







https://www.nowcoder.com/profile/7838045/myFollowings/detail/3445247
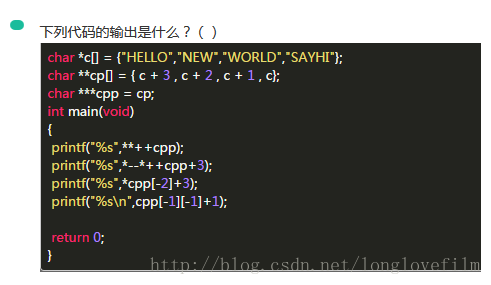

链接:https://www.nowcoder.com/questionTerminal/087006d1e4ff46ca927c812294facbc4
来源:牛客网
一)
1 友元函数和友元类均可以访问private \protected成员;
2 友元函数和友元类能够引用类中的private \protected成员,但是在其内部引用时必须通过对象引用,比如函数体中a.x,b.x,a.y,b.y都是类的私有成员,他们是通过对象引用的。
3 友元函数在外部调用时,不需要通过基类的对象 “ . ” 或者对象指针 “-> ” 来调用,因为它是一个普通函数,不是类成员函数,调用跟普通函数方式一样;
4 友元函数在基类外部定义,且定义时不需要加 :: 符号。
5 友元函数和友元类在基类内部声明时在哪个位置都一样,包括public\private\protected位置;二
int a={1,2,3,4}; int *p=(int *)((int)a+1); P指向了什么?
1. int a = {}; 貌似应该是int a[] = {};
2. "(int)a",已经把a的地址强转成int型数字(32bit),所以“((int)a+1); ”实际指向了整个数组内存块的第二个地址,即a[0]的第二个字节。所以p的指向就向前移动了一个字节,指向了a【0】的第二个字节的地址。
三
剑指offer T48
四
1 char pData[] = "i am a student."; char *pData = "i am a student.";
后者字符串如果为指针型表示,则此字符串为const类型,不可以更改此字符串内容,但是前者数组的形式可以。
比如char *func(char *pData) 此函数的指针输入参数只能选择前者char pData[] = "i am a student."; 选择后者作为参数会出错!!
五-1
class Base {
public:
virtual void f() { cout << "Base::f" << endl; }
virtual void g() { cout << "Base::g" << endl; }
virtual void h() { cout << "Base::h" << endl; }
};
class Derive :public Base
{
public:
void f() { cout << "Derive::f1" << endl; }
void g1() { cout << "Derive::g1" << endl; }
virtual void h1() { cout << "Derive::h1" << endl; }
};
虚函数的多态性只发生在指针或者引用调用的情况下!!!!!!!看下面运行的对比例子!!
Base *b1 =& b;
b1->f(); ///Derive::f1
Base b1 =b;
b1.f(); ///Base::f
五-2
class Base {
public:
Base()
{
f();
}
virtual void f()
{
cout <<" gouzao base" << endl;
}
};
class Derived :public Base
{
public:
Derived()
{};
void f()
{
cout << "gou zao derived" << endl;
}
};
int main()
{
Base *p = new Derived;
p->f();
system("pause");
return 0;
}
输出结果 gouzao base
gou zao derived
在一开始调用构造函数的时候,运行构造函数前,对象还没有生成,更谈不上调用动态类型了!!尽管对象是个derived,但是构造基类部分时,还只是个base,所以会调用基类的虚函数f().
五-3
class Base {
public:
Base()
{
f();
}
virtual void f()
{
cout << " gou zao base" << endl;
}
~Base()
{
cout << "base~" << endl;
f();
}
};
class Derived :public Base
{
public:
Derived()
{};
void f()
{
cout << "gou zao derived" << endl;
}
~Derived()
{
cout << "derived~" << endl;
f();
}
};
int main()
{
Base *p = new Derived;
p->f();
delete p;//注意此时应该是如果析构函数不是虚函数,只掉用基类析构函数,我看输出结果,此时f() 也是只掉用基类的f()" gou zao base",不涉及继承类的多态问题!!
p = NULL;
system("pause");
return 0;
}
基类指针指向继承类时,此时当用基类指针delete, 需要将析构函数设置为virtual函数形式,否则只会调用基类的析构函数,不会调用派生类对象自身的析构函数!
(类中的静态函数不可以设置为虚函数,因为虚函数都是通过具体对象的虚函数表来实现的, 而静态函数不属于具体对象,自然没有虚函数表,它在创建具体对象之前就已经存在了!)
