







 FCAN是一种全卷积适应网络,旨在解决深度学习中无监督语义分割的域适应问题。通过图像域适应网络(AAN)处理风格转换,特征适应网络(RAN)进行语义分割。AAN利用Gram矩阵和特征相关性调整图像风格,RAN则结合对抗网络和空洞空间金字塔池化实现领域不变表示。实验表明,FCAN在GTA5到Cityscapes数据集的域适应中表现出色。
FCAN是一种全卷积适应网络,旨在解决深度学习中无监督语义分割的域适应问题。通过图像域适应网络(AAN)处理风格转换,特征适应网络(RAN)进行语义分割。AAN利用Gram矩阵和特征相关性调整图像风格,RAN则结合对抗网络和空洞空间金字塔池化实现领域不变表示。实验表明,FCAN在GTA5到Cityscapes数据集的域适应中表现出色。
深度学习(8)——无监督语义分割之全卷积域适应网络(FCAN)
Fully Convolutional Adaptation Networks for Semantic Segmentation
篇文章发表在CVPR2018上,主要工作是提出了两种域适应策略,探索了如何使用合成图像提升真实图像的语义分割性能。
讲解论文之前,我们先来看几个概念。
域适应(Domain adaptation):
域适应问题(域自适应问题)中包含两个域,一个包含大量的标签信息,称为源域(source domain);另一个只有少量的甚至没有标签,但是却包含我们要预测的样本 ,称为目标域(target domain)。源域和目标域的数据分布不同,相关但不相同,如猫和虎两个数据集。如何使得源域(Source Domain)上训练好的分类器能够很好地迁移到没有标签数据的目标域上(Target Domain)上,这种迁移学习叫做域适应。
Domain shift:
源域和目标域的数据分布存在巨大的偏差。
了解这两个概念后,我们来看一下这篇文章的背景介绍。
现在获取大量有标签的数据很困难,特别是用于图像分割的像素级标记信息更困难。于是有学者提出通过游戏引擎合成自动驾驶场景下的图像数据,同时得到像素级的语义标签。但是合成图像和真实图像之间存在domain shift问题,这篇文章就是探索这个问题。
相关工作
这篇文章是基于全卷积适应网络的语义分割,所以相关工作分为语义分割和域适应
语义分割的目的是预测给定图像或视频帧的像素级语义标签。最近阶段的工作大都是基于FCN,如包括多尺度特征融合提出的背景信息保存,或用条件随机场等改进FCN;还有使用弱监督进行语义分割。
域适应现在主要的工作方向是无监督、监督和半监督自适应,主要划分依据就是目标域的标记数据是否可用。
