










本文档仅供参考,实际部署或许有些许出入,请自行调整
文档链接:石墨文档《参考文档》
部署软件的版本、下载地址及说明(持续更新):
| 软件 | 版本 | 官网 | 说明 |
|---|---|---|---|
| OpenJDK | 11.x | OpenJDK | Java 环境 |
| R(可选) | 4.1.x | R | SparkR 编程 |
| Python (可选) | 3.10.x | Python | PySpark 编程 |
| Scalar | 2.12.x | Scala | Spark 原生支持语言 |
| Apache Hadoop | 3.3.x | Apache Hadoop | 分布式环境 |
| Apache Zookeeper | 3.7.x | Apache Zookeeper | 集群节点管理 |
| Apache Hbase | 2.4.x | Apache Hbase | 分布式非关系型数据库 |
| Apache Spark | 3.1.x | Apache Spark | 大数据分析工具 |
| Boost C++ Library | 1.79.0 | Boost C++ Library | C++ 编译库 |
| Apache Thrift | 0.16.0 | Apache Thrift | Hbase 多语言服务 |
| Apache Phoenix | 5.1.2 | Apache Phoenix | Hbase SQL 支持 |
| Phoenix Query Server | 6.0.0 | Query Server | Hbase SQL 查询服务 |
| Apache Kafka | 3.2.0 | Apache Kafka | 消息队列服务 |
官网下载地址速度较慢时,可选择国内镜像地址:
阿里云镜像,清华大学镜像,中科大镜像
一、准备集群环境
选择并安装服务器镜像
镜像选择
Ubuntu:获取Ubuntu服务器版 | Ubuntu
CentOS 7:The CentOS Project
作为实验环境,可以使用虚拟机安装镜像
如果是云平台,可以选择平台提供的公共镜像
本文档以 Ubuntu 22 作为示例镜像
镜像安装
1. 硬件配置
虚拟机镜像安装,以 VMware 15 为例:
选择:创建新虚拟机 -> 典型 -> 稍后安装操作系统
-> Linux: Ubuntu 64 位 或 CentOS 7 64位
-> 输入虚拟机名称,选择镜像路径
-> 按需要选择硬盘大小(建议 40G 以上),为了便于克隆虚拟机,选择将虚拟硬盘拆分成多文件
确定硬件配置后,将生成一个不带镜像的空白虚拟机
在虚拟机界面,选择“编辑虚拟机设置”,用户可以在这里更改虚拟机硬件配置
选择“CD/DVD(SATA)”在右侧连接选择“使用 ISO 映像文件”来定位虚拟机系统镜像
确定配置后,开启虚拟机时将安装镜像,以 Ubuntu 22 为例:
选择 Install Ubuntu Server,等待安装完成后,选择语言:English
选择键盘界面:Chinese,选择默认配置安装:Ubuntu Server
2. 网络配置
配置网卡选项:在 Linux 系统中,网卡名称一般为 ens33 (旧版本可能为 eth0)
选择:ens33 -> Edit IPv4 编辑 IPv4 地址 -> 将选项从 DHCP 自动分配改为 Manual 手动配置
Subnet 子网IP —— 如:192.168.127.0/24
Address IP地址 —— 如:192.168.127.11
Gateway 网关IP —— 如:192.168.127.2
(192.168.127.1 已经被 VMware 虚拟网卡所使用)
Name servers DNS服务器地址 —— 免费公共 DNS 服务器大全
Search domains 域名 —— 可留空,根据情况填写
同时在 VMware 菜单 -> 编辑 -> 虚拟网络编辑器中,将 VMnet8 配置更改为 “NAT 模式”(需要管理员权限),按照虚拟机中的网卡配置编辑 IP 地址,子网掩码(/24 = 255.255.255.0),在 NAT 设置中编辑网关 IP,点击应用保存配置
注:Ubuntu 22 手动配置网卡:
sudo vim /etc/netplan/00-installer-config.yaml # 修改网卡配置文件
network:
ethernets:
ens33:
dhcp4: false
addresses: [192.168.127.11/24] # IP地址
nameservers:
addresses: [223.6.6.6,223.5.5.5,192.168.1.1] # DNS 地址
routes:
- to: default
via: 192.168.127.2 # 网关
version: 2
sudo netplan apply # 加载网卡配置
3. 其他配置
在虚拟机中按需要填写 HTTP 代理 IP 地址,填写镜像源地址,选择默认存储布局与文件系统
确认配置,填写用户姓名,主机名,用户名及密码(用以登录与联机)
选择安装 OpenSSH 服务(用以与其他主机进行免密登录),安装组件或稍后按需手动安装
之后等待安装完成即可
远程连接
服务器一般会通过远程连接软件进行登录,文档以 Xshell 为例进行说明:
Xshell 和 Xftp 下载:Xshell and Xftp Free Licensing
打开 Xshell,将会弹出会话窗口与选项卡,点击新建,填写会话名称,主机(IP 地址)
在左侧点击“用户身份验证”,填写用户名及密码,点击确定并进行远程连接
Linux 服务器配置
目录结构
基本指令
文件与目录管理
文件编辑
文件基本属性
Redhat、CentOS 的 Yum 命令
Debian、Ubuntu 的 Apt 命令
用户与用户组管理
指令速查表:
(遇到需要使用的命令,查询此处即可)
ls # 列出当前目录下文件名
ls -l 或 ll # 列出当前目录下文件详细信息
ls -a 或 la # 列出当前目录下的隐藏文件,以 '.' 开头
ls -l 或 ll [link] # 查看文件链接(快捷方式)来源
ln -s [target] [link] # 创建文件链接
ln -snf [target] [link] # 修改链接
cd [dir] # 切换到指定目录
mkdir -p [dir] # 创建目录
vim [file] # 编辑文件
# i 插入,d 删除行,:q 退出,:wq! 强制写入退出,:nohl 取消高亮
cat [file1] >> [file2] # 将 file1 内容追加写到 file2 中
echo [content] >> [file] # 将内容追加写到 file 中
chown -R [user]:[group] [dir] # 更改目录所有者及所属用户组
chmod xyz [file|dir] # 对文件或目录赋予权限
# [x][y][z]
# rwxrwxrwx
# u 创建者 g 组 o 其他用户 a 所有用户
# r 读 w 写 x 执行 + 增加权限 - 去除权限
find [path] [file] # 在指定路径下查找文件
whereis [name] # 查找安装目录
tar -xzvf [name].tar # 解压到当前目录
tar -cvf [name].tar [dir] # 压缩指定目录
# z:.gz x:解压 c:压缩 v:显示详细 f:使用压缩包名称
sudo apt [install|remove|list installed|search] [package] (| grep [keyword])
# 在仓库中安装|移除|查看|关键词搜索 软件包
who # 查看当前登录用户
compgen -u # 查看所有用户
useradd (-[c|d|m|g|G|s|u|o]) [user] # 创建用户
# c 注释 d 指定目录 m 创建主目录
# g 指定用户组 G 指定附加组 s 指定登录Shell
# u 指定用户号 o 使用其他用户的标识号
usermod (-[c|d|m|g|G|s|u|o]) [user] # 修改用户
userdel -r [user] # 删除用户及其主目录
passwd (-[l|u|d|f]) [user] # 密码管理
# l 锁定密码 u 解锁密码 d 删除密码
# f 强迫用户下次登录时修改密码
groupadd (-[g|o]) [group] # 创建用户组
# g 指定用户组号 o 使用其他用户组的标识号
groupmod (-[g|o|n]) [group] # 修改用户组
# n 新用户组名
groupdel [group] # 删除用户组
newgrp [group] # 在多个用户组间切换
su -l [user] # 切换用户,默认为 root
sudo -u [user] [command] # 以某用户执行命令,默认为 root
exit # 退出当前用户
env # 查看环境变量
vim /etc/profile.d/[filename].sh # 添加环境变量
export [envname]=[envpath] # 根据具体需求添加
export PATH=$PATH:[envname] # 将环境变量添加到 PATH 路径下
source /etc/profile # 执行 profile 文件,加载环境变量
top # 任务管理器
jps # 查看 JAVA 当前运行的进程
netstat -ntlp | grep [port] # 查看监听指定端口的 TCP socket
