









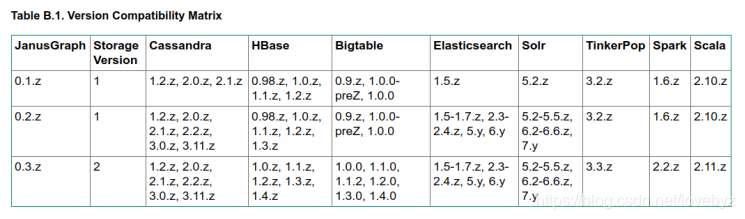
JanusGraph各组件版本兼容性匹配表
JanusGraph
JanusGraph提供多种后端存储和后端索引,使其能够更灵活的部署。本章介绍了几种可能的部署场景,以帮助解决这种灵活性带来的复杂性。
在讨论部署场景之前,理解JanusGraph本身的角色定位和后端存储的角色定位是非常重要的。首先,应用程序与JanusGraph进行交互大多数情况下都是进行Gremlin遍历,然后,JanusGraph把遍历请求发给配置好的后端(存储后端、索引后端)执行遍历处理。当JanusGraph以服务的形式被使用的时候,将不会有主服务(master JanusGraph Server)。应用程序可以连接任何一个JanusGraph服务实例。这样就可以使用负载均衡把请求分配到不同的实例上。JanusGraph服务实例之间本身是没有之间联系的,当遍历处理增大的时候这更容易扩容。
JanusGraph与Apache Cassandra的好处
- 连续可用,没有单点故障。
- 由于没有主/从架构,因此图形没有读/写瓶颈。
- 弹性可扩展性允许引入和移除机器。
- 缓存层可确保内存中可连续访问的数据。
- 通过向群集添加更多计算机来增加缓存的大小。
- 与Apache Hadoop集成。
Cassandra本身优点:
- 适合做数据分析或数据仓库这类需要迅速查找且数据量大的应用
- 存储结构比Key-Value数据库(像Redis)更丰富
- Cassandra 的数据模型是基于Column族的四维或五维模型(聚合查询在列表上执行得更快)
Cassandra本身缺点:
- 不能简单增加服务器解决请求量增长的问题,需要数据架构师精细的规划
- 数据先缓存到Mentable,再刷新到磁盘,
- Memtable
JanusGraph与HBase的好处
- 与Apache Hadoop生态系统紧密集成。
- 本机支持强一致性。
- 通过添加更多机器实现线性可扩展性。
- 严格一致的读写操作。
- 方便的基类,用于使用HBase表支持Hadoop MapReduce作业。
- 支持通过JMX导出指标。
JanusGraph和CAP定理
使用数据库时,应充分考虑CAP定理(C =一致性,A =可用性,P =可分区性)
- HBase以产量为代价优先考虑一致性,即完成请求的概率。
- Cassandra以收获为代价优先考虑可用性,即查询答案的完整性(可用数据/完整数据)。
JanusGraph的CAP
CAP定理说的是:一个分布式计算机系统无法同时满足以下三点(定义摘自Wikipedia):
- 一致性(Consistency) ,所有节点访问同一份最新的数据副本
- 可用性(Availability),每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据
- 分区容错性(Partition tolerance),以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
关于JanusGraph在CAP理论上的侧重,是要看底层存储的。如果底层是Cassandra,那么就是偏向于AP(Cassandra是最终一致性的);如果底层是HBase,就是偏向于CP(强一致性);BerkleyDB单机不存在这个问题。
JG. Version 0.3.1各依赖组件版本兼容性 (Release Date: October 2, 2018)
<dependency>
<groupId>org.janusgraph</groupId>
<artifactId>janusgraph-core</artifactId>
<version>0.3.1</version></dependency>
Tested Compatibility:
- Apache Cassandra 2.1.20, 2.2.10, 3.0.14, 3.11.0
- Apache HBase 1.2.6, 1.3.1, 1.4.4
- Google Bigtable 1.0.0, 1.1.2, 1.2.0, 1.3.0, 1.4.0
- Oracle BerkeleyJE 7.4.5
- Elasticsearch 1.7.6, 2.4.6, 5.6.5, 6.0.1
- Apache Lucene 7.0.0
- Apache Solr 5.5.4, 6.6.1, 7.0.0
- Apache TinkerPop 3.3.3
- Java 1.8
有关0.3.1中的功能和错误修复的更多信息,请参阅GitHub milestone:
JG安装配置
JanusGraph0.3.1 OLAP开发环境搭建
https://blog.csdn.net/qq_37286005/article/details/85071050
安装zookeeper
这里安装的是单机模式。版本是zookeeper-3.4.9.tar.gz。已装,步骤略。(看我博客-集群安装)
安装Hbase单机模式
配置Hbase
1.下载:https://mirrors.tuna.tsinghua.edu.cn/apache/hbase/2.1.2/hbase-2.1.2-bin.tar.gz
2.~$ gedit .bashrc
# hbase
export HBASE_HOME=/home/raini/app/hbase
export PATH=${HBASE_HOME}/bin:$PATH3.~$ source .bashrc
hbase-env.sh
## 追加:
export JAVA_HOME=/home/raini/app/jdk
export HBASE_CLASSPATH=/home/raini/app/hbase/conf/
export HBASE_PID_DIR=/home/raini/app/tmp/pids
# 不使用HBase自带的zookeeper
export HBASE_MANAGES_ZK=false
zoo.cfg
在这里我们使用的不是HBase自带的zookeeper,而是之前已经装好的,所以需要将我们现在的zookeeper的zoo.cfg文件复制到hbase的conf目录下
hbase-site.xml
