







Kafka基础概念
Kafka中包含以下基础概念
1. Topic(话题):Kafka中用于区分不同类别信息的类别名称。由producer指定
2. Producer(生产者):将消息发布到Kafka特定的Topic的对象(过程)
3. Consumers(消费者):订阅并处理特定的Topic中的消息的对象(过程)
4. Broker(Kafka服务集群):已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息。
5. Partition(分区):Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
6. Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
消息
消息由一个固定大小的报头和可变长度但不透明的字节阵列负载。报头包含格式版本和CRC32效验和以检测损坏或截断
消息格式
1. 4 byte CRC32 of the message
2. 1 byte "magic" identifier to allow format changes, value is 0 or 1
3. 1 byte "attributes" identifier to allow annotations on the message independent of the version
bit 0 ~ 2 : Compression codec
0 : no compression
1 : gzip
2 : snappy
3 : lz4
bit 3 : Timestamp type
0 : create time
1 : log append time
bit 4 ~ 7 : reserved
4. (可选) 8 byte timestamp only if "magic" identifier is greater than 0
5. 4 byte key length, containing length K
6. K byte key
7. 4 byte payload length, containing length V
8. V byte payloadLog(日志)
- 日志是一个只能增加的,完全按照时间排序的一系列记录。我们可以给日志的末尾添加记录,并且可以从左到右读取日志记录。每一条记录都指定了一个唯一的有一定顺序的日志记录编号。详细见首席工程师揭秘LinkedIn大数据后台
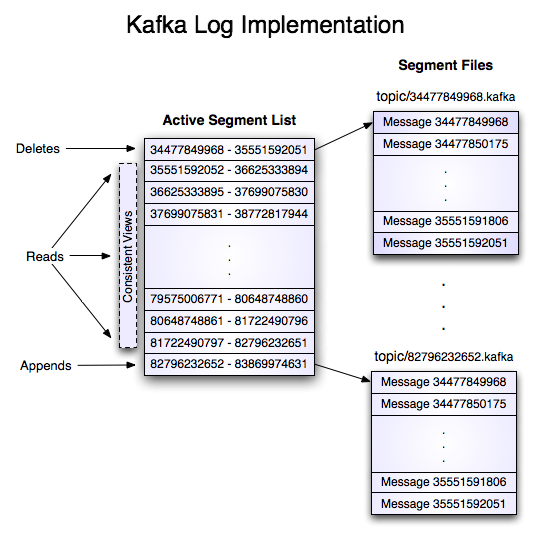
- 每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置
- 这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围。
Topic & Partition
- 为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。
- 每一个分区都是一个顺序的、不可变的消息队列, 并且可以持续的添加。分区中的消息都被分配了一个序列号,称之为偏移量(64字节的offset),在每个分区中此偏移量都是唯一的
- 因为每条消息都被append到该partition中,是顺序写磁盘,因此效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证)
- 每一条消息被发送到broker时,会根据paritition规则选择被存储到哪一个partition。如果partition规则设置的合理,所有消息可以均匀分布到不同的partition里,这样就实现了水平扩展。(如果一个topic对应一个文件,那这个文件所在的机器I/O将会成为这个topic的性能瓶颈,而partition解决了这个问题)。在创建topic时可以在$KAFKA_HOME/config/server.properties中指定这个partition的数量(如下所示),当然也可以在topic创建之后去修改parition数量
- 在发送一条消息时,可以指定这条消息的key,producer根据这个key和partition机制来判断将这条消息发送到哪个parition。paritition机制可以通过指定producer的paritition. class这一参数来指定,该class必须实现kafka.producer.Partitioner接口。本例中如果key可以被解析为整数则将对应的整数与partition总数取余,该消息会被发送到该数对应的partition。(每个parition都会有个序号)
- key相同的消息会被发送并存储到同一个partition里,而且key的序号正好和partition序号相同。(partition序号从0开始,本例中的key也正好从0开始)
offset
- 在每个分区中此偏移量都是唯一的
- 消费者所持有的仅有的元数据就是这个偏移量,也就是消费者在这个log中的位置。 这个偏移量由消费者控制。
- 正常情况当消费者消费消息的时候,偏移量也线性的的增加。但是实际偏移量由消费者控制,消费者可以将偏移量重置为更老的一个偏移量,重新读取消息。
- 一个消费者的操作不会影响其它消费者对此log的处理














 3833
3833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