lsof -i:[port] # 查看监听指定端口的进程
kill -9 [pid] # 强制结束进程号为 pid 的进程
systemctl [start|stop|enable|disable|status] [service]
# 开启|关闭|自启动|禁止启动|查看 服务
nohup [shell] >/dev/null 2>&1 & # 后台执行指令
# 将默认会生成日志文件,使用 >/dev/null 2>&1 将日志输出文件置空
jobs -l # 显示后台命令与进程号
fg %[pid] # 将后台进程转向前台
kill -s SIGINT %[jobs id] # 结束暂停进程
配置安装源
Ubuntu 使用 apt 命令,从远程仓库下载 deb 软件包并安装,默认仓库地址:cn.archive.ubuntu.com
,根据需要可以进行更换,仓库文件在 /etc/apt/sources.list 中,使用 Tab 键提示名称,使用复制指令 cp 对文件进行备份:
cp /etc/apt/sources.list /etc/apt/sources.list.backup
使用 vim 对文件进行编辑(对系统文件进行操作时,需要管理员权限 sudo):
sudo vim /etc/apt/sources.list # 编辑文件
i # 切换为插入模式
:wq! # 文件选项(:)强制(!)写入(w)并退出(q)
sudo apt update # 更新安装源
将文件内容替换为 清华大学开源镜像站 或 中科大镜像站 文件内容
安装 Java
java -version # 查看 JAVA 安装情况
sudo apt install openjdk-11-jdk-headless # 安装指定版本 JAVA
whereis java # 查找 JAVA 安装路径
sudo vim /etc/profile.d/java.sh # 创建 JAVA 环境变量
export JAVA_HOME=[Java 安装路径]
export PATH=$JAVA_HOME/bin:$PATH
:wq!
source /etc/profile # 加载环境变量
配置 SSH 与集群免密登录
1. IP 地址映射
hostnamectl # 查看主机名
sudo vim /etc/hosts # 修改 hosts 文件
192.168.127.11 node01 # 将 ip 地址映射到主机名 node01
ping node01 # 测试,ctrl+c 停止命令
2. 虚拟机克隆
关闭虚拟机,右键需要克隆的虚拟机 -> 管理 -> 克隆 -> 创建完整克隆,等待克隆完成即可
虚拟机克隆后,需要对新节点重新配置IP地址,主机名与 IP 地址映射,重新生成 SSH 密钥
再次连接会话时,显示新主机名
3. 时间同步
timedatectl # 查看时区
sudo timedatectl set-timezone Asia/Shanghai # 将时区调整到上海
sudo apt install chrony # 安装 chrony
chrony 分为服务端和客户端,服务端负责为其他服务器提供同步时间
客户端负责将本地时间与服务端时间进行同步
sudo vim /etc/chrony/chrony.conf
# server [NTP server] iburst <minpoll [min] maxpoll [max]>
# 添加上层 NTP 服务器,可指定最小和最大查询间隔(单位为 2 的 n 次方秒)
#(默认 NTP 服务器同步时间较慢,可以删除或注释)
server ntp.ntsc.ac.cn minpoll 4 maxpoll 10 iburst
server ntp.aliyun.com minpoll 4 maxpoll 10 iburst
server cn.ntp.org.cn minpoll 4 maxpoll 10 iburst
local stratum 10 # 公网 NTP 不可用时,采用本地时间作为 NTP
allow IP [addr/24] # 只允许某网段对本机进行时间同步
makestep [n] [m] # 当误差大于 n 秒时,在前 m 次更新中调整时钟
rtcsync # 启用 RTC 实时时钟进行内核同步
sudo systemctl start chronyd
sudo systemctl enable chrony.service # 开启 chrony 服务并设置自启动
# 注:Ubuntu 系统开启服务自启动时需要服务全名,可以通过 status 查看
sudo chronyc -a makestep # 手动同步
sudo chronyc sources -v # 查看时间同步源
sudo chronyc sourcestats -v # 查看时间同步源状态
sudo hwclock -w # 调整硬件时间与本机同步
date # 查看时间
sudo hwclock # 查看硬件时间
4. 配置 SSH
Ubuntu 默认安装了 OpenSSH,通过以下指令查看SSH服务是否存在并启动:
sudo systemctl status sshd # 查看 SSH 服务状态
如果服务不存在,也可通过以下指令安装 OpenSSH,然后开启与自启动服务:
sudo apt install openssh-server
sudo systemctl start sshd
sudo systemctl enable ssh.service
OpenSSH 将在 /home/[user] 目录下创建 .ssh 目录和 .ssh/authorized_keys 文件,若不存在也可以手动创建并赋予 700 和 600 权限:
mkdir ~/.ssh # '~' = '/home/[user]'
vim ~/.ssh/authorized_keys
:wq!
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys
修改 /etc/ssh/sshd_config SSH 配置文件,取消或修改如下注释:
sudo vim /etc/ssh/sshd_config
PermitRootLogin yes # 允许管理员登录
PubkeyAuthentication yes # 允许公钥认证
PasswordAuthentication yes # 允许密码认证
AuthorizedKeysFile .ssh/authorized_keys .ssh/authorized_keys2
# 指定授权密钥文件目录
sudo systemctl restart sshd # 重启 ssh 服务以加载配置
执行以下指令生成 SSH 密钥:
ssh-keygen -t rsa # 创建 RSA 密钥
ll ~/.ssh
将会询问密钥存放目录及设置密钥密码,按 Enter 键使用默认设置,会在 .ssh 目录下生成私钥 id_rsa 及公钥 id_rsa.pub 文件,使用以下指令将公钥文件追加写到 authorized_keys 文件中:
cat id_rsa.pub >> authorized_keys
集群分发 authorized_keys 文件并将各主机自身的公钥追加到该文件下:
(确保所有节点的公钥都在 authorized_keys 文件中)
scp -r [user]<@[host]>:[file|dir] <[user]@>[host]:[dir]
# 集群分发文件或目录
ssh-copy-id -i [user]<@[host]>:[file|dir] <[user]@>[host]
# 或者将本机公钥追加到远程 authorized_keys 上
5. 服务器安全
参考 SElinux 或 AppArmor 的文档说明
二、部署分布式计算环境
Apache Hadoop
Apache™ Hadoop® 项目为可靠,可扩展的分布式计算开发开源软件
Apache Hadoop 软件库是一个框架,允许使用简单的编程模型跨计算机集群分布式处理大型数据集。
它旨在从单个服务器扩展到数千台计算机,每台计算机都提供本地计算和存储。
该库本身不是依靠硬件来提供高可用性,而是旨在检测和处理应用程序层的故障,从而在计算机群集之上提供高可用性服务,每个计算机群集都可能容易出现故障。
架构
1. HDFS
Hadoop Distributed File System 负责架构平台的分布式存储系统,为运行 MapReduce 任务时,分发代码和资源做准备
2. YARN
架构在 HDFS 之上的资源调度系统,负责调度各节点资源,任务的分发及合并
3. MapReduce
计算框架及编程模型,以 JAR 包的形式提交,Hadoop 便会执行 MapReduce 任务
部署 Hadoop
Hadoop 3.2.3: Setting up a Single Node Cluster
(更改地址栏上的版本选择你想查看的说明)
解压文件
tar zxvf apache-hadoop-bin-x.y.z.tar.gz # 解压
rm -f apache-hadoop-bin-x.y.z.tar.gz # 清理压缩包
mv apache-hadoop-bin-x.y.z hadoop-x.y.z # 更改文件夹名字,便于索引
配置环境变量
sudo vim /etc/profile.d/hadoop.sh # 创建 hadoop 环境变量文件
export HADOOP_HOME=[Hadoop 安装路径]
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
:wq!