#添加如下内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://biyuzhe:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>127.0.0.1</value>
</property>
<!-- <property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/raini/app/tmp/hbase/</value>
</property>
<property>
<name>hbase.master</name>
<value>biyuzhe:60000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/raini/app/tmp/hbase_zoo_dataDir</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>file://home/raini/tmp/hbase-wal</value>
</property>-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hbase.master.maxclockskew</name>
<value>150000</value>
</property>
<property>
一些注意点:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///usr/local/hbase-1.4.0/data-tmp</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>localhost</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/tmp/zookeeper</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase</value>
</property>
</configuration>注意的环节:
- 一定要加上“伪分布:hbase.cluster.distributed”的这个<property>标签,否则即使是单机的分布【虽然是单机,但是并没有使用HBase自带的zookeeper】,所以理论上还是应该使用伪分布式的搭配。
- hbase.rootdir这个属性的值在笔者的环境下是file:///usr/local/hbase-1.4.0/data-tmp,并没有使用hdfs来存储。也就意味着不需要事先启动hdfs。但是如果将这个目录改为hdfs的对应目录,则是需要在启用hbase之前启用hdfs。
- hbase.zookeeper.quorum指的是zookeeper服务器的地址,因为这里是单机版,所以直接填写localhost即可。有些博客建议写与hostname不同的主机ip。
- hbase.zookeeper.property.clientPort指的是zookeeper的端口号,如果没有修改的话,默认的则是2181。
- zookeeper.znode.parent ZooKeeper中的Hbase的根ZNode。所有的Hbase的ZooKeeper会用这个目录的值来配置相对路径。【znode存放root region的地址】默认情况下,所有的Hbase的ZooKeeper文件路径是用相对路径,所以他们会都去这个目录下面。默认: /hbase
---------------------
regionservers
#修改为主机名 <----建议写与hostname不同的主机ip
启动HBase
[raini@biyuzhe ~]# start-all.sh #启动hadoop
[raini@biyuzhe ~]# zkServer.sh start #启动zookeeper
[raini@biyuzhe ~]# zkServer.sh status #查看zookeeper状态以及角色
[raini@biyuzhe ~]# start-hbase.sh #启动Hbase
启动报错:Caused by: java.lang.ClassNotFoundException: org.apache.htrace.SamplerBuilder

解决:
cp $HBASE_HOME/lib/client-facing-thirdparty/htrace-core-3.1.0-incubating.jar $HBASE_HOME/lib/
[raini@biyuzhe ~]# JPS 查看hbase进程

Hbase简单操作
raini@biyuzhe:~$ hbase shell
hbase(main):001:0> status #查看HBase运行状态
1 active master, 0 backup masters, 1 servers, 0 dead, 0.0000 average load
Took 0.3634 seconds
hbase(main):002:0> exit #退出
遇到问题
hbase集群[部分]节点HRegionServer启动后自动关闭的问题
注释掉hbase-size.xml这部分得以解决:
<!-- <property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/home/raini/app/tmp/hbase/</value>
</property>
<property>
<name>hbase.master</name>
<value>biyuzhe:60000</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/raini/app/tmp/hbase_zoo_dataDir</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>file://home/raini/tmp/hbase-wal</value>
</property>-->:应该是旧数据的影响,可删除掉这些临时文件
JG+HBase+Caching+ES config
