









你是否经历过这样的场景:接口响应越来越慢、系统宕机频率升高、监控告警持续拉响,却迟迟找不到根本原因?这时候,大多数人会陷入“怀疑人生”的状态。而真正优秀的测试开发与运维工程师,却能在最短时间内,精准定位性能瓶颈,挽救系统于水火。
高峰期,服务端响应慢如蜗牛,用户投诉频发,甚至系统直接宕机!这些性能瓶颈像隐形杀手,威胁着业务稳定和用户体验。数据显示,1秒的延迟可能导致7%的用户流失!X平台@TechBit感叹:“性能优化是服务端的命脉!”如何快速定位瓶颈,让服务端重回巅峰?本文总结系统化的性能瓶颈定位思路,从全链路监控到精准排查,结合工具和实战案例,带你化被动为主动,打造高性能服务端。
服务端性能瓶颈从何而来?如何系统化定位问题?哪些工具和方法能快速找到根因?
观点与案例结合
性能瓶颈定位需从全局到局部,分层分析应用、数据库、网络和硬件。以下是五大核心思路,附实战案例,助你快速上手。
1. 全链路监控:建立性能基线
场景:通过指标(延迟、吞吐量、错误率)了解系统健康状态。
方法:用Prometheus+Grafana监控CPU、内存、I/O等,设置警报。
代码(Prometheus配置示例):
scrape_configs:
- job_name: 'app'
static_configs:
- targets: ['localhost:8080']
metrics_path: '/metrics'案例:某电商平台用Prometheus发现API响应时间从200ms飙升至2s,定位到高峰期线程池耗尽。
实践:部署Prometheus采集应用指标,用Grafana可视化。
2. 日志分析:定位异常根因
场景:通过日志查找慢查询、异常堆栈或资源争用。
方法:用ELK(Elasticsearch+Logstash+Kibana)聚合日志,分析关键路径。
代码(Java日志配置):
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class OrderService {
private static final Logger logger = LoggerFactory.getLogger(OrderService.class);
public void processOrder(String orderId) {
long start = System.currentTimeMillis();
logger.info("Processing order: {}", orderId);
try {
// 模拟业务逻辑
Thread.sleep(100);
} catch (Exception e) {
logger.error("Order processing failed: {}", orderId, e);
}
logger.info("Order processed in {}ms", System.currentTimeMillis() - start);
}
}案例:某支付系统通过日志发现数据库锁等待导致延迟,优化索引后响应时间缩短70%。
实践:用ELK收集服务端日志,查询慢日志关键词。
3. 分布式追踪:剖析请求链路
场景:定位微服务架构中跨服务的性能瓶颈。
方法:用Jaeger或Zipkin追踪请求,分析各服务耗时。