source /etc/profile # 加载环境变量
1. 独立模式 —— Standalone
在服务器上单独运行其中的 MapReduce jar 包,使用以下语句用于调试:
hadoop jar [jarPath] [mainClass] [indir] [outdir] [grep]
2. 伪分布式 —— Pseudo-Distributed
Hadoop 配置文件目录 hadoop/etc/hadoop 中有如下文件:
core-site.xml # Hadoop 集群核心配置
hdfs-site.xml # HDFS 配置
yarn-site.xml # YARN 配置
mapred-site.xml # MapReduce 配置
workers # 集群工作节点列表
hadoop-env.sh # hadoop 环境变量配置
配置 Hadoop
vim core-site.xml # 编辑 core-site.xml 文件
# 有若干属性名(name)和值(value)
fs.defaultFS # Hadoop 主服务器 hdfs 通信地址
# 以 hdfs:// 开头,一般与 NameNode 地址相同,端口默认从 9000 开始
# 默认为 hdfs://localhost:9000
hadoop.tmp.dir # hadoop 临时文件目录
# 默认为 /tmp/hadoop-[user]
Linux 会定期删除 /tmp 下的文件
如果想保存 Hadoop 运行时产生的文件,请自定义文件路径并修改用户权限
sudo chmod 775 [hadoop.tmp.dir]
sudo chown [user]:[group] [hadoop.tmp.dir]
core-site.xml 示例:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://node01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-node</value>
</property>
</configuration>
配置 HDFS
vim hdfs-site.xml # 配置 HDFS Namenode Datanode Journalnode 相关参数
dfs.replication # HDFS 数据备份数量,一般与节点数相同
dfs.namenode.http-address # NameNode 地址,默认端口 9870
dfs.namenode.name.dir # NameNode DFS 目录,也是数据存储目录
# 默认为 [hadoop.tmp.dir]/dfs/name
dfs.datanode.data.dir # DataNode DFS 目录
# 默认为 [hadoop.tmp.dir]/dfs/data
hdfs-site.xml 示例:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>node01:9870</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop-node/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop-node/dfs/data</value>
</property>
</configuration>
可在官方文档左侧查看默认配置说明
格式化 NameNode
配置完成后,在 hadoop 主服务器 NameNode 节点上进行格式化(DataNode 节点无需格式化):
hdfs namenode -format
# 在 NameNode 节点格式化分布式文件系统(DFS)
日志显示 successfully formatted 即格式化成功,将创建 dfs 等目录,可通过 tree 命令查看
sudo apt install tree # 安装 tree
tree [hadoop.tmp.dir] # 查看 Hadoop 文件目录结构
注:NameNode 通过 Cluster ID 辨识所有节点
多次格式化或克隆 NameNode 节点等操作将会导致 Cluster ID 冲突,导致格式化或启动失败
需要删除 [dfs.namenode.name.dir], [dfs.datanode.data.dir] 和 [hadoop.tmp.dir] 目录
使 Cluster ID 重新生成,而在生产环境中,则需要将 NameNode 节点中
VERSION 文件里的 Cluster ID 值覆盖到其他节点对应的 Cluster ID 中
[hadoop.tmp.dir]/dfs/data/current/VERSION
启动 Hadoop
start-dfs.sh # 启动 HDFS (NameNode+DataNode+JournalNode)
start-yarn.sh # 启动 YARN (ResourceManager+NodeManager)
start-all.sh # 或者全部启动 HDFS+YARN
stop-dfs.sh # 关闭 HDFS
stop-yarn.sh # 关闭 YARN
stop-all.sh # 或者全部关闭
jps # JAVA 进程中将会出现 NameNode 与 DataNode
对于部分故障节点,查看 HADOOP 日志 $HADOOP_LOG_DIR/*.log,日志目录默认为 $HADOOP_HOME/logs,也可使用如下命令单独启动:
hdfs --daemon start [namenode|datanode|journalnode|...]
# 启动 HDFS 指定节点类型
yarn --daemon start [resourcemanager|nodemanager|...]
# 启动 YARN 指定节点类型
hdfs dfsadmin -report # 查看节点报告
NameNode 默认 web 界面: http://localhost:9870/
基本命令
hdfs dfs -[command] [hdfsDir] # 在 HDFS 指定目录中执行指定操作
hdfs dfs -mkdir -p /user # 在 HDFS /目录中创建 user 目录
hdfs dfs -rm -r -f /user # 在 HDFS 删除 /user 目录
hdfs dfs -put [filepath] [hdfsDir] # 将本机文件上传到 HDFS 指定目录中
hdfs dfs -get [filepath] [hdfsFileDir] # 下载 HDFS 指定文件到本机目录下
hadoop jar [jarPath] [mainClass] [indir] [outdir] [grep]
# 向 hadoop 提交 mapreduce 任务
# 其中 [indir] 和 [outdir] 为 HDFS 输入和输出目录(输出目录不能存在)
执行 MapReduce 程序,将在 [outdir] 下生成结果文件,文件数据默认按 64MB 进行分块
还会生成一个表示成功的标识文件_SUCCESS
可以通过 web 界面或服务器下载来查看结果
示例:
hadoop jar hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-x.y.z.jar grep input output 'dfs[a-z.]+'
(在 x.y.z 处填入你所选 hadoop 的版本)
该程序将统计 ‘input’ 目录下所有文件包含 ‘dfs’ 的字符串,并输出到 ‘output’
目录可以在 web 界面中创建(需要权限),也可以使用 hdfs 命令创建
3. 完全分布式 —— Fully-Distributed
在完成步骤 (2) 后,添加如下配置:
配置 HDFS
hdfs-site.xml 添加 SecondaryNode 地址:
dfs.namenode.secondary.http-address # SencondaryNode 地址,默认端口 9868
配置 YARN
vim yarn-site.xml # 配置 yarn-site.xml
yarn.resourcemanager.hostsname # ResourceManager 主机名
yarn.resourcemanager.webapp.address # ResourceManager web 地址
# 默认为 [yarn.resourcemanager.hostsname]:8088
yarn.nodemanager.aux-services # NodeManager 辅助服务
# 配置为 mapreduce_shuffle,让 NodeManager 使用 Mapreduce 服务
yarn-site.xml 示例:
<configuration>
<property>
<name>yarn.resourcemanager.hostsname</name>
<value>node01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
配置 MapReduce
vim mapred-site.xml # 配置 mapred-site.xml
mapreduce.framework.name # MapReduce 应用的底层框架
# 配置为 yarn
mapred-site.xml 示例:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
添加 Workers
workers 文件用以标识 Hadoop 集群中的工作节点
创建 etc/hadoop/workers 文件,按行列出所有 worker 映射主机名或 IP 地址
workers 示例:
node01
node02
node03
node04
使用 scp 命令分发 core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers 文件