设置JanusGraph使用远程运行的HBase存储引擎,为了获取更好的性能,同时使用JanusGraph的缓存组件。
janusgarph.properties:
storage.backend=hbase
storage.hostname=100.100.101.1
storage.port=2181
cache.db-cache = true
cache.db-cache-clean-wait = 20
cache.db-cache-time = 180000
cache.db-cache-size = 0.5
index.search.backend=elasticsearch
index.search.hostname=100.100.101.1, 100.100.101.2
index.search.elasticsearch.client-only=true
使用该配置遇到问题:

janusGraph(Hbase客户端)连不上Hbase服务器,zookeeperNode我们在Hbase安装时hbase-site.xml设置成了/hbase-jg,所以这里需要明确指定:
storage.hbase.ext.hbase.zookeeper.property.clientPort=2181
storage.hbase.ext.zookeeper.znode.parent=/hbase-jp
JanusGraph单机部署-2法
注:
[1] ElasticSearch因为是压缩包的方式,只能以非root用户启动,所以需要使用普通用户安装
[2] Linux下JanusGraph自带了一个JanusGraph Server的配置和脚本,可以直接启动JanusGraph Server;
Linux下JanusGraph的安装步骤
- [1] 将压缩包上传到用户根目录下并解压
注意:这里假设用户名为raini,不能用root,前面已说明。
- [2] 修改权限
修改安装包的权限,以便raini用户能够访问/opt下的janusgraph包
raini@biyuzhe:~/app$ sudo chown -R raini:raini janusgraph-0.3.1-hadoop2
- JanusGraph的启动
本文采用的是JanusGraph+Berkeley+ES的部署模式,也就是说后端存储采用BerkeleyDB、外部索引采用ElasticSearch。因此,BerkeleyDB是嵌入式的,不需要单独启动,但ElasticSearch需要在JanusGraph之前启动。
- 启动ElasticSearch
JanusGraph自带了ElasticSearch的安装包,先进入该目录,加上&以便在后台启动
raini@biyuzhe:~/app/janusgraph$ elasticsearch/bin/elasticsearch &
- JanusGraph的基本使用
JanusGraph的使用方式通常包括:
[1] 以嵌入式开发(Java)的方式访问;
[2] 通过Gremlin Console控制台访问;
[3] 通过JanusGraph Server的方式访问;
这里先只介绍Gremlin Console的方式,其他方式将在后面陆续介绍。
- JanusGraph Gremlin Console
[1] 启动Gremlin Console
[raini@biyuzhe: janusgraph-0.3.1-hadoop2]$ bin/gremlin.sh

[2] 开启一个图数据库实例
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-berkeleyje-es.properties')
==>standardjanusgraph[berkeleyje:/opt/janusgraph-0.3.1-hadoop2/conf/../db/berkeley]
JanusGraph默认有很多种配置,这里采用文前提到的配置模式。
[3] 获取图遍历句柄
gremlin> g = graph.traversal()
==>graphtraversalsource[standardjanusgraph[berkeleyje:/opt/janusgraph-0.3.1-hadoop2/conf/../db/berkeley], standard]
[4] 通过图遍历句柄来进行各种图操作
新增一个顶点(vertex)
gremlin> g.addV('person').property('name','Dennis')
==>v[4104]
查询刚刚创建的顶点
gremlin> g.V().has('name', 'Dennis').values()
参考资料:
[1] http://janusgraph.org/
启动janusGraph(gremlin-server)
备注:不要直接启动bin目录下的gremlin-server.sh,会缺少初始化,elasticsearch和cassandra等配置。
cd /path_to/janusgraph-0.3.1-hadoop2 使用:
bin/janusgraph.sh start
- 启动ElasticSearch
JanusGraph自带了ElasticSearch的安装包,先进入该目录,加上&以便在后台启动
raini@biyuzhe:~/app/janusgraph$ elasticsearch/bin/elasticsearch &
raini@biyuzhe:~/app/janusgraph$ bin/janusgraph.sh stop
启动janusgraph server:
bin/gremlin-server.sh ./conf/gremlin-server/byz-gremlin-server.yaml
JanusGraph Server
JanusGraph通过gremlin-server提供服务,有两种模式:WebSocket和HTTP,两种模式无法同时存在于同一个实例上,但是可以通过创建两个实例达到共存的目的---(0.3以后貌似可以共存了,接下来测试一下)。官网描述略长,这里总结得简单一些。默认后端使用HBase+ElasticSearch。
具体步骤如下:
1. 从Github release页下载 janusgraph-{VERSION}-hadoop2.zip ,并解压