六
int
main(){
unsigned
char
a=
0xA5
;
unsigned
char
b=~a>>
4
+
1
;
printf(
"%d\n"
,b);
return
0
;
}
所以优先级顺序是:~、+大于>>大于=,先做a的取反操作,然后4+1为5,然后~a>>5,然后赋值给b
下面,如果按照我们的常识,a取反右移5位应该是2才对,但是答案是250,对250分析可知,当~a右移时,前面补的是1,而不是0,为什么呢?
因为,无论是unsigned char,还是unsigned short、short、char等,都是转换成int来处理的,一般情况下,int为32位,所以a取反后是ffffff5a,右移5位,前面补1(最高位为1,在计算机中认为是负数,补1,如果是unsigned int型的变量的话,前面补0),最后转化成unsigned char型,所以取后8位是fa,即250
七
面试题:构造函数
#include <iostream>
using namespace std;
class Base
{
private:
int i;
public:
Base(int x)
{
i = x;
}
};
class Derived : public Base
{
private:
int i;
public:
Derived(int x, int y)
{
i = x;
}
void print()
{
cout << i + Base::i << endl;
}
};
int main()
{
Derived A(2,3);
A.print();
return 0;
}
首先,是访问权限问题,子类中直接访问Base::i是不允许的,应该将父类的改为protected或者public(最好用protected)
其次,统计父类和子类i的和,但是通过子类构造函数没有对父类变量进行初始化;此处编译会找不到构造函数,因为子类调用构造函数会先找父类构造函数,但是没有2个参数的,所以可以在初始化列表中调用父类构造函数
最后个问题,是单参数的构造函数,可能存在隐式转换的问题,因为单参数构造函数,和拷贝构造函数形式类似,调用时很可能会发生隐式转换,应加上explicit关键字
#include <iostream>
using namespace std;
class Base
{
protected:
int i;
public:
explicit Base(int x)
{
i = x;
}
};
class Derived : public Base
{
private:
int i;
public:
Derived(int x, int y):Base(x)
{
i = y;
}
void print()
{
cout << i + Base::i << endl;
}
};
int main()
{
Derived A(2,3);
A.print();
return 0;
}
2、初始化列表
1)使用初始化列表提高效率
class Student
{
public:
Student(string in_name, int in_age)
{
name = in_name;
age = in_age;
}
private :
string name;
int age;
};
因为在构造函数中,是对name进行赋值,不是初始化,而string对象会先调用它的默认构造函数,再调用string类(貌似是basic_string类)的赋值构造函数;对于上例的age,因为int是内置类型,应该是赋值的时候获得了初值。
要对成员进行初始化,而不是赋值,可以采用初始化列表(member initialization list)
class Student
{
public:
Student(string in_name, int in_age):name(in_name),age(in_age) {}
private :
string name;
int age;
};
在初始化的时候调用的是string的拷贝构造函数,而上例会调用两次构造函数,从性能上会有不小提升
有的情况下,是必须使用初始化列表进行初始化的:const对象、引用对象
2)初始化列表初始顺序
#include <iostream>
using namespace std;
class Base
{
public:
Base(int i) : m_j(i), m_i(m_j) {}
Base() : m_j(0), m_i(m_j) {}
int get_i() const
{
return m_i;
}
int get_j() const
{
return m_j;
}
private:
int m_i;
int m_j;
};
int main()
{
Base obj(98);
cout << obj.get_i() << endl << obj.get_j() << endl;
return 0;
}
输出为一个随机数和98,为什么呢?因为对于初始化列表而言,对成员变量的初始化,是严格按照声明次序,而不是在初始化列表中的顺序进行初始化,如果改为赋值初始化则不会出现这个问题,当然,为了使用初始化列表,还是严格注意声明顺序吧,比如先声明数组大小,再声明数组这样。
C++构造函数初始化按下列顺序被调用:
- 首先,任何虚拟基类的构造函数按照它们被继承的顺序构造;
- 其次,任何非虚拟基类的构造函数按照它们被继承的顺序构造;
- 最后,任何成员对象的构造函数按照它们声明的顺序调用;
#include <iostream>
using namespace std;
class OBJ1{
public:
OBJ1(){ cout<<"OBJ1\n"; }
};
class OBJ2{
public:
OBJ2(){ cout<<"OBJ2\n";}
}
class Base1{
public:
Base1(){ cout<<"Base1\n";}
}
class Base2{
public:
Base2(){ cout <<"Base2\n"; }
};
class Base3{
public:
Base3(){ cout <<"Base3\n"; }
};
class Base4{
public:
Base4(){ cout <<"Base4\n"; }
};
class Derived :public Base1, virtual public Base2,public Base3, virtual public Base4//继承顺序{
public:
Derived() :Base4(), Base3(), Base2(),Base1(), obj2(), obj1(){//初始化列表
cout <<"Derived ok.\n";
}
protected:
OBJ1 obj1;//声明顺序
OBJ2 obj2;
};
int main()
{
Derived aa;//初始化
cout <<"This is ok.\n";
return 0;
}
结果:
Base2 //虚拟基类按照被继承顺序初始化
Base4 //虚拟基类按照被继承的顺序
Base1 //非虚拟基类按照被继承的顺序初始化
Base3 //非虚拟基类按照被继承的顺序
OBJ1 //成员函数按照声明的顺序初始化
OBJ2 //成员函数按照声明的顺序
Derived ok.