(也可借助 Xftp 来进行文件分发)
scp -r core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml workers [主机]:[hadoop 配置目录]
分发 /etc/profile.d/hadoop.sh 环境变量文件:
sudo scp /etc/profile.d/hadoop.sh [host]:/etc/profile.d
各节点执行:
source /etc/profile
Namenode 节点执行:
start-dfs.sh
start-yarn.sh
MapReduce
一个 MapReduce 任务的 Jar 包主要包含三个部分:MapTask、ReduceTask 和 TaskDriver
文档以 Wordcount.jar 为例进行说明,该 Jar 包负责统计 input 目录下所有文件中所有单词出现的次数,编写 MapReduce java 程序时需要引入 hadoop/share/hadoop 下的 Jar 包
1. MapTask
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class MapTask extends Mapper<LongWritable, Text, Text, IntWritable>{
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for (String word : words) {
context.write(new Text(word), new IntWritable(1));
}
}
}
2. ReduceTask
public class ReduceTask extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
int count = 0 ;
for (IntWritable value : arg1) {
count += value.get();
}
arg2.write(arg0, new IntWritable(count));
}
}
3. TaskDriver
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 创建配置文件对象
Configuration conf = new Configuration(true);
// 获取Job对象
Job job = Job.getInstance(conf);
// 设置相关类
job.setJarByClass(WordCountDriver.class);
// 指定 Map阶段和Reduce阶段的处理类
job.setMapperClass(MapTask.class);
job.setReducerClass(ReduceTask.class);
// 指定Map的输出的KV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 指定job的原始文件的输入输出路径 通过参数传入
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 将job中配置的参数和job所用的jar包提交给 yarn运行
// waitForCompletion等待执行的结果
job.waitForCompletion(true);
}
}
之后使用 IDE 或手动将以上 java 文件编译打包成 Jar 包,上传到服务器上,使用 hadoop jar 命令执行 mapreduce 任务
Apache Zookeeper
Apache ZooKeeper 致力于开发和维护开源服务器,以实现高度可靠的分布式协调。
ZooKeeper 是一种集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务。
所有这些类型的服务都由分布式应用程序以某种形式使用。每次实现它们时,都需要大量的工作来修复不可避免的错误和冲突。
由于实现这些类型的服务很困难,应用程序初始化时通常都会跳过它们,这使得它们在发生变化时变得脆弱并且难以管理。即使操作正确,这些服务的不同实现也会导致部署应用程序时的管理复杂性。
部署 Zookeeper,为 Hadoop HA 高可用的实现,启动故障转移(Failover)做准备:
为了确保多数仲裁顺利进行,建议使用单数节点的 Zk 集群
配置环境变量
export ZOOKEEPER_HOME=[你的 Zookeeper 安装路径]
export PATH=$ZOOKEEPER_HOME/bin:$PATH
复制 zookeeper/conf/zoo_sample.cfg 到 zoo.cfg:
cp zookeeper/conf/zoo_sample.cfg zookeeper/conf/zoo.cfg
配置 Zookeeper
vim zookeeper/conf/zoo.cfg # 编辑 zookeeper 配置文件
dataDir=[你的 Zk 数据目录] # zookeeper 数据目录
clientPort=2181 # 客户端端口号,默认 2181
admin.serverPort=[port] # 服务端端口号,默认 8080
server.[id]=[host]:[port1]:[port2] # 分配选举与仲裁服务器
# 使用 [port1] 仲裁,[port2] 选举 leader 服务器,默认为 2888:3888
scp zookeeper/conf/zoo.cfg [host]:zookeeper/conf/zoo.cfg # 分发 zoo.cfg 文件
若是想在一台机器上部署多个 zookeeper 服务,请为各服务端分配不同端口
Zookeeper 通过查看各节点 dataDir 下的 myid 文件(需要手动创建)来辨识服务器
echo [id] > [dataDir]/myid
启动 Zookeeper:
bin/zkServer.sh start|stop # 启动|停止 Zk 服务端
jps # JAVA 进程中将会出现 ZkQuromPeers
bin/zkCli.sh -server [zk主机]:2181
# 启动 Zk 客户端 连接指定主机上的 zkServer,默认端口 2181
[zk:(CONNECT)] help # 查看帮助
[zk:(CONNECT)] close|quit|CTRL+D # 断开连接
[zk:(CONNECT)] ls / # 查看 Zookeeper /目录内容
# Zookeeper Znone 按树状结构存储 Key:Value
zkCleanup.sh -n 10 # 清理 Zk 日志,保留最近 10 份文件
HadoopHA 高可用 —— High Availability
什么是高可用性?
在计算中,术语可用性用于描述服务可用的时间段,以及系统响应用户发出的请求所需的时间。高可用性是系统或组件的一种质量,可确保在给定时间段内具有高水平的操作性能。
衡量可用性
可用性通常表示为百分比,表示在给定时间段内特定系统或组件的预期正常运行时间,其中值 100% 表示系统永远不会出现故障。例如,一个在一年内保证99%可用性的系统可能会有长达3.65天的停机时间(1%)
这些值是根据几个因素计算的,包括计划的和计划的维护周期,以及从可能的系统故障中恢复的时间。
规划服务器节点
为了实现 Hadoop HA 高可用,为 HDFS 和 YARN 提供备份服务器及Zookeeper故障转移
至少需要4台服务器(实际上实现故障转移至少需要7台服务器)
(本地计算机资源紧张的话可以先跳过本节)
| 节点名 | IP地址 | 当前角色 | 规划后新增角色 |
|---|---|---|---|
| Node01 | 192.168.127.11 | NameNode DataNode ResourceManager NodeManager | ZkFailoverConctrol |
| Node02 | 192.168.127.12 | SecondaryNameNode DataNode NodeManager ZkQuorum | StandbyNameNode ResourceManager JournalNode ZkFailoverConctrol |
| Node03 | 192.168.127.13 | DataNode NodeManager ZkQuorum | JournalNode |
| Node04 | 192.168.127.14 | DataNode NodeManager ZkQuorum | JournalNode |
HDFS 高可用:HDFS High Availability Using the Quorum Journal Manager
YARN 高可用:ResourceManager High Availability
HDFS 高可用
vim hadoop/etc/hadoop/hdfs-site.xml # 编辑 hdfs-site.xml 文件
dfs.nameservices # NameNode 集群 Cluster ID
dfs.ha.namenodes.[你的集群 ID] # 集群各节点的 ID 列表,逗号分隔
dfs.namenode.rpc-address.[你的集群 ID].[你的 NN 节点 ID]
# 集群中 ID 为 nnID 的 RPC 地址及端口
dfs.namenode.http-address.[你的集群 ID].[你的 NN 节点 ID]
# 集群中 ID 为 nnID 的 HTTP 地址及端口
dfs.namenode.shared.edits.dir
# JournalNode 集群地址,一般与 Zookeeper 集群地址相同
# 格式为:qjournal://[节点1]:8485;[节点2]:8485;[节点3]8485/[你的集群 ID]
dfs.ha.automatic-failover.enabled # 配置自动故障转移