2. 准备 .properties 文件
| cp conf/janusgraph-hbase-es.properties conf/gremlin-server/janusgraph-hbase-es-server.properties |
并在新文件开始添加
| gremlin.graph=org.janusgraph.core.JanusGraphFactory |
3. 准备 gremlin-server.yaml ,这里写了两个实例配置
| cp conf/gremlin-server/gremlin-server.yaml conf/gremlin-server/socket-gremlin-server.yaml cp conf/gremlin-server/gremlin-server.yaml conf/gremlin-server/http-gremlin-server.yaml |
3.1 修改 socket-gremlin-server.yaml
| // host和port不爽也可以改,默认8182 graphs: { graph: conf/gremlin-server/janusgraph-hbase-es-server.properties } channelizer: org.apache.tinkerpop.gremlin.server.channel.WebSocketChannelizer |
3.2 修改 http-gremlin-server.yaml
| // port一定不要和websocket模式的冲突了…… 我设置的8183 graphs: { graph: conf/gremlin-server/janusgraph-hbase-es-server.properties } channelizer: org.apache.tinkerpop.gremlin.server.channel.HttpChannelizer |
4. 启动server
| bin/gremlin-server.sh ./conf/gremlin-server/socket-gremlin-server.yaml bin/gremlin-server.sh ./conf/gremlin-server/http-gremlin-server.yaml |
成功后会在屏幕上打log
| [gremlin-server-boss-1] INFO org.apache.tinkerpop.gremlin.server.GremlinServer - Channel started at port XXXX.
Ps:因为我配置的host是[0.0.0.0],所以service启动的机器可能不确定,我这里是node3。 所以如下conf/remote.yaml中也需要配置为node3才能连接上
|
5.1 测试WebSocket
使用gremlin测试,打开 bin/gremlin.sh
| ~/Setups/janusgraph-0.3.1-hadoop2/bin> bin/gremlin.sh
\,,,/ (o o) -----oOOo-(3)-oOOo----- plugin activated: janusgraph.imports plugin activated: tinkerpop.server plugin activated: tinkerpop.utilities plugin activated: tinkerpop.hadoop plugin activated: tinkerpop.spark plugin activated: tinkerpop.tinkergraph gremlin> :remote connect tinkerpop.server conf/byz-remote.yaml ==>Configured localhost/127.0.0.1:8182 gremlin> :remote console (如果不执行这一步,往下每一个操作的命令前都要加上 :> 如 :>g.V().values('name')) gremlin> ==>yiz96 |
:> 符号是立即执行的意思。如果修改过port,同时也要修改一下 conf/remote.conf 。
5.2 测试HTTP
| 1 | curl -XPOST -Hcontent-type:application/json -d '{"gremlin":"g.V().values(\"name\")"}' http://localhost:8183 |
注意不要使用单引号,会报错
| 1 | {"requestId":"6542a2b5-15bb-4b8e-82cd-50ea1d12e586","status":{"message":"","code":200,"attributes":{}},"result":{"data":["yiz96"],"meta":{}}}% |
失败了:

问题:(启动remote服务报错)
java.lang.IllegalStateException: javax.script.ScriptException: javax.script.ScriptException: groovy.lang.MissingPropertyException: No such property: graph for class: Script1
使用:
gremlin> :remote connect tinkerpop.server conf/byz-remote.yaml
==>Configured localhost/127.0.0.1:8182
gremlin> :remote console
==>All scripts will now be sent to Gremlin Server - [localhost/127.0.0.1:8182] - type ':remote console' to return to local mode
gremlin> map = new HashMap<String, Object>();
gremlin> map
No such property: map for class: Script4
Type ':help' or ':h' for help.
