






一、背景简介
个人搭建服务部署后,服务的文件图片等数据需要支持容灾备份,以下是常见的解决方案:
- 将数据手动/自动备份到当前服务器的其他目录中。
- 将数据手动/自动备份到局域网内的其他服务器。
- 将数据手动/自动备份到客户私有云存储服务。
- 将数据手动/自动备份到共有云存储服务。
为了降低开发和运维成本,我们需要为以上备份场景制定通用解决方案。
常用的开源分布式文件系统有:TFS(GPL-2.0 license)、HDFS(Apache License 2.0)、MooseFs(GPL-2.0 license)、FastDfs(GPL-3.0 license)、GridFs、MinIO(AGPL-3.0 license)、SeaweedFS(Apache-2.0 license)、GlusterFS(GPL-2.0, LGPL-3.0 licenses)、Ceph(relicense LGPL-2.1 code as LGPL-2.1 or LGPL-3.0)等。
从功能上看,只有Ceph、MinIO 和 SeaweedFS 提供了 Cloud Tier 和 AWS-S3 API,比较方便备份到云存储,最符合我们要求。其中 Ceph功能强大,但是配置复杂,运维成本较高;MinIO 使用和部署都比较简单,且自带多租户功能,但是使用了 AGPL-3.0 license,该协议传染性较强,不适合我们的场景。故最终以 SeaweedFS 调研为主。
二、SeaweedFS 功能介绍
SeaweedFS 是一款简单、高伸缩的分布式文件系统,最大的特点就是支持10亿级文件快速存取,文件查询时间复杂度为O(1)。系统逻辑架构如下:
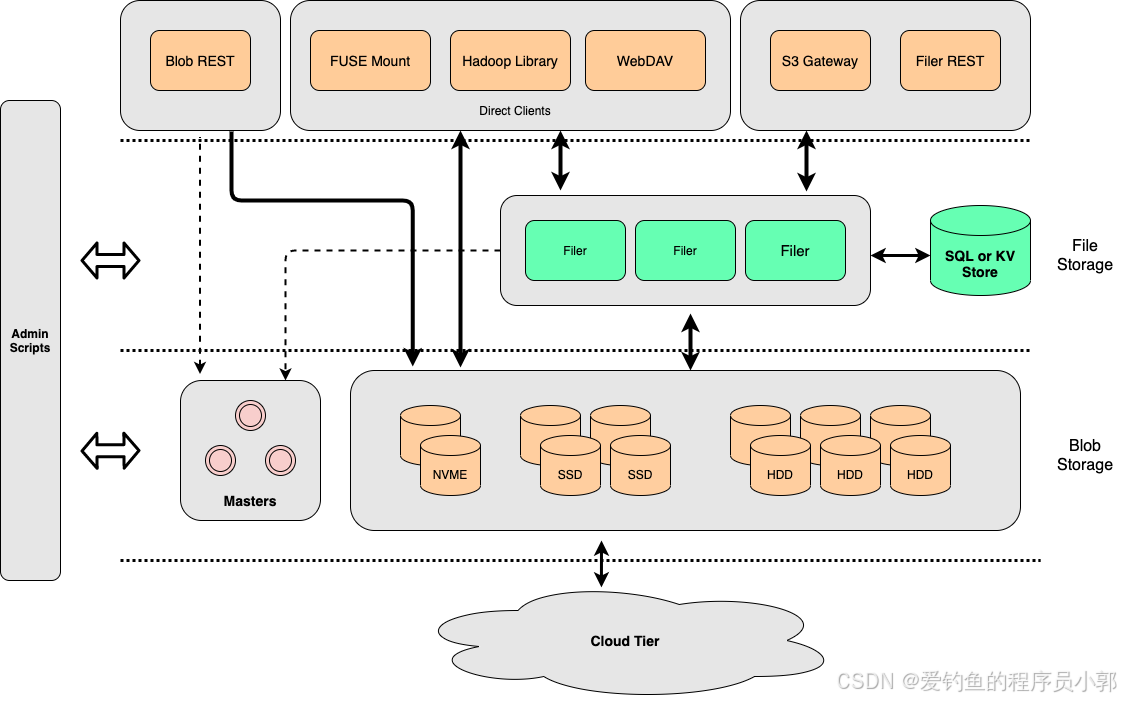
SeaweedFS 在部署上采用元数据和数据分离的存储方式,元数据存储在 Master 节点中,具体文件数据存储在 Volume 节点中,另外集群也支持选配 Filer 服务,Filer 服务提供了具体业务场景的抽象,封装Master 和 Volume 使其更加易用和更容易与客户现有系统集成。
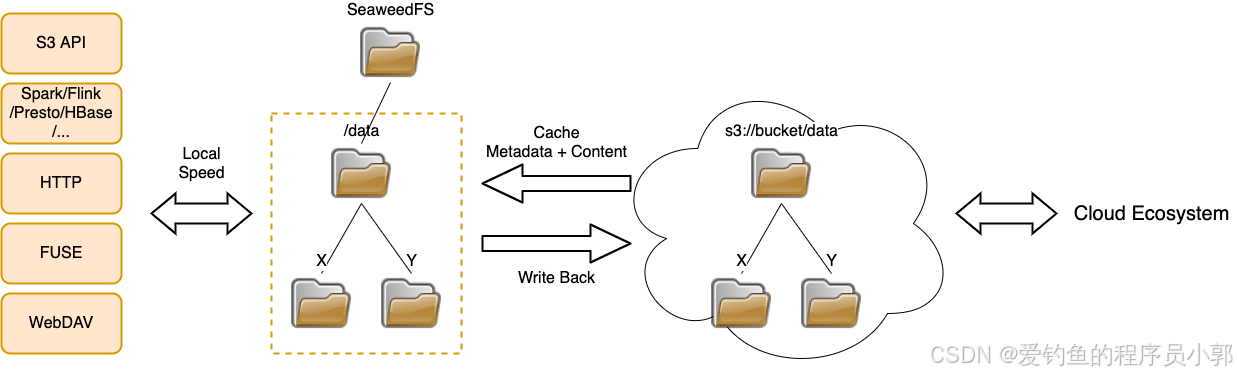
SeaweedFS 支持数据自动同步到云存储,该操作过程会客户端透明,当客户端读写文件时,默认会操作本地文档,当本地文件不存在时,会自动读取云存储文件。架构如下:
基于docker搭建
Docker Compose 如下:
version: '3.9'
services:
master:
image: chrislusf/seaweedfs # use a remote image
ports:
- 9333:9333
- 19333:19333
- 9324:9324
command: "master"
volume:
image: chrislusf/seaweedfs # use a remote image
ports:
- 8080:8080
- 18080:18080
- 9325:9325
command: 'volume -mserver="master:9333" -port=8080 -publicUrl=localhost:8080'
depends_on:
- master
filer:
image: chrislusf/seaweedfs # use a remote image
ports:
- 8888:8888
- 18888:18888
- 9326:9326
command: 'filer -master="master:9333"'
tty: true
stdin_open: true
depends_on:
- master
- volume
s3:
image: chrislusf/seaweedfs # use a remote image
ports:
- 8333:8333
- 9327:9327
command: 's3 -filer="filer:8888"'