# 配置为 true
ha.zookeeper.quorum # 为故障转移配置 zk 集群
dfs.client.failover.proxy.provider.[你的集群 ID] # 配置故障转移实现方法
# 配置为 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods # 配置隔离机制方法
# 配置为 sshfence
dfs.ha.fencing.ssh.private-key-files # ssh 私钥文件路径
# 一般在 ~/.ssh/id_rsa
dfs.ha.fencing.ssh.connect-timeout # ssh 连接超时时间(毫秒)
在 core-site.xml 配置 Hadoop HA
fs.defaultFS # 将通信地址指向 nn 集群 ID
# 配置为 hdfs://[你的集群 ID]
dfs.journalnode.edits.dir # 指定日志存放的物理地址
YARN 高可用
vim hadoop/etc/hadoop/yarn-site.xml # 编辑 yarn-site.xml 文件
yarn.resourcemanager.ha.enabled # 开启 ResourceManager HA,默认 false
# 配置为 true
yarn.resourcemanager.cluster-id # ResourceManager 集群 ID
yarn.resourcemanager.ha.rm-ids # 集群内 RM 节点 ID 列表,逗号分隔
yarn.resourcemanager.hostname.[你的 RM 节点 ID]
# [你的 RM 节点 ID] 的主机名
yarn.resourcemanager.webapp.address.[你的 RM 节点 ID]
# [你的 RM 节点 ID] 的 web 地址及端口
hadoop.zk.address # ZK 集群地址及端口
# 如 [zk节点1]:2181,[zk节点2]:2181,[zk节点3]:2181
启动顺序
1. 启动 Zookeeper 集群
zkServer.sh start
2. (初次启动时)格式化 NameNode 集群
(1)格式化 NameNode
hdfs namenode -format
# 已格式化的非 HA NameNode 节点转 HA NameNode
# hdfs namenode -initializeSharedEdits
(2)格式化 Standby NameNode
hdfs namenode -bootstrapStandby # 需要先启动 NameNode 使之能够通信
(3)格式化 ZKFC
hdfs zkfc -formatZK # 在所有 NameNode 节点上进行格式化
3. NameNode 启动 HDFS 和 YARN
start-dfs.sh # 将启动 zkfc 进程与 zk 集群对应的 JournalNode 节点
start-yarn.sh # 启动 YARN
hdfs --daemon start zkfc # 如遇故障,手动启动 zkfc 进程
Apache HBase
Apache HBase™ 是 Hadoop 的一个分布式,可扩展的大数据存储数据库
当您需要对大数据进行随机、实时读/写访问时,请使用 Apache HBase™
该项目的目标是在商用硬件集群上托管非常大的表 —— 数十亿行×数百万列
Apache HBase 是一个开源,分布式,版本化的非关系数据库
正如 Bigtable 利用 Google 文件系统提供的分布式数据存储一样
Apache HBase 以 Google Bigtable 为蓝本,在 Hadoop 和 HDFS 之上提供了类似 Bigtable 的功能
关系型数据库 VS 非关系型数据库
关系数据库也称为关系数据库管理系统(RDBMS),它将数据存储在表和行(记录)中
流行的关系型数据库有 SQL Server Express,PostgreSQL,SQLite,MySQL 和 MariaDB
关系数据库的工作原理是通过使用“键”来连接多个表的信息(行/记录)
这些连接会在多个表的信息(行/记录)之间创建“关系”
非关系数据库或 NoSQL 数据库不使用表、行或键来存储或描述信息
相反,非关系数据库使用针对所存储数据类型的特定要求而优化的存储模型
如文档数据存储、列式数据存储、键值存储、文档存储、图形数据库等
流行的 NoSQL 数据库有 MongoDB,Apache Cassandra,Redis,Couchbase 和 Apache HBase
HBase 表结构
在逻辑上,HBase 表是由行键、列族、列和单元格组织起来的:
| 行键 Rowkey | 列族 Column Family A | Column Family B | |||
|---|---|---|---|---|---|
| 列 Column a | Column b | Column c | Column d | Column e | |
| Rowkey i | 单元格 Cell 1 | Cell 2 | Cell 3 | Cell 4 | Cell 5 |
在物理上,HBase 表采用类似字典的结构,以键值对的形式,按照字典顺序进行存放的:
| 键 ROW | 值 COLUMN+CELL |
|---|---|
| i | column=A:a, timestamp=[time1], value=1 |
| i | column=A:b, timestamp=[time2], value=2 |
| i | column=B:c, timestamp=[time3], value=3 |
| i | column=B:d, timestamp=[time4], value=4 |
| i | column=B:e, timestamp=[time5], value=5 |
其中,列族与列之间用 “:” 修饰符来连接,在向 HBase 对表进行操作时还会写入时间戳 timestamp
HBase 在文件中的表结构:
{
'i': {
'A': {
'a': { '[time1]': 1 },
'b': { '[time2]': 2 }
},
'B': {
'c': { '[time3]': 3 },
'd': { '[time4]': 4 },
'e': { '[time5]': 5 }
}
}
}
部署 HBase
HBase 依赖于 Hadoop 和 Zookeeper 环境
请在部署 HBase 前确认 Hadoop 和 Zookeeper 部署无误再进行
HBase 分为 HMaster 主服务器和 HRegionServer 区域服务器,若需部署 HBase HA
则需要 HBackupMaster 备份服务器,这些服务器都需要部署在 Zookeeper 集群中才能正常运行
1. 独立模式
配置环境
vim hbase/conf/hbase-env.sh # 编辑 hbase-env.sh 文件
export JAVA_HOME=[你的 JDK 安装路径] # 配置 JAVA 环境变量
export HBASE_PID_DIR=[你的 HBase PID 文件路径] # 配置 Hbase 进程文件目录
sudo vim /etc/profile.d/hbase.sh # 配置 HBase 环境变量
export HBASE_HOME=[你的 HBase 安装目录]
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
启动 HBase
start-hbase.sh # 启动 HBase,默认 web 地址:localhost:16010
jps # JAVA 进程中将会出现 HMaster
stop-hbase.sh # 关闭 HBase
hbase shell # 启动 HBase Shell 命令行
> help # 显示帮助
> quit 或 CTRL+D # 关闭 HBase Shell 命令行
> list # 查看 HBase 所有表
> create 't','cf1',‘cf2’ # 创建名为 t,列族为 cf1 和 cf2 的表
> describe 't' # 显示表 t 的列族及其属性
> put 't','rk1','cf1:c1','v1' # 创建列 cf1:c1 并插入行键为 rk1 的值 v1
> scan 't' # 全表检索 t
> get 't','rk1' # 检索表 t 中,行键为 rk1 的单元格的值
> disable|enable 't' # 禁用|启用表 t
> drop 't' # 删除表 t
2. 伪分布式
配置 HBase
vim /hbase/etc/hbase-site.xml # 编辑 hbase-site.xml 文件
hbase.cluster.distributed # 配置为 true
hbase.rootdir
# 配置为 hdfs://[fs.defaultFS]/hbase
# 其中 fs.defaultFS 为 hadoop/etc/hadoop/core-site.xml 中对应参数的属性值
删除 hbase.tmp.dir 和 hbase.unsafe.stream.capability.enforce 参数,HBase 运行产生的文件都将记录到 HDFS 下的 [hbase.rootdir] 中
bin/start-hbase.sh # 启动 hbase
local-master-backup.sh start|stop [offset1|offset2|...]
# 手动开启|关闭本地 HBase 备份主服务器,默认端口 16000 16010
# offset 端口号偏移量,最多可启用 9 个 Hbase 备份主服务器
local-regionservers.sh start|stop [offset1|offset2|...]