Display stack trace? [yN]
gremlin>
解决:
(错误的解决):
scripts/empty-sample.groovy定义了默认图形“图形”上的绑定,该图形不可用。
需要从配置中更新或删除scripts/empty-sample.groovy。或者注释掉:
//定义默认的TraversalSource来绑定查询 - 这个将被命名为“g”。
// globals << [g:graph.traversal()]
正解:
不能去掉:scripts/empty-sample.groovy中~~ {files: [scripts/empty-sample.groovy]
如下加入正确的依赖即可:
问题:remote connect gremlin-server No such property: for class: Script
解决:
很简单,是自己使用问题。因为一般的教程、博客、官网都不会提到这个,还是去国外网站找到的。
加上session就行。
:remote connect tinkerpop.server conf/byz-remote.yaml session
:remote console
问题:GraphFactory could not instantiate this Graph implementation
1042 [main] WARN org.apache.tinkerpop.gremlin.server.GremlinServer - Graph [graph] configured at [conf/gremlin-server/ws-janusgraph-hbase-es.properties] could not be instantiated and will not be available in Gremlin Server. GraphFactory message: GraphFactory could not instantiate this Graph implementation [class org.janusgraph.core.JanusGraphFactory]
java.lang.RuntimeException: GraphFactory could not instantiate this Graph implementation [class org.janusgraph.core.JanusGraphFactory]
at org.apache.tinkerpop.gremlin.structure.util.GraphFactory.open(GraphFactory.java:82)
at org.apache.tinkerpop.gremlin.structure.util.GraphFactory.open(GraphFactory.java:70)
at org.apache.tinkerpop.gremlin.structure.util.GraphFactory.open(GraphFactory.java:104)
at org.apache.tinkerpop.gremlin.server.util.DefaultGraphManager.lambda$new$0(DefaultGraphManager.java:57)
at java.util.LinkedHashMap$LinkedEntrySet.forEach(LinkedHashMap.java:671)
at org.apache.tinkerpop.gremlin.server.util.DefaultGraphManager.<init>(DefaultGraphManager.java:55)
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.apache.tinkerpop.gremlin.server.util.ServerGremlinExecutor.<init>(ServerGremlinExecutor.java:80)
at org.apache.tinkerpop.gremlin.server.GremlinServer.<init>(GremlinServer.java:120)
at org.apache.tinkerpop.gremlin.server.GremlinServer.<init>(GremlinServer.java:84)
at org.apache.tinkerpop.gremlin.server.GremlinServer.main(GremlinServer.java:343)
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.tinkerpop.gremlin.structure.util.GraphFactory.open(GraphFactory.java:78)
... 13 more
Caused by: java.lang.IllegalArgumentException: Could not instantiate implementation: org.janusgraph.diskstorage.hbase.HBaseStoreManager
at org.janusgraph.util.system.ConfigurationUtil.instantiate(ConfigurationUtil.java:64)
at org.janusgraph.diskstorage.Backend.getImplementationClass(Backend.java:476)
at org.janusgraph.diskstorage.Backend.getStorageManager(Backend.java:408)
at org.janusgraph.graphdb.configuration.GraphDatabaseConfiguration.<init>(GraphDatabaseConfiguration.java:1254)
at org.janusgraph.core.JanusGraphFactory.open(JanusGraphFactory.java:160)
at org.janusgraph.core.JanusGraphFactory.open(JanusGraphFactory.java:131)
at org.janusgraph.core.JanusGraphFactory.open(JanusGraphFactory.java:111)
... 18 more
Caused by: java.lang.reflect.InvocationTargetException
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
at java.lang.reflect.Constructor.newInstance(Constructor.java:423)