This is ok.
八
C++中如果子类一个变量与基类的某个变量重名了怎么办?如果B中有同名成员,则会使得父类的同名成员不可见(需要通过名空间访问),此时函数中的a实际上指B中的a,访问父类中的a需要通过A::来访问。
九
cout<<2^3<<endl;//error 运算符优先级不对应该为
cout<<(2^3)<<endl;
十
*(&a[0][0]+5)
*(*(a+1)+1)
*(&a[1]+1)*(a[1]+1)
在VS中编译,输出a[1]和&a[1]的地址是一样的,但是a[1]+1和&a[1]+1却不一样,这是为什么呢?
int a[2][4] = { { 2, 5, 6, 8 }, { 22, 55, 66, 88 } };
int c[4] = { 5, 8, 9, 4 };
int d[3] = { 23, 12, 443 };
int *p[4], (*q)[4];
//(我不明白为什么q=a可以,然而 p=a不可以!!答谢可否告知!!只是因为p作为第一个int数组不确定大小,但是a作为第一个数组首地址已经确定了数组大小是4个4,维的吗??)
q = a;
*p = c;
p[0] = c;
*(p + 1) = d;
p[1] = d;
int i, j;
for (i = 0; i<2; i++)
for (j = 0; j<4; j++)
{
if ((i == 1) && (j == 3)) break;
printf("*(*(p+%d)+%d)=%d\n", i, j, *(*(p + i) + j));
}
puts("===============");
for (i = 0; i<2; i++)
for (j = 0; j<4; j++)
printf("*(*(q+%d)+%d)=%d\n", i, j, *(*(q + i) + j));
cout << p[1][1] << endl;
cout << *(*(p + 1) + 1) << endl;
int *p[4]与int (*q)[4]的区别
以上定义涉及两个运算符:“*”(间接引用)、“[]”(下标),“[]”的优先级别大于“*”的优先级别。
首先看int*p[4],“[]”的优先级别高,所以它首先是个大小为4的数组,即p[4];剩下的“int*”作为补充说明,即说明该数组的每一个元素为指向一个整型类型的指针。int*p[4]的存储结构如下:(存储方格横向排列或竖向排列没区别,只要按内存地址顺序排列就行,此处只是为画图方便)
![int <wbr>*p[4]与int <wbr>(*q)[4]的区别](https://i-blog.csdnimg.cn/blog_migrate/455410a10646b6173f3e15b56fc28f8a.jpeg "int <wbr>*p[4]与int <wbr>(*q)[4]的区别")
再看int (*q)[4]。它首先是个指针,即*q,剩下的“int [4]”作为补充说明,即说明指针q指向一个长度为4的数组。int(*q)[4]的存储结构如下:
![int <wbr>*p[4]与int <wbr>(*q)[4]的区别](https://i-blog.csdnimg.cn/blog_migrate/1ef4bd9008384e524be9547783a4b617.jpeg "int <wbr>*p[4]与int <wbr>(*q)[4]的区别")
请看以下定义:
int a[2][4]={{2,5,6,8},{22,55,66,88}};
int c[4]={5,8,9,4};
int d[3]={23,12,443};
int *p[4],(*q)[4];
q=a;
*p=c;
*(p+1)=d;
则int *p[4]和int (*q)[4]的存储数据为:
![int <wbr>*p[4]与int <wbr>(*q)[4]的区别](https://i-blog.csdnimg.cn/blog_migrate/cb847894c4693b90903fdeb063f8d922.jpeg "int <wbr>*p[4]与int <wbr>(*q)[4]的区别")
![int <wbr>*p[4]与int <wbr>(*q)[4]的区别](https://i-blog.csdnimg.cn/blog_migrate/dc827148e4d924acd5430af139f44534.jpeg "int <wbr>*p[4]与int <wbr>(*q)[4]的区别")















 630
630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