# 故障或进行节点维护时,单独开启/关闭 HBase 区域服务器
# 默认端口 16020 16030,最多可开启 99 个
cat hbase-testuser-[offset]-master.pid | xargs kill -9
# 可以使用 kill -9 命令通过 pid 文件中的进程号结束服务器而不关闭集群
jps # JAVA 进程将会出现 HRegionServer 和 HBackupMaster
hdfs dfs -ll / # HDFS 根目录下将会创建 HBase 目录
在伪分布式中,HMaster,HBackupMaster 和 HRegionServer 都在同一台服务器上,在生产环境下是没有意义的,仅做本地测试使用
3. 完全分布式
编辑环境
vim hbase/conf/hbase-env.sh # 编辑 hbase-env.sh 文件
export HBASE_MANAGES_ZK=false
# 不使用 HBase 自带的 Zookeeper,使用服务器中的 Zookeeper 进行集群节点管理
vim hbase/conf/regionservers # 添加 HBase 区域服务器
# 删除 localhost,按行添加 HBase 区域服务器主机或 IP 地址
echo [你的 BackupMaster] > hbase/conf/backup-masters
# 在备份服务器上,新建 backup-masters 文件,按行写入备份服务器主机或 IP 地址
配置 HBase
vim hbase/conf/hbase-site.xml # 编辑 hbase-site.xml 文件
hbase.zookeeper.quorum # HBase 使用的 Zookeeper 集群节点
# 配置为 [ZK节点1],[ZK节点2],[ZK节点3]
hbase.zookeeper.property.dataDir # HBase 使用的 Zookeeper 数据目录
# 与 Zookeeper 的 dataDir 相同
hbase.thrift.server.socket.read.timeout # Thrift 服务连接超时时间(ms)
hbase.thrift.connection.max-idletime # Thrift 服务连接最大闲置时间(ms)
在确认所有节点 HBase 服务器进程处于关闭状态后,在主服务器上开启 HBase
部署程序语言环境
安装 Scala, Python 或 R
在安装 Apache Spark 进行大数据分析之前,需要先准备语言环境
Spark 所使用的语言有 Scala、Python、R 和 JAVA
在 Scala 官网或镜像站上下载对应版本的 deb 软件包
切换到 deb 包所在目录,然后使用如下命令安装 deb 包:
sudo dpkg -i [你的 deb 包名].deb
Ubuntu 22 上默认已经安装了 Python 3.10.4
如果系统里没有 Python 或 R,可以使用 apt 命令安装:
sudo apt install python3
sudo apt install r-base
whereis scala|python3|R # 查看 Scala|python3|R 的安装目录
# 通过 yum 或者 apt 安装的软件默认都在 /usr/bin 下
安装 RStudio Server
如果使用 Python 或 R 在服务端进行开发,可选择 Rstudio Server 作为 R 与 Python 的 IDE
Rstudio Server 提供 “Reticulate” 包,可在 R 语言环境中调用 Python 代码或在 R 命令行界面启动 Python 命令行,Rstudio Server 本身也可新建或编辑 Python 文件
(注:Ubuntu 22 在安装 Rstudio Server 时需要安装 libssl1.1 deb 依赖包)
cd [下载 deb 包的目标目录]
sudo apt install gdebi-core
wget https://download2.rstudio.org/server/bionic/amd64/rstudio-server-2022.02.2-485-amd64.deb
sudo gdebi rstudio-server-2022.02.2-485-amd64.deb
sudo systemctl enable rstudio-server # 安装完成后会开启服务,设置服务自启动
http://[Rstudio-Server 主机]:8787 # 连接 Rstudio Server,默认端口 8787
网页会出现登录框,使用 Rstudio Server 的主机用户名和密码登录后,通过 web 会话编写 R 程序:
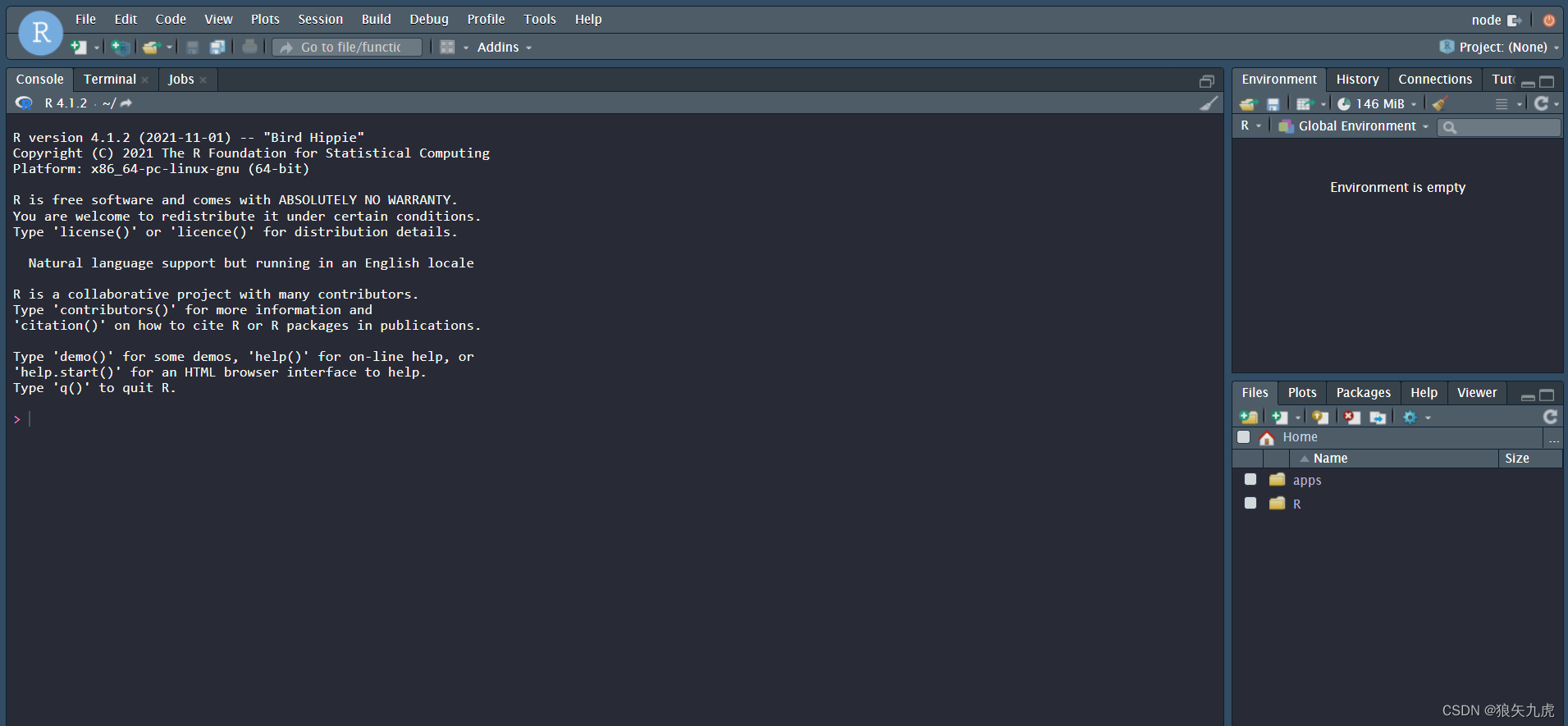
Rstudio Server 分为三个部分:
① 左栏:控制台 Console、终端 Terminal 和任务 Jobs 窗口
② 右上栏:环境 Environment、历史 History 、连接 Connections 和指南 Tutorial 窗口
③ 右下栏:工作目录 Files、图像 Plots、包 Packages、帮助 Help 和浏览器 Viewer 窗口
可根据需要更改 RStudio Server 的工作目录及 R 包安装目录:
getwd() # 查看工作目录
.libPaths() # 查看 R 包安装目录
setwd("[工作目录]") # 设置工作目录(仅本次会话连接有效)
.libPaths("[R 包目录]") # 设置 R 包安装目录(仅本次会话连接有效)
如果想为用户设置默认目录,则需要在菜单栏或 ~/.Renviron 文件(需要新建)中进行设置
默认工作目录:在菜单栏上单击 Tools -> Global Options,在右栏中填写
默认环境变量:
vim ~/.Renviron # 新建 RStudio Server 用户环境变量
R_LIBS="[R 包目录]" # 为用户添加默认 R 包安装目录
常用 R 包
Reticulate —— 在 RStudio Server 中使用 Python
Apache Spark
Apache Spark 是一个开源并行处理框架,支持内存中处理,以提高应用程序分析大数据的性能
大数据解决方案旨在处理对于传统数据库而言太大或太复杂的数据。
Spark 处理内存中的大量数据通常比基于磁盘的替代方案快得多。
Spark 可用于多个大数据场景,如:抽取转换和加载 (ETL)、实时数据流处理(Spark Streaming)
机器学习(Spark MLlib)、图形处理(Spark GraphX)、结构化数据处理(Spark SQL)等
配置 Spark
sudo vim /etc/profile.d/spark.sh # 配置 Spark 环境变量
export SPARK_HOME=[你的 Spark 安装目录]
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME
source /etc/profile
vim conf/spark-env.sh # 编辑 spark-env.sh 文件
export SPARK_MASTER_WEBUI_PORT=[你的 Spark Web 端口] # Spark Web 地址,默认8080
# 在 Spark Web 界面可以查看 Spark Master 的通讯地址,默认端口 7077
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=[zk节点1],[zk节点2],[zk节点3] -Dspark.deploy.zookeeper.dir=[你的 zk dataDir]"
# 配置 Spark HA Zookeeper 集群
vim conf/workers # 新建 workers 文件
# 按行写入所有 worker 节点的主机或IP地址
启动 Spark
start-master.sh # 本地手动启动 Spark 主节点(服务器)
start-worker.sh # 本地手动启动 Spark 工作节点
start-all.sh # 启动 Spark 主节点与工作节点,备份节点需要手动开启
spark-shell --master local[n] # 在本地启动 Spark shell 命令行
--master local[K,F] # 在本地使用 K 线程执行任务,F 次失败重试
--master local[*] # 在本地使用与 CPU 数一样多的线程执行任务
spark://[你的 SparkMaster 主机]:7077
# 在远程 SparkMaster 启动 Spark Shell,默认使用 Scala 语言
pySpark # 打开 Spark python 命令行
SparkR # 打开 Spark R 命令行
提交 Spark 任务
spark-submit \ # 提交 spark 任务
--class <main-class> \ # 入口方法
