"part_name": "形",
"means": [{
"mean_id": "2465987",
"part_id": "2148468",
"word_mean": "good",
"has_mean": "1",
"split": 1
}, {
"mean_id": "2465988",
"part_id": "2148468",
"word_mean": "fine",
"has_mean": "1",
"split": 1
}, {
"mean_id": "2465989",
"part_id": "2148468",
"word_mean": "nice",
"has_mean": "1",
"split": 0
}]
}],
"ph_am_mp3": "",
"ph_en_mp3": "",
"ph_tts_mp3": "",
"ph_other": ""
}, {
"symbol_id": "2144973",
"word_id": "2143763",
"word_symbol": "hào",
"symbol_mp3": "",
"parts": [{
"part_name": "动",
"means": [{
"mean_id": "2465990",
"part_id": "2148469",
"word_mean": "like",
"has_mean": "1",
"split": 1
}, {
"mean_id": "2465991",
"part_id": "2148469",
"word_mean": "love",
"has_mean": "1",
"split": 1
}, {
"mean_id": "2465992",
"part_id": "2148469",
"word_mean": "be fond of",
"has_mean": "1",
"split": 0
}]
}, {
"part_name": "名",
"means": [{
"mean_id": "2465993",
"part_id": "2148470",
"word_mean": "a surname",
"has_mean": "0",
"split": 0
}]
}]
}]
}数据很长很复杂,不过不影响解析,因为有很多json数据解析的开源库可以选择,这里先卖个关子,下面会具体介绍解析json格式数据的黑科技。
②、xml格式数据:
<?xml version="1.0" encoding="UTF-8"?>
<dict num="219" id="219" name="219">
<key>好</key>
<pos></pos>
<acceptation>;;;
</acceptation>
<pos></pos>
<acceptation>;;;
</acceptation>
<pos></pos>
<acceptation>;
</acceptation>
<sent>
<orig>
That day, good clear blue light well through good good good far better abstruse!
</orig>
<trans>
那时的天, 好清好亮好透好蓝好高好远好深邃!
</trans>
</sent>
<sent>
<orig>
Good habits nurture good characters; good characters mold good fates.
</orig>
<trans>
好习惯育成好品格, 好品格塑造好命运.
</trans>
</sent>
<sent>
<orig>
It was a long , long week, and the strain was a heavy one.
</orig>
<trans>
这个星期好长好长, 那根弦绷得好紧好紧.
</trans>
</sent>
<sent>
<orig>
This country needs good farmers, good businessmen, good plumbers, good carpenters.
</orig>
<trans>
这个国家需要好的农民, 好的商人, 好的管子工, 好的木匠.
</trans>
</sent>
<sent>
<orig>
Over the past few years I have been saying , When Hong Kong succeeds, China will benefit.
</orig>
<trans>
我多年来一直讲[香港好,国家好;国家好, 香港更好].
</trans>
</sent>
</dict>可以看到xml格式数据的基本释义非常少,甚至可以说没有,但是有更丰富的例句数据,这是json数据所没有的,所以,接下来的程序设计中,我们决定json和xml数据一起解析,即发送两次网络请求,使用json数据的基本释义数据,使用xml数据的例句数据,这样汉译英的数据就完整了。
(3)、每日查词接口返回的数据
①、json格式数据:
{
"sid": "2899",
"tts": "http:\/\/news.iciba.com\ / admin\ / tts\ / 2018 - 03 - 09 - day ",
"content ": "Love is putting someone else 's needs before yours.",
"note": "爱,就是把那个人的需要,看得比自己还重要。",
"love": "2112",
"translation": "词霸小编:无论是亲情还是爱情,不都是把对方的需要放置于自己之上?不管是何种性质的爱,亘久不变的便是无私,打心底的为对方着想,始终将其摆在第一位。",
"picture": "http:\/\/cdn.iciba.com\/news\/word\/20180308.jpg",
"picture2": "http:\/\/cdn.iciba.com\/news\/word\/big_20180308b.jpg",
"caption": "词霸每日一句",
