









一、背景
系统:CentOS Linux release 7.9.2009 (Core)
Kafka版本:2.11-2.0.0.3.1.4.0-315 [scala版本2.11;kafka 2.0.0版本;基于ambari3.1.4.0-315的版本 ]
二、现象
业务系统中总是报警:kafka消费延迟。
三、问题排查过程
1、通过监控发现,某个topic A(脱敏名)在业务高峰的时候,总是报消费延迟。
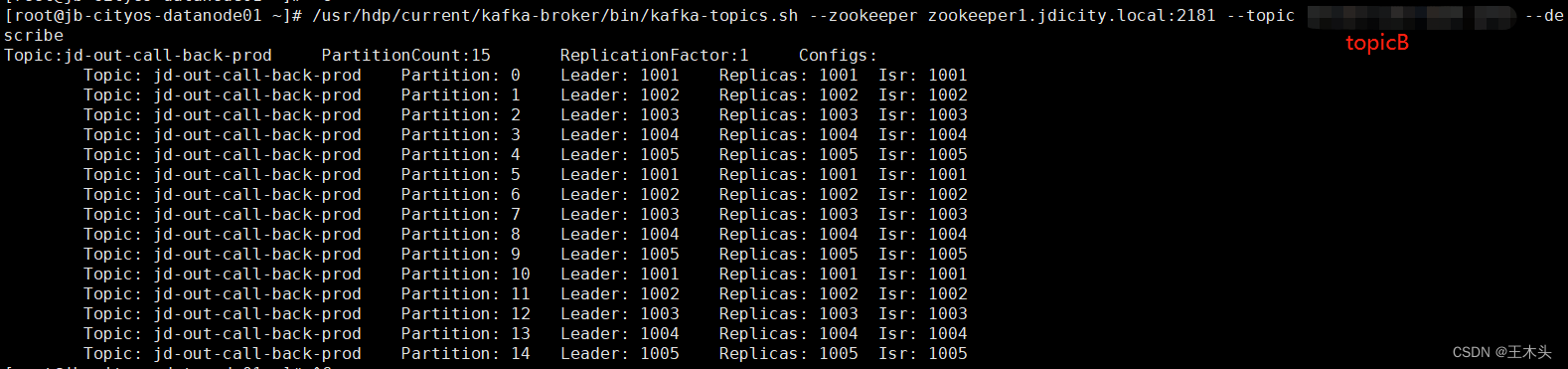
2、不过经过查看监控发现,也有其他topic B(脱敏名)在峰值时,跟topic A生产数据量差不多,但是不会报消费延迟。
3、查看消费速度,发现topic A的消费速率比topicB的消费速率低不少。消费延迟由此产生。
4、查看topic A的分区发现,只有1个分区;而topic B的分区数量是20个。

5、确定业务上消费者程序是4个。
四、原因分析
经过排查发现,topic A消费力差的原因是消费者数量太少。业务峰值时消费压力大大超过了单个消费者的消费能力(每个消费者同时在消费其他topic的数据)。
五、解决
增加分区数,提高消费并行度。
1、选取最佳分区数
当前5个kafka broker,有4个消费者程序。所以出于消费压力和存储负载的考虑,最佳分区数应该是4*5=20个。
2、获取基础重分配文件内容
首先填写当前topic的消息,用于获取重分配文件
{"topics":[{"topic":"topicA"}],"version":1}
获取topicA的分区和副本数json格式结果
/usr/hdp/current/kafka-broker/bin/kafka-reassign-partitions.sh --zookeeper zookeeper1.jdicity.local:2181 --topics-to-move-json-file topic-to-move.json --broker-list "1001,1002,1003,1004,1005" --generate
获取Proposed的json,作为后面重分配json文件的基础

3、增加分区数
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --zookeeper zookeeper1.jdicity.local:2181 --topic topicA --alter --partitions 20
4、规划分区与broker的对应关系,编辑重分配json文件reassign-plan.json(20分区,3副本)
通过
{
"version":1,
"partitions":[
{
"topic":"topicA",
"partition":0,
"replicas":[
1003,
1002,
1001
]
},
{
"topic":"topicA",
"partition":1,
"replicas":[
1002,
1003,
1004
]
},
{
"topic":"topicA",
"partition":2,
"replicas":[
1003,
1004,
1005
]
},
……
{
"topic":"topicA",
"partition":19,
"replicas":[
1003,
1004,
1005
]
}
]
}
5、执行重分配
/usr/hdp/current/kafka-broker/bin/kafka-reassign-partitions.sh --zookeeper zookeeper1.jdicity.local:2181 --reassignment-json-file reassign-plan.json --execute
6、查看结果
/usr/hdp/current/kafka-broker/bin/kafka-reassign-partitions.sh --zookeeper zookeeper1.jdicity.local:2181 --reassignment-json-file reassign-plan.json --verify
执行中:

已经完成:

分区和副本数已经更改:

六、反思与规避
分区数增加后,未出现相同消费延迟的问题。
好记性不如赖笔头。
与君共勉。















 3040
3040











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