--master <master-url> \ # 集群主机站点
--deploy-mode <deploy-mode> \
# 在集群(cluster)或作为客户端(client)部署程序,默认 client
--conf <key>=<value> \ # 配置信息,按 key=value 格式设置
<application-jar> \
# jar 包路径,路径必须在集群内可见,如 hdfs 路径
示例:
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--total-executor-cores 100 \
--executor-memory 20G \
/path/to/examples.jar \
1000
在主机 spark://207.184.161.138:7077 上使用 100 核 20G 内存
用 cluster 模式执行了 org.apache.spark.examples.SparkPi 方法
supervise 参数确保执行失败时能够自动重启,jar 包路径在 /path/to 下,参数为 1000
可以在 spark/conf/spark-defaults.conf 配置默认 sumit 参数
Apache Phonix
下载安装:Overview | Apache Phoenix
环境变量:
export PHOENIX_HOME=[phoenix_home_path]
export PATH=
P
H
O
E
N
I
X
H
O
M
E
/
b
i
n
:
PHOENIX_HOME/bin:
PHOENIXHOME/bin:PATH
将 phoenix-server-hbase.jar 拷贝到所有 HbaseRegionServer 的 /hbase/lib 下
将 Hbase 配置文件 hbase-site.xml 中的内容添加到 phoenix/bin/hbase-site.xml 下
将 Hadoop 配置文件 core-site.xml hdfs-site.xml 复制到 phoenix/bin 下
重启 Hbase
启动 Phoenix sqlline:
sqlline.py [zk quorum hosts]
Hbase 表映射,使用 CREATE TABLE 创建映射:
CREATE TABLE IF NOT EXISTS "[namespace]"."[tablename]"(
)
column_encoded_bytes=0;
sqlline 命令操作:SQLLine 1.12.0 (julianhyde.github.io)
phoenix 数据库操作:Grammar | Apache Phoenix
基本配置:Configure|Apache Phoenix
开启二级索引:Secondary Indexing | Apache Phoenix
用户自定义函数:User-defined functions(UDFs) | Apache Phoenix
Apache Kafka
数据迁移
本地 -> HDFS -> HBase:
hadoop fs -put/-rm hdfs 路径
调用 HBase 的 ImportTSV
1.Puts
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.separator="分隔符" \ 指定分隔符,默认为\t
-Dimporttsv.skip.bad.lines=true \ 是否跳过错误行
-Dimporttsv.timestamp=时间戳 \ 指定时间戳
-Dimporttsv.mapper.class=myMapper \ 指定 Mapper 程序
默认=org.apache.hadoop.hbase.mapreduce.TsvImporterMapper
-Dmapreduce.job.name=MR 任务名 \ 指定 MapReduce 任务名
-Dcreate.table=yes \ 是否创建表
-Dno.strict=true \ 是否执行列族检查
-Dmapreduce.map.speculative=false \ 关闭 Map 端推断
-Dmapreduce.reduce.speculative=false 关闭 Reduce 端推断(提升性能)
-Dimporttsv.columns='HBASE_ROW_KEY, 列族:列 1,列族:列 2...' \
<表名> <HDFS 文件目录>
2.Bulk-Loading(推荐)
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv \
-Dimporttsv.columns=HBASE_ROW_KEY, 列族:列 1,列族:列 2... \
-Dimporttsv.bulk.output=output 目录 <表名> <input 目录>
将会使用 MapReduce,在指定目录下生成 storefile 结构
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles <output 目录> <表名>
将会从 HDFS 目录下读取 Hfile 文件,用以生成 Hbase 表
本地 -> Spark:
sparkR 读 csv 文件:
df <- read.df(
path = csvPath, 数据源路径
source ="csv", 数据源类型
header = "true", 存在表头
inferSchema = "true", 自动匹配数据类型
na.strings = "NA", NULL 值
sep = "\t", 分隔符
encoding = "gbk") 编码
mysql -> sparkR:
https://mariadb.org/download/
在 MariaDB Repositories,添加 yum 仓库代码到 /etc/yum.repos.d/MariaDB.repo 文件
sudo yum install MariaDB-server MariaDB-client
服务开启/自启动 mariadb
mysql_secure_installation
数据库 root 默认密码:无
install.packages("RODBC")
library(DBI)
library(RMariaDB)
con <- dbConnect(
drv = MariaDB(),
username = "root",
password = "root",
host = "WNode05",
port = 3306,
dbname = "jumper"
)
dbListTables(con)
rs <- dbSendQuery(con, "SQL")
df <- dbFetch(rs,n = "显示行数")
dbClearResult(rs)
dbDisconnect(con)
SparkR -> HBase:使用 Apache 提供的 HBase-Connectors 来连接 Hbase
https://github.com/apache/hbase-connectors
参考文档:
https://github.com/LucaCanali/Miscellaneous/blob/master/Spark_Notes/Spark_HBase_Connector.md
下载 Maven 3.8.5,配置环境变量
export MAVEN_HOME=/home/node/apps/maven-3.8.5
export PATH=$PATH:$MAVEN_HOME/bin:$MAVEN_HOME
查看 maven 版本:mvn -v
在源码根目录下,使用 maven 编译 Apache HBase Spark Connector(根据需要更改 maven 源)
mvn -Dspark.version=3.1.2 \
-Dscala.version=2.12.10 \
-Dhadoop-three.version=3.2.3 \
-Dscala.binary.version=2.12 \
-Dhbase.version=2.4.11 \
-Dcheckstyle.skip=true \ 跳过代码检查
-DskipTests=true clean install 跳过测试,将生成的 jar 包部署在本地 maven 库中
执行完成后,将在对应 target 目录下生成 xxx-1.0.1-SNAPSHOT.jar 包
对于客户端(Spark 端):将 hbase-site.xml 复制到 spark/conf 目录下
对于服务端(Hbase 端):将 scala/lib hbase-spark 和 hbase-spark-protocol-shaded 下的 jar 包复制到 hbase/lib 目录下
Sys.setenv(SPARK_HOME = "SPARK 路径")
jars <- hbase-spark 和 hbase-spark-protocol-shaded.jar 路径
# 与 spark 建立连接,调用 maven 本地库中的 hbase 和 MapReduce jar 包
sparkR.session(