这篇文章的主要工作集中在语义分割的无监督自适应。
Method
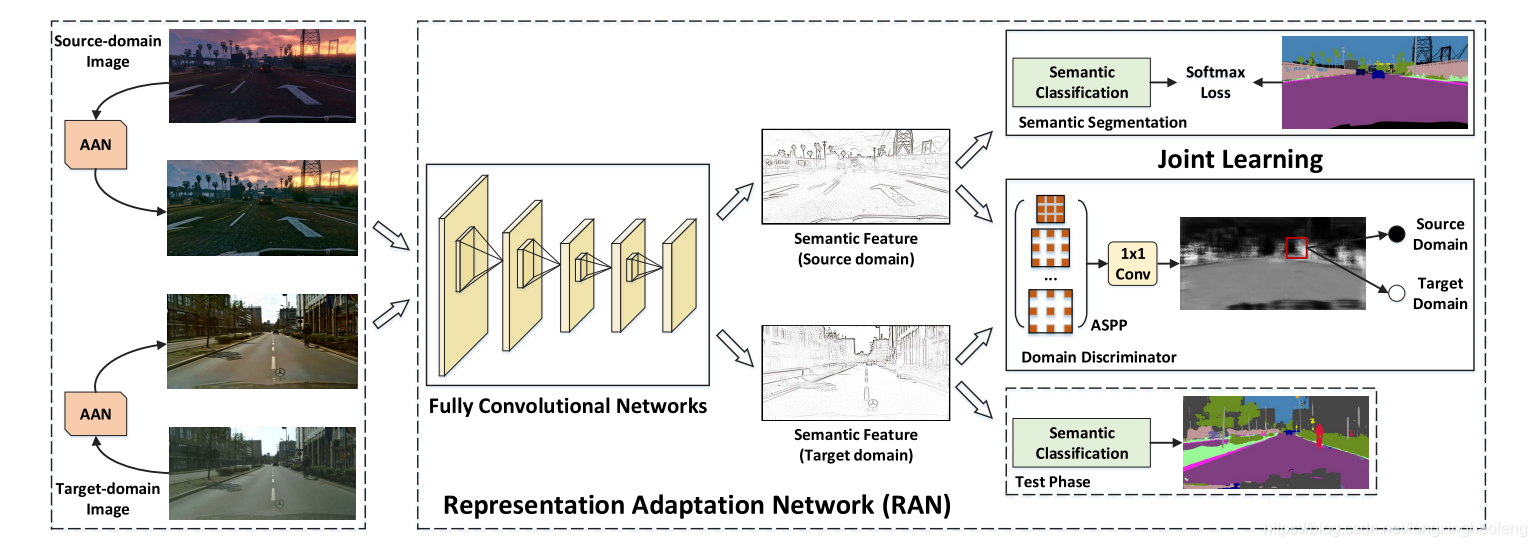
FCAN(全卷积自适应网络)有两个组成部分,左侧的图像域适应网络(AAN),从appearance-level角度处理图像,实际上这部分就是图像风格转换,使得源域图像和目标域图像更加相近。右侧是特征适应网络(RAN),从representation-level角度进行语义分割,实际上就是GANs。其中源域图像是游戏引擎合成图像,目标域是真实街道场景。
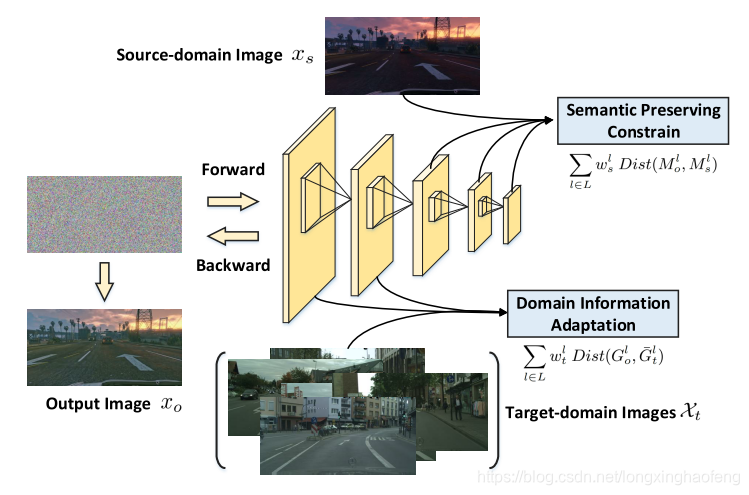
AAN结构如上图,它的的作用是将目标域和源域的图像进行预处理,先进行风格转换。将白噪声输入网络,以迭代的方式,通过网络深层的feature correlation,也就是Gram矩阵和目标域图像集合 X t X_t Xt 的深层的feature correlation更相近来约束图像风格,网络浅层的feature map和源域图像 X s X_s Xs 的feature map相近,来约束图像的语义内容,从而实现 X s X_s Xs 到 X t X_t Xt 的转换,得到自适应图像 x o x_o xo,让游戏引擎合成图像看起来更像真实街道图象。
首先使用预训练好的网络训练每一张图像得到feature map,假设每个卷积层 l l l具有 N l N_l Nl个feature map,并且每个feature map的大小是 H l × W l H_l \times W_l Hl×Wl ,那么 l l l层的feature map可以表示为 M l ∈ R N l × H l × W l M^l \in {\Bbb R}^{N_l×H_l×W_l} Ml∈RNl×Hl×Wl
L c o n t e n t = min x o ∑ l ∈ L w s l D i s t ( M o l , M s l ) L_{content} = \min_{x_o} \sum_{l \in L} w^l_s Dist(M^l_o , M^l_s) Lcontent=xominl∈L∑wslDist(Mol,Msl)
上式是关于来自源域图像 X s X_s Xs和自适应输出图像 X o X_o Xo的风格损失函数。取网络训练后几层的feature map,最小化相关图层feature map的欧式距离,训练图层的权重 w s l w^l_s wsl
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