at org.janusgraph.util.system.ConfigurationUtil.instantiate(ConfigurationUtil.java:58)
... 24 more
Caused by: java.lang.NoClassDefFoundError: org/apache/hadoop/hbase/protobuf/generated/MasterProtos$MasterService$BlockingInterface
at java.lang.Class.forName0(Native Method)
at java.lang.Class.forName(Class.java:264)
at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:228)
at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:218)
at org.apache.hadoop.hbase.client.ConnectionFactory.createConnection(ConnectionFactory.java:119)
at org.janusgraph.diskstorage.hbase.HBaseCompat1_0.createConnection(HBaseCompat1_0.java:43)
at org.janusgraph.diskstorage.hbase.HBaseStoreManager.<init>(HBaseStoreManager.java:334)
... 29 more
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.hbase.protobuf.generated.MasterProtos$MasterService$BlockingInterface
at java.net.URLClassLoader.findClass(URLClassLoader.java:382)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 36 more
解决:
引入hbase-protocol-1.4.9.jar与protobuf-java-2.5.0.jar包即可。
(必要时也可将hbase-hadoop2-compat-1.4.9.jar--hbase与hadoop的兼容性包 引入)
JanusGraph与TinkerPop的Hadoop-Gremlin整合
本章介绍如何利用Apache Hadoop和Apache Spark配置JanusGraph以进行分布式图形处理。这些步骤将概述如何开始这些项目,但请参考这些项目社区以更熟悉它们。
JanusGraph-Hadoop与TinkerPop的hadoop-gremlin包一起用于通用OLAP。
对于下面示例的范围,Apache Spark是计算框架,Apache Cassandra是存储后端。可以使用其他包进行指示,并对配置属性进行微小更改。
| 注意 | 本章中的示例基于在本地模式或独立群集模式下运行Spark。在YARN或Mesos上使用Spark时,需要进行其他配置。 |
配置Hadoop以运行OLAP
要从Gremlin控制台运行OLAP查询,需要满足一些先决条件。您需要将Hadoop配置目录添加到其中CLASSPATH,配置目录需要指向实时Hadoop集群。
Hadoop提供分布式访问控制的文件系统。运行在不同计算机上的Spark工作程序使用Hadoop文件系统来获得基于文件的操作的公共源。各种OLAP查询的中间计算可以保留在Hadoop文件系统上。
有关配置单节点Hadoop集群的信息,请参阅官方Apache Hadoop文档
一旦启动并运行Hadoop集群,我们将需要在中指定Hadoop配置文件CLASSPATH。下面的文档希望您将这些配置文件放在下面/etc/hadoop/conf。
验证后,按照以下步骤将Hadoop配置添加到CLASSPATH并启动Gremlin控制台,它将扮演Spark驱动程序的角色。
主要配置(bin/gremlin.sh)
在前边加入:
export HADOOP_HOME=/home/raini/app/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_OPTIONS="$JAVA_OPTIONS -Djava.library.path=$HADOOP_HOME/lib/native"
export CLASSPATH=$HADOOP_CONF_DIR
一旦添加了Hadoop配置的路径CLASSPATH,我们就可以通过以下快速步骤验证Gremlin控制台是否可以访问Hadoop集群:
从janusGraph中启动:
$ bin/gremlin.sh
在终端输入:
gremlin> hdfs
==>storage[org.apache.hadoop.fs.LocalFileSystem@65bb9029] // BAD(没配置之前)
gremlin> hdfs
==>storage[DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_1229457199_1, ugi=user (auth:SIMPLE)]]] // GOOD(配置之后,可见使用hdfs进行存储)
OLAP遍历(使用Spark)
JanusGraph-Hadoop使用TinkerPop的hadoop-gremlin包进行通用OLAP遍历图,并通过利用Apache Spark并行化查询。
配置使用Spark作为OLAP执行引擎+Hbase后端
将需要特定于该存储后端的附加配置。配置由gremlin.hadoop.graphReader属性指定,该属性指定从存储后端读取数据的类。
如JanusGraph的Hbase graphReader类:
HBaseInputFormat和HBaseSnapshotInputFormatHBase一起使用
以下属性文件可用于连接Hbase中的JanusGraph实例,以便它可以与HadoopGraph一起使用来运行OLAP查询。
Github地址:
https://github.com/JanusGraph/janusgraph/blob/d12adfbf083f575fa48860daa37bfbd0e6095369/janusgraph-dist/src/assembly/static/conf/hadoop-graph/read-hbase-snapshot.properties
conf/hadoop-graph/read-hbase-snapshot.properties
#
# Hadoop Graph Configuration
#
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
gremlin.hadoop.graphReader=org.janusgraph.hadoop.formats.hbase.HBaseSnapshotInputFormat