代码(Spring Boot集成Jaeger):
import io.opentracing.Tracer;
import io.opentracing.util.GlobalTracer;
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
@Bean
public Tracer tracer() {
return GlobalTracer.get();
}
}案例:某微服务系统用Jaeger发现库存服务API耗时1.5s,定位到Redis连接池不足,扩容后恢复正常。
实践:部署Jaeger,在服务中添加OpenTracing注解。
4. 数据库优化:解决慢查询
场景:数据库常是性能瓶颈,需分析慢查询和锁冲突。
方法:用EXPLAIN分析SQL执行计划,优化索引和查询。
代码(MySQL慢查询分析):
-- 开启慢查询日志
SET GLOBAL slow_query_log = 'ON';
SET GLOBAL long_query_time = 1;
-- 分析查询
EXPLAIN SELECT * FROM orders WHERE user_id = 123 ORDER BY created_at;案例:某社交平台发现未索引的user_id导致全表扫描,加索引后查询时间从2s降至20ms。
实践:用MySQL慢查询日志,结合EXPLAIN优化SQL。
5. 压力测试:模拟极限场景
场景:通过负载测试暴露系统瓶颈。
method:用JMeter或Locust模拟高并发,观察资源瓶颈。
代码(Locust测试脚本):
from locust import HttpUser, task, between
class ApiUser(HttpUser):
wait_time = between(1, 3)
@task
def test_endpoint(self):
self.client.get("/api/orders")案例:某直播平台通过JMeter发现1000并发下CPU飙升,优化线程池后支持5000并发。
实践:用Locust模拟1000用户访问,分析响应时间和错误率。
典型的实践流程如下:
-
第一步:确认现象(如:接口超时、CPU飙高、吞吐量下降)
-
第二步:分析监控指标(从系统层面入手,如CPU、内存、磁盘IO、网络带宽)
-
第三步:锁定异常服务或模块(通过APM工具如SkyWalking、Pinpoint)
-
第四步:采样分析热点代码或慢SQL(使用火焰图、trace日志)
-
第五步:验证与回归(进行优化后对比测试)
一个实战案例:
某在线教育平台高峰期接口超时严重,通过对比Prometheus监控图发现,接口响应时间集中在数据库操作;通过慢SQL日志定位一条未命中索引的JOIN语句,优化后TPS提升近3倍。
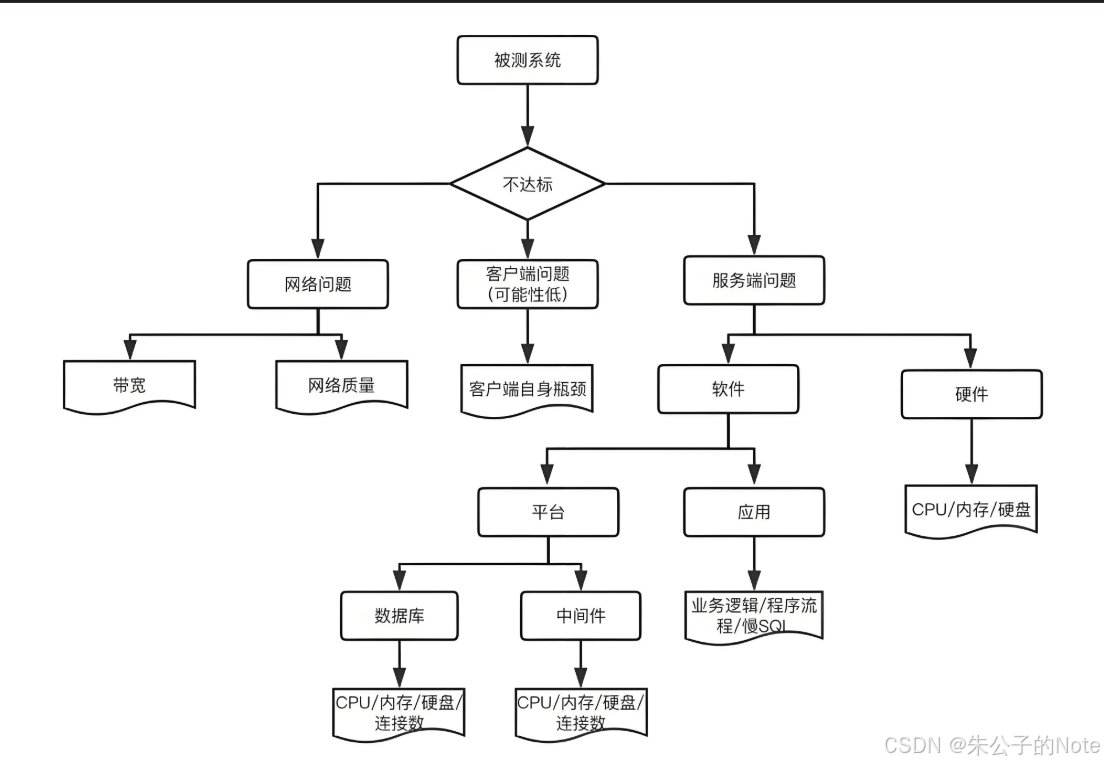
软件性能测试目标
软件性能测试的目的主要有以下三点:
-
评价系统当前性能,判断系统是否满足预期的性能需求。
-
寻找软件系统可能存在的性能问题,定位性能瓶颈并解决问题。
-
判定软件系统的性能表现,预见系统负载压力,在应用部署之前,评估系统性能。
而对于用户来说,则最关注的是当前系统:
-
是否满足上线性能要求?
