









本文由 @lonelyrains 出品,转载请注明出处。
文章链接: http://blog.csdn.net/lonelyrains/article/details/48931697
可以用最小二乘法形式的代价函数(当然也有其他形式),求最小值来做。
单变量的时候,代价函数随着自变量的变化而变化,变化轨迹是代价函数-参数的二维坐标的一个下凸的抛物线;双变量时,是代价函数-参数1-参数2的弓形曲面。
人工找代价函数的最值点不现实,所以提出了梯度下降法(gradient decent),其实就是同时将所有参数更新为初始参数值的偏导数方向差。

可以参考高等数学中多参数光滑函数求极值点的方法。
多元线性梯度下降 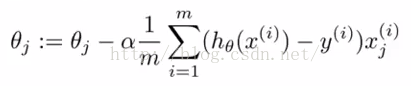
线性梯度的快速收敛:
1、属性缩放:通过基本的加减乘除转换,将x(i)j的取值范围尽量都约束到[-1,1]的区间,避免路径来回震荡,快速收敛 取值范围归一化
xj=(xj-μj)/s 其中xj为变量值,μj为xj取值的均值,s=max(xj)-min(xj)。
2、通过选择不同的α,看曲线状态:如果是固定迭代次数时的代价函数的最小值随着迭代次数有波浪或者增大,则说明α取值过大;如果曲线收敛比较慢,则说明α取值太小。
可以总结出一种动态调整α的方法. 原α值的3的倍数递增或者递减















 2485
2485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









