










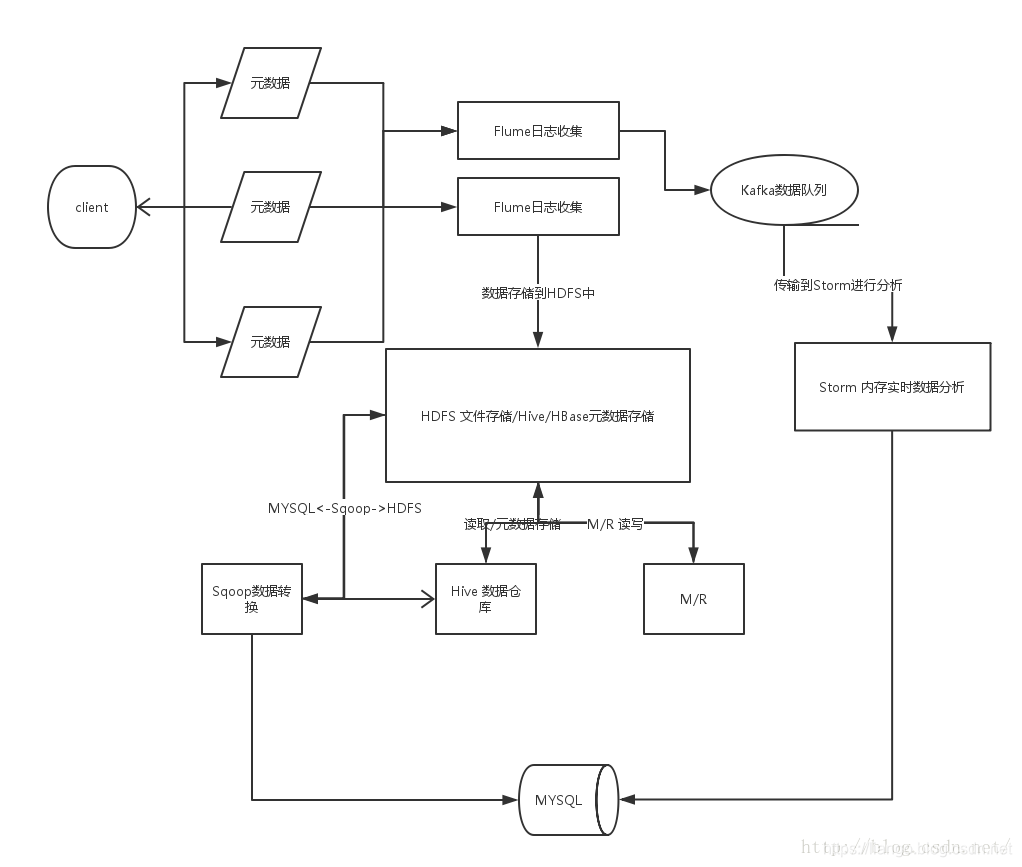
链接: https://blog.csdn.net/qq_26840065/article/details/51482920#
链接: kafka2.9.2的伪分布式集群安装和demo(java api)测试 https://mshk.top/2014/08/kafka/
链接: kafka+flume+hdfs实时日志流系统初探 https://blog.csdn.net/feinifi/article/details/73929015
新建一个flume的.properties文件
vim flume-conf-kafka2hdfs.properties
# ------------------- 定义数据流----------------------
# source的名字
flume2HDFS_agent.sources = source_from_kafka
# channels的名字,建议按照type来命名
flume2HDFS_agent.channels = mem_channel
# sink的名字,建议按照目标来命名
flume2HDFS_agent.sinks = hdfs_sink
#auto.commit.enable = true
## kerberos config ##
#flume2HDFS_agent.sinks.hdfs_sink.hdfs.kerberosPrincipal = flume/datanode2.hdfs.alpha.com@OMGHADOOP.COM
#flume2HDFS_agent.sinks.hdfs_sink.hdfs.kerberosKeytab = /root/apache-flume-1.6.0-bin/conf/flume.keytab
#-------- kafkaSource相关配置-----------------
# 定义消息源类型
# For each one of the sources, the type is defined
flume2HDFS_agent.sources.source_from_kafka.type = org.apache.flume.source.kafka.KafkaSource
flume2HDFS_agent.sources.source_from_kafka.channels = mem_channel
flume2HDFS_agent.sources.source_from_kafka.batchSize = 5000
# 定义kafka所在的地址
#flume2HDFS_agent.sources.source_from_kafka.zookeeperConnect = 10.129.142.46:2181,10.166.141.46:2181,10.166.141.47:2181/testkafka
flume2HDFS_agent.sources.source_from_kafka.kafka.bootstrap.servers = 192.168.2.86:9092,192.168.2.87:9092