-
系统极限承载如何?
-
系统稳定性如何?
软件性能测试中关键指标
资源指标

资源指标
-
CPU使用率:
指用户进程与系统进程消耗的CPU时间百分比,长时间情况下,一般可接受上限不超过85%。
-
内存利用率:
内存利用率=(1-空闲内存/总内存大小)*100%,一般至少有10%可用内存,内存使用率可接受上限为85%。
-
磁盘I/O:
磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘读写性能。
-
网络带宽:
一般使用计数器Bytes Total/sec来度量,Bytes Total/sec表示为发送和接收字节的速率,包括帧字符在内。判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
系统指标
-
并发用户数:
某一物理时刻同时向系统提交请求的用户数。
-
在线用户数:
某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。
-
平均响应时间:
系统处理事务的响应时间的平均值。事务的响应时间是从客户端提交访问请求到客户端接收到服务器响应所消耗的时间。对于系统快速响应类页面,一般响应时间为3秒左右。
-
事务成功率:
性能测试中,定义事务用于度量一个或者多个业务流程的性能指标,如用户登录、保存订单、提交订单操作均可定义为事务
-
超时错误率:
主要指事务由于超时或系统内部其它错误导致失败占总事务的比率。
性能问题排查的过程
在性能测试过程中,如果出现性能问题,需要测试人员重点关注资源指标和系统指标或者应用性能数据,系统指标是直接观测到的测试数据,比如响应时间过长,事物请求成功率低,超时错误率高等等。
当系统指标出现问题时一般会表现在资源指标上,比如cpu高,内存占用多,网络宽带占用高,连接数多等。
当观测到系统资源异常时,比如响应时间长,事物成功率低,超时错误率高等情况时。应该先查应用相关信息,比如日志,应用监控、数据库等等信息,如果这些信息没有问题,再对资源信息进行分析。
资源信息分析如下:
-
CPU问题分析:
一般情况下CPU满负荷工作,有时候并不能判定为CPU出现瓶颈,比如Linux总是试图要CPU尽可能的繁忙,使得任务的吞吐量最大化,即CPU尽可能最大化使用。因此,一般判断CPU为瓶颈,主要从两方面:一是CPU空闲持续为0,二是运行队列大于CPU核数(经验值3-4倍),即可判定存在瓶颈,对于CPU高消耗主要由什么引起的,可能是应用程序不合理造成,也可能是硬件资源不足,需要具体问题具体分析,比如问题SQL语句引起,则需要跟踪并优化引起CPU使用过高的SQL语句。
-
内存问题分析:
一般至少有10%可用内存,内存使用率可接受上限为85%。当空闲内存变小时,系统开始频繁地调动磁盘页面文件,空闲内存过小可能是内存不足或内存泄漏引起,需要根据系统实际情况监控分析。