master = "spark 通信地址",
sparkJars = jars,
sparkPackages = "org.apache.hbase:hbase-shaded-mapreduce:2.4.11"
)
关闭 spark 连接
sparkR.session.stop()
R -> python -> HBase:
要求:autoconf 2.69+ automake 1.14+ bison 2.5.1+
在指定目录构建 python 虚拟环境并激活:
pip3 install --user virtualenv
virtualenv myvenv
source myvenv/bin/activate
deactivate 退出虚拟环境
查看激活的 python 目录:
which python
编译 Boost: https://www.boost.org/
./bootstrap.sh
sudo ./b2 install
编译 Thrift 客户端: https://thrift.apache.org/
./configure --with-cpp --with-py3 --without-python
make
sudo make install
hbase-daemon.sh start thrift 启动 hbase thrift 服务端
在 R 中安装 reticulate,配置环境变量:
install.packages("reticulate")
RETICULATE_PYTHON = "my_env/bin/python"
在 R 控制台运行如下指令测试:
py_config()
安装 thrift 和 happybase:
py_install("thrift")
py_install("happybase")
数据操作
一、SparkR
(1) Hbase -> Spark:
# 在 HBase 中,存在一张表 't' :
# rowkey col value type
# rk cf:c1 v1 string
# 准备要读取数据的表结构 catalog
catalog = '{
"table":{"namespace":"default", "name":"t"},
"rowkey":"rk",
"columns":{
"rk":{"col":"rk", "type":"string"},
"c1":{"cf":"cf", "col":"c1", "type":"string"}
}
}'
# 调用 read.df,传入入口,表结构,不使用 HbaseContext(读取数据的另一种方式)
# 返回 SparkDataFrame
sdf <- read.df(
source = "org.apache.hadoop.hbase.spark",
catalog = catalog,
hbase.spark.use.hbasecontext = FALSE
)
# 查看表
head(sdf)
(2) Spark -> Hbase:
# 调用 write.df,传入入口,表结构,不使用 HbaseContext
write.df(
df,
source = "org.apache.hadoop.hbase.spark",
catalog = catalog,
hbase.spark.use.hbasecontext = FALSE
)
二、Sparklyr
(1) HBase -> Spark:
conf <- spark_config()
conf$sparklyr.connect.jars <- hbase-spark 和 hbase-spark-protocol-shaded.jar 路径
conf$sparklyr.connect.packages <- "org.apache.hbase:hbase-shaded-mapreduce:2.4.11"
catalog <- 表结构
sc <- spark_connect(
master = "spark 通信地址",
spark_home = "spark 目录",
method = "shell",
app_name = "sparklyr",
config = conf
)
sdf <- spark_read_source(
sc,
name = "jumper.heat",
source = "org.apache.hadoop.hbase.spark",
memory = FALSE,
options = c("catalog"=catalog, "hbase.spark.use.hbasecontext"=FALSE)
)
head(sdf)
(2) Spark -> HBase:
spark_write_source(
sdf,
name = "jumper.heat",
source = "org.apache.hadoop.hbase.spark",
memory = FALSE,
options = c("catalog"=catalog, "hbase.spark.use.hbasecontext"=FALSE)
)
四、常用工具介绍
crontab
使用 crontab 安排定时任务:
crontab -l 查看定时任务
crontab -e 添加定时任务
sudo crontab -e 添加 root 定时任务
vim <task>.sh 创建脚本
#! /bin/bash
<脚本内容>
(0-59) (0-23) (1-31) (1-12) (0-7)
分 时 日 月 星期(*=未设置)
x y z a b bash 脚本路径
@reboot 自启动
setwd(“工作目录”)
.libPaths(“R 包安装目录”)
Rstudio Server 用户环境变量在 ~/.Renviron 中(新建)
R_LIBS=“myRLibs”
升级 gcc,为 C++编译做准备:
预装 cmake 3.21.4,添加环境变量:
export PATH=$PATH:/home/node/apps/R-4.1.3/exlib/cmake-3.21.4/bin
预装 scl 库:
yum -y install centos-release-scl
安装 gcc 升级工具:
yum -y install devtoolset-11-gcc devtoolset-11-gcc-c++ devtoolset-11-binutils
将升级指令添加到环境变量中:
echo "source /opt/rh/devtoolset-11/enable" >> /etc/profile
安装 sparklyr:
install.packages("sparklyr", dependencies = TRUE)
注:需要在 Rstudio 上预装
libjpeg-devel openssl openssl-devel xml2 libxml2-devel httr 等包
(其中,arrow 包需要 cmake 3.10+版本,推荐 gcc 2.8+版本)
安装 arrow 包(用于在 JVM 和 R 之间传输数据):
Sys.setenv("NOT_CRAN" = TRUE) 使用源码安装
install.packages("arrow")
library(sparklyr) 加载 sparklyr 包
spark_home_set(path = "spark 路径") 设置 spark 路径
sc <- spark_connect(master = "spark 通信地址(大小写敏感)") 建立 spark 连接
spark_disconnect(sc) 断开 spark 连接
sparklyr 参考文档:spark.rstudio.com/packages/sparklyr/latest/reference/
libpath <- .libPaths()
libpath <- c(libpath, "spark/R/lib") 把 sparkR 包目录加入 R 包目录
.libPaths(libpath)
rm(libpath) 清除 libpath
library(SparkR) 加载 SparkR 包
Sys.setenv(SPARK_HOME = "spark 目录") 设置本地 spark 目录
sparkR.session() 建立本地 spark 连接
sparkR.session(master = "spark 通信地址") 建立远程 spark 连接
sparkR.session.stop() 断开 spark 连接
sparkR-3.1.2 参考文档:spark.apache.org/docs/3.1.2/sparkr.html
RestRserve
五、附录
需要安装的程序:
chrony 时间同步
OpenSSH 远程登录
tree 目录树状图
JDK JAVA 环境
Hadoop MapReduce Zookeeper 分布式计算环境
R Python Scala Spark 编程语言环境
Hbase Spark Mysql 数据库与数据转换














 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