"dateline": "2018-03-09",
"s_pv": "0",
"sp_pv": "0",
"tags": [{
"id": null,
"name": null
}],
"fenxiang_img": "http:\/\/cdn.iciba.com\/web\/news\/longweibo\/imag\/2018-03-09.jpg"
}②、xml格式数据:
<?xml version="1.0" encoding="UTF-8"?>
<Document>
<sid>2899</sid>
<tts>http://news.iciba.com/admin/tts/2018-03-09-day</tts>
<content>Love is putting someone else's needs before yours.</content>
<note>爱,就是把那个人的需要,看得比自己还重要。</note>
<love>2420</love>
<translation>词霸小编:无论是亲情还是爱情,不都是把对方的需要放置于自己之上?不管是何种性质的爱,亘久不变的便是无私,打心底的为对方着想,始终将其摆在第一位。</translation>
<picture>http://cdn.iciba.com/news/word/20180308.jpg</picture>
<picture2>http://cdn.iciba.com/news/word/big_20180308b.jpg</picture2>
<caption>词霸每日一句</caption>
<dateline>2018-03-09</dateline>
<s_pv>0</s_pv>
<sp_pv>0</sp_pv>
<tagid></tagid>
<tag></tag>
<fenxiang_img>http://cdn.iciba.com/web/news/longweibo/imag/2018-03-09.jpg</fenxiang_img>
</Document>二、开始开发程序
数据准备充分之后就可以开始编写程序了。当然,我们还需要进行一些准备工作。
1、开发工具准备
(1)、网络请求工具类
由于程序中会使用到网络请求功能,为了日后拓展,也就是为了程序的可扩展性增加,我们不能每次使用网络请求都写一遍请求代码。这些东西都是可以封装到工具类中的,使用的时候调用一下即可。这里我推荐一个非常好用的开源库OkHttp。
新建项目:TranslateAPP,所有默认,选择空的活动。
OkHttp的项目主页地址是:https://github.com/square/okhttp
使用OkHttp库,我们需要添加库依赖,使用Android Studio,在project模式下,编辑app/build.gradle文件。在dependencies闭包中添加以下内容:
compile 'com.squareup.okhttp3:okhttp:3.10.0'然后在项目名下New→package,建立一个名为util的包。在该包下新建一个HttpUtil的类。
编写以下代码:
import okhttp3.OkHttpClient;
import okhttp3.Request;
public class HttpUtil {
/**
* 使用OkHttp网络工具发送网络请求
* */
public static void sendOkHttpRequest(String address,okhttp3.Callback callback){
//创建OkHttpClient对象
OkHttpClient client = new OkHttpClient();
//创建Request对象,装上地址
Request request = new Request.Builder().url(address).build();
//发送请求,返回数据需要自己重写回调方法
client.newCall(request).enqueue(callback);
}
}使用时,调用请求方法,重写回调函数即可,如:
HttpUtil.sendOkHttpRequest(url, new Callback() {
@Override
public void onFailure(@NonNull Call call, @NonNull IOException e) {
//返回数据失败时的处理逻辑
}
@Override
public void onResponse(@NonNull Call call, @NonNull final Response response) throws IOException {
//返回数据成功时的处理逻辑
}
});在接下来的程序中,你会看到它的具体使用方法。
(2)、建立javaBean、及解析工具介绍
解析json数据的时候需要使用到javaBean(实体类)吗?当然是不一定的,不过我们决定使用更简单的解析方式就需要使用到这样的一个实体类。我们需要将上面介绍到的json数据的每一个属性都设置到javaBean当中,可能面对这么多属性已经心生退意了,不过不用担心,我们使用黑科技来解决。
①、使用Gson解析json数据
Gson解析json数据简直简单到了不能想象的地步,它将json数据字符串格式化为对应的Bean对象,我们需要什么数据,就去对应的实体类对象中get就可以了。是不是超级简单。比起json的一段一段解析简单的多。同样,使用Gson需要添加Gson的库依赖,在app/build.gradle文件中添加以下依赖:
compile 'com.google.code.gson:gson:2.8.2'使用时只需要两行代码:
Gson gson = new Gson();
Bean bean = gson.fromJson(dataString,Bean.class); 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2345
2345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