# 配置消费的kafka topic
#flume2HDFS_agent.sources.source_from_kafka.topic = itil_topic_4097
flume2HDFS_agent.sources.source_from_kafka.kafka.topics = mtopic
# 配置消费的kafka groupid
#flume2HDFS_agent.sources.source_from_kafka.groupId = flume4097
flume2HDFS_agent.sources.source_from_kafka.kafka.consumer.group.id = flumetest
#---------hdfsSink 相关配置------------------
# The channel can be defined as follows.
flume2HDFS_agent.sinks.hdfs_sink.type = hdfs
# 指定sink需要使用的channel的名字,注意这里是channel
#Specify the channel the sink should use
flume2HDFS_agent.sinks.hdfs_sink.channel = mem_channel
#flume2HDFS_agent.sinks.hdfs_sink.filePrefix = %{host}
flume2HDFS_agent.sinks.hdfs_sink.hdfs.path = hdfs://192.168.2.xx:8020/tmp/ds=%Y%m%d
#File size to trigger roll, in bytes (0: never roll based on file size)
flume2HDFS_agent.sinks.hdfs_sink.hdfs.rollSize = 0
#Number of events written to file before it rolled (0 = never roll based on number of events)
flume2HDFS_agent.sinks.hdfs_sink.hdfs.rollCount = 0
flume2HDFS_agent.sinks.hdfs_sink.hdfs.rollInterval = 3600
flume2HDFS_agent.sinks.hdfs_sink.hdfs.threadsPoolSize = 30
#flume2HDFS_agent.sinks.hdfs_sink.hdfs.codeC = gzip
#flume2HDFS_agent.sinks.hdfs_sink.hdfs.fileType = CompressedStream
flume2HDFS_agent.sinks.hdfs_sink.hdfs.fileType=DataStream
flume2HDFS_agent.sinks.hdfs_sink.hdfs.writeFormat=Text
#------- memoryChannel相关配置-------------------------
# channel类型
# Each channel's type is defined.
flume2HDFS_agent.channels.mem_channel.type = memory
# Other config values specific to each type of channel(sink or source)
# can be defined as well
# channel存储的事件容量
# In this case, it specifies the capacity of the memory channel
flume2HDFS_agent.channels.mem_channel.capacity = 100000
# 事务容量
flume2HDFS_agent.channels.mem_channel.transactionCapacity = 10000
修改对应的地址及主题等信息就哦了~
运行:
flume-ng agent -n flume2HDFS_agent -f flume-conf-kafka2hdfs.properties
控制台打开一个producer发送消息试一下吧:
kafka-console-producer --broker-list cdh5:9092 --topic mtopic
链接: https://blog.csdn.net/ltliyue/article/details/72914987
链接: Flume+Hadoop+Hive的离线分析系统基本架构 https://blog.csdn.net/ymh198816/article/details/51540715
Kafka Consumers
Java Client
while (running) {