-
磁盘I/O问题分析:
磁盘I/O对于数据库服务器、文件服务器、流媒体服务器系统来说,更容易成为瓶颈,一般从以下几个方面对磁盘I/O进行分析判断:
每磁盘I/O数可用来与磁盘的I/O能力进行对比,如果经过计算得到的每磁盘I/O数超过了磁盘标称的I/O能力,则说明确实存在磁盘的性能瓶颈。
监控磁盘读写,如果磁盘长时间进行大数据量读写操作,且cpu等待超过20%,则说明磁盘I/O存在问题,考虑提高磁盘I/O读写性能。
-
网络带宽问题分析:判断网络带宽是否是系统运行性能瓶颈的首要条件是网络带宽是否会影响系统交易执行性能。例如:减小网络带宽,并发用户数、响应时间与事务通过率等性能指标是否不能接受;或者增加网络带宽,并发用户数、响应时间与事务通过率等性能指标会得到明显提高。
在实际性能测试中,如果发现始终报连接超时,而实际手工访问可以正常访问,可以通过ping应用服务器IP或网关IP,如果出现网络严重延迟或丢包,则说明网络不稳定,需要检查网络。
通过对资源指标的分析,实际上各个方面都是互相依赖的,不能孤立的单从某个方面进行排查。
当一个方面出现性能问题时,往往会引发其他方面的性能问题,例如,大量的磁盘读写势必消耗CPU和IO资源,而内存的不足会导致频繁地进行内存页写入磁盘、磁盘写到内存的操作,造成磁盘IO瓶颈,同时,大量的网络流量也会造成CPU过载,所以,在分析性能问题时,需要从各个方面进行考虑。
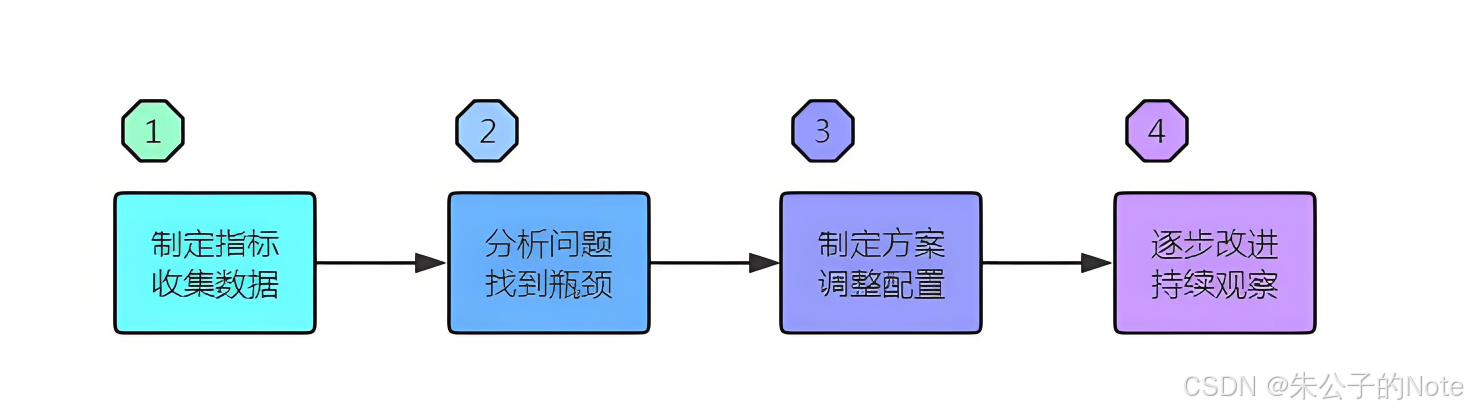
软件性能测试是执行、监控、分析、调优不断进行的过程,即监控是为分析提供更多的参考数据,分析是为了进行调优,调优是解决当前系统存在的性能瓶颈,为用户提供更好、更快的客户体验。
由于分析、调优需要根据具体问题进行具体分析,本文未做过多说明,只对通用的关键指标进行监控分析,建议在实际工作中可从资源指标与系统指标两个方面,层层检测、步步排查,性能问题就无处藏身,一旦找到出现问题的原因,性能问题也就迎刃而解!
小结
随着业务量激增、微服务复杂化、容器化普及,传统靠“经验拍脑袋”的调优方式早已难以为继。只有具备系统化性能分析能力,才能应对日趋复杂的分布式系统挑战。测试人员不仅要懂代码,还要具备“后端工程师思维”。
全链路监控、日志分析、分布式追踪、数据库优化和压力测试——这五大思路构成了服务端性能瓶颈定位的完整体系。它们不仅帮你快速找到问题根因,还提升了系统稳定性和用户体验。性能优化是服务端开发的试金石——通过系统化排查,你的系统将如磐石般稳固
别让性能瓶颈成为你系统的“隐形杀手”,更别让你自己成为那个“最后才知道问题在哪”的人。



















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