depends_on:
- master
- volume
- filer启动命令如下:
docker-compose -f docker/seaweedfs-compose.yml -p seaweedfs up写入文件序列图
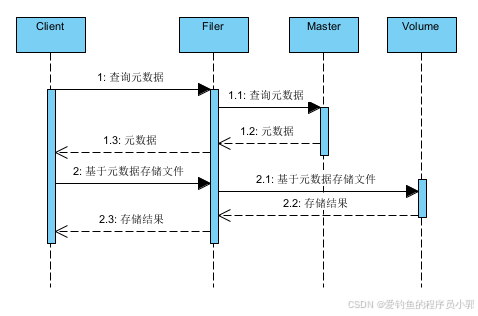
第一步查询元数据返回结果如下:
{"count":1,"fid":"3,01637037d6","url":"172.16.0.2:8080","publicUrl":"localhost:8080"}其中fid中的格式为 <volume id, file key, file cookie>,逗号之前的3表示文件存储在 id 为 3 的 volume 中,是一个 32-bit 无符号整数,key 为 64-bit 无符号整数,cookie 为 32-bit 无符号整数。
第二步基于元数据存储文件时,可以指定使用url、publicUrl 或者 Filer Url来查询,默认使用url,这三种 url 是彼此独立的命名规则。
查询文件序列图
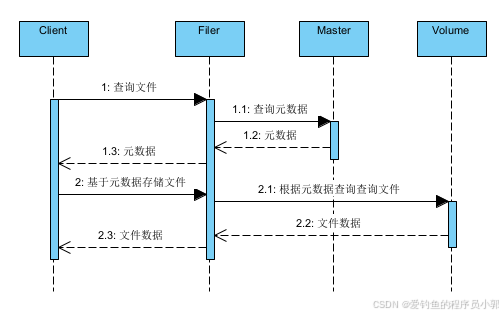
在查询文件时,第一步需要根据 volumeId 查询 volume 服务的地址,结果如下:
{"volumeId":"3","locations":[{"publicUrl":"localhost:8080","url":"172.16.0.2:8080"}]}第二步基于元数据查询存储文件时,可以指定使用url、publicUrl 或者 Filer Url来查询,默认使用url,这三种 url 是彼此独立的命名规则。
访问数据文件时以下链接功能等同:
http://localhost:8080/3/01637037d6/my_preferred_name.jpg
http://localhost:8080/3/01637037d6.jpg
http://localhost:8080/3,01637037d6.jpg
http://localhost:8080/3/01637037d6
http://localhost:8080/3,01637037d6源码仓库
注意事项:在创建Client时需指定使用Volume的具体地址,否可能网络不通
总结
SeaweedFS 主要优势
性能比较强大:核心理论依据是基于 Facebook's Haystack design paper,该paper的目标也是解决facebook内部图片视频等数据的存储查询问题。
架构设计比较灵活: 系统设计参照了Facebook’s Tectonic Filesystem,特别是几个核心组件的设计,抽象的比较好,非常方便扩展不同的实现,并且整体架构上可以水平扩容,没有明显的瓶颈点。
功能齐全:存储比较关心的冷热分离,弹性云存储,TTL等功能都有支持。
部署简单:部署非常简单,很容易上手。
SeaweedFS 的不足
对 S3 Api 支持不完整:实现了大部分的常用接口,部分非常用接口未实现,不过影响不大,比如Canned ACL等。
缺少多租户的能力:缺少多租户的概念,所以如果支持用户都把数据存储到我们的云存储服务,则需要自己做二次开发。
问题解答
问题:
- 文件的分层安全机制;
- 一个桶的不同账户,不能互相访问文件;
- 文件数量支持
解答:
- SeaweedFS 采用元数据和实际数据分离的方式,接口对外暴露的只是元数据中的 fid,其 fid 的机制可以在一定程度上防止暴力破解;实际数据存储在不同的桶里,并支持对存储文件进行加密处理。
- SeaweedFS 没有提供多租户概念,所以一个桶的不同账户需要在业务层做权限隔离。
- SeaweedFS 支持集群部署和备份,可以支持亿级文件存储。


















 1565
1565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