ConsumerRecords<K, V> records = consumer.poll(Long.MAX_VALUE);
process(records); // application-specific processing
try {
consumer.commitSync();
} catch (CommitFailedException e) {
// application-specific rollback of processed records
}
}
C/C++ Client (librdkafka)
while (running) {
rd_kafka_message_t *rkmessage = rd_kafka_consumer_poll(rk, 500);
if (rkmessage) {
msg_process(rkmessage);
rd_kafka_message_destroy(rkmessage);
if ((++msg_count % MIN_COMMIT_COUNT) == 0)
rd_kafka_commit(rk, NULL, 0);
}
}
Python Client
try:
msg_count = 0
while running:
msg = consumer.poll(timeout=1.0)
if msg is None: continue
msg_process(msg) # application-specific processing
msg_count += 1
if msg_count % MIN_COMMIT_COUNT == 0:
consumer.commit(async=False)
finally:
# Shut down consumer
consumer.close()
Go Client
for run == true {
ev := consumer.Poll(0)
switch e := ev.(type) {
case *kafka.Message:
// application-specific processing
case kafka.Error:
fmt.Fprintf(os.Stderr, "%% Error: %v\n", e)
run = false
default:
fmt.Printf("Ignored %v\n", e)
}
}
链接: 详细 https://docs.confluent.io/3.1.0/clients/consumer.html#java-client
kafka contrib包之hadoop-consumer
kafka contrib包之hadoop-consumer: Kafka=>HDFS, 完成数据从kafka到hadoop的ETL。
代码: 链接: https://github.com/kafka-dev/kafka/tree/master/contrib
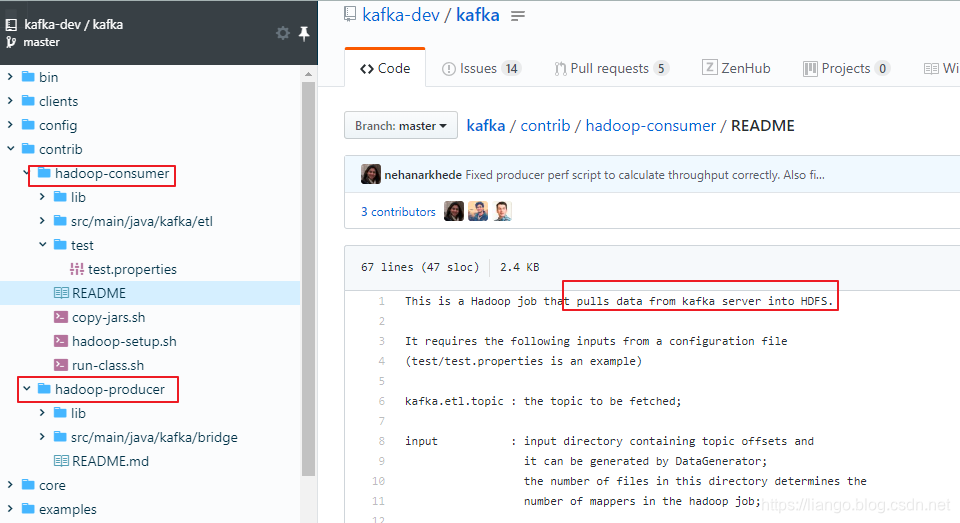
hadoop-consumer主要使用了lower Api去创建consumer,不像high api读起来顺畅。不过幸好有hadoop基础,关linkedin也不陌生,使用过他们的azkaban,也小看过源码。里面半于hadoop conf的创建一如即往的像azkaban。这块没问题。源码分析图如下:
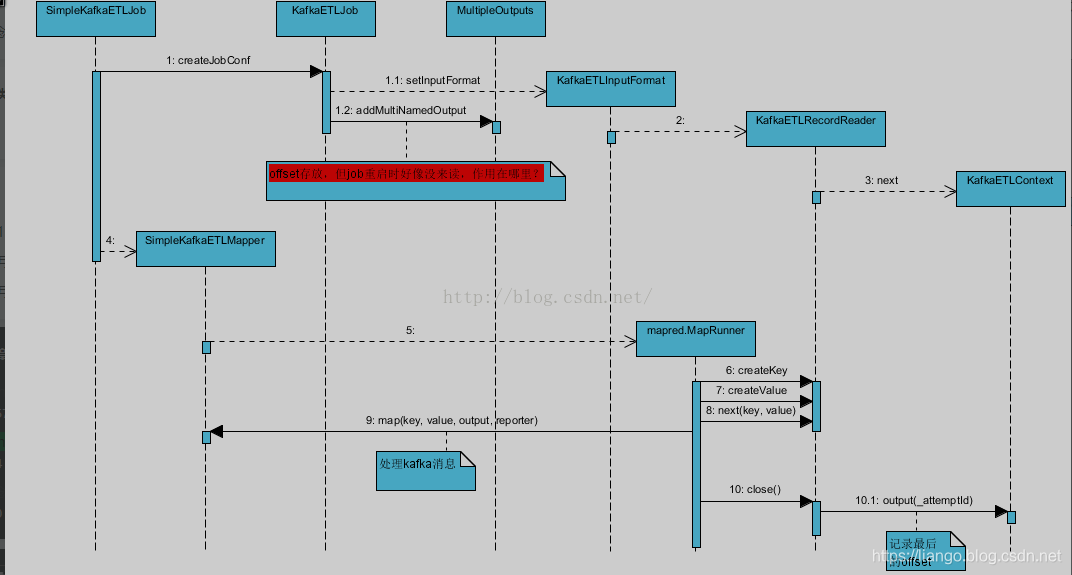
修改适合自己环境的参数/test/test.properties文件,
- 先运行kafka.etl.impl.DataGenerator,会创建一个生产者生成测试数据。
- 再运行kafka.etl.impl.SimpleKafkaETLJob。
提前将相关jar上传到hdfs路径下,具体位置在/test/test.properties配置。
job执行完后会在相应该目录下生成如下文件:
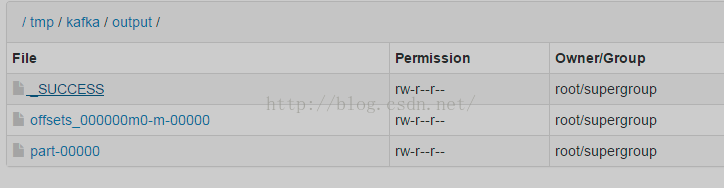
仔细看了下,part是kafka数据,offset是kafka数据偏移信息。这只是kafka官方给出的一个小例子,远达不到生产的需求。还需进一步学习,但从官网了解到linkedin有一个专门的项目用于kafka与hadoop的衔接,
Camus - LinkedIn’s Kafka=>HDFS pipeline. This one is used for all data at LinkedIn, and works great.
链接: Camus https://github.com/linkedin/camus
链接: 原文 https://blog.csdn.net/qnamqj/article/details/47276411














 4567
4567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