gremlin.hadoop.graphWriter=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
gremlin.hadoop.jarsInDistributedCache=true
gremlin.hadoop.inputLocation=none
gremlin.hadoop.outputLocation=output
#
# JanusGraph HBaseSnapshotInputFormat configuration
#
janusgraphmr.ioformat.conf.storage.backend=hbase
janusgraphmr.ioformat.conf.storage.hostname=localhost
janusgraphmr.ioformat.conf.storage.hbase.table=janusgraph
janusgraphmr.ioformat.conf.storage.hbase.snapshot-name=janusgraph-snapshot
janusgraphmr.ioformat.conf.storage.hbase.snapshot-restore-dir=/tmp
janusgraphmr.ioformat.conf.storage.hbase.ext.hbase.rootdir=/hbase
#
# SparkGraphComputer Configuration
#
spark.master=local[4]
spark.serializer=org.apache.spark.serializer.KryoSerializer
conf/hadoop-graph/read-hbase.properties
#
# Hadoop Graph Configuration
#
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
gremlin.hadoop.graphReader=org.janusgraph.hadoop.formats.hbase.HBaseInputFormat
gremlin.hadoop.graphWriter=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
gremlin.hadoop.jarsInDistributedCache=true
gremlin.hadoop.inputLocation=none
gremlin.hadoop.outputLocation=output
#
# JanusGraph HBase InputFormat configuration
#
janusgraphmr.ioformat.conf.storage.backend=hbase
janusgraphmr.ioformat.conf.storage.hostname=localhost
janusgraphmr.ioformat.conf.storage.hbase.table=janusgraph
#
# SparkGraphComputer Configuration
#
spark.master=local[4]
spark.serializer=org.apache.spark.serializer.KryoSerializer
。。。更多看文档:https://github.com/JanusGraph/janusgraph/blob/dee1400a3ab953ed5f4bd43eec8a38f2d7b6ff3c/docs/hadoop.adoc
使用Spark Standalone Cluster进行OLAP遍历
上一节中遵循的步骤也可以与Spark独立群集一起使用,只需进行少量更改:
更新spark.master属性以指向Spark主URL而不是本地URL
更新spark.executor.extraClassPath以启用Spark执行程序以查找JanusGraph依赖项jar
将JanusGraph依赖项jar复制到每个Spark执行器计算机上一步中指定的位置
| 注意 | 我们将janusgraph-distribution / lib下的所有jar复制到/ opt / lib / janusgraph /中,并在所有worker中创建相同的目录结构,并在所有worker中手动复制jar。 |
用于OLAP遍历的最终属性文件如下:
。。。
参考文档:
https://github.com/JanusGraph/janusgraph/blob/dee1400a3ab953ed5f4bd43eec8a38f2d7b6ff3c/docs/hadoop.adoc
小例子:
(gremlin以及其它参考配置:janusgraph/janusgraph-dist/src/assembly/static/conf/hadoop-graph/
g.V().hasLabel('NewsPaper').has('identifier', 'xyz').inE('belongsTo').outV().hasLabel('NewsDocument')
.has('publishedDate', between(begin.getTime, end.getTime))
数据类型
(导入数据第一步,首先去掉空行、缺失顶点、重复顶点等,然后将数据做成这种格式-GraphSon)
多条:
{"id":2000,"label":"message","inE":{"link":[{"id":5,"outV":2000}]},"outE":{"link":[{"id":4,"inV":2001},{"id":5,"inV":2000}]},"properties":{"name":[{"id":2,"value":"a"}]}}
{"id":2001,"label":"message","inE":{"link":[{"id":4,"outV":2000}]},"properties":{"name":[{"id":3,"value":"b"}]}}
{"id":1000,"label":"loops","inE":{"self":[{"id":1,"outV":1000}]},"outE":{"self":[{"id":1,"inV":1000}]},"properties":{"name":[{"id":0,"value":"loop"}]}}
单条:
{
"id": 2000,
"label": "message",
"inE": {
"link": [
{
"id": 5,
"outV": 2000
}
]
},
"outE": {
"link": [
{
"id": 4,
"inV": 2001
},
{
"id": 5,
"inV": 2000
}
]
},
"properties": {
"name": [
{
"id": 2,
"value": "a"
}
]
}
}
图形配置
janusgraph-hbase.properties:
gremlin.graph=org.janusgraph.core.JanusGraphFactory
storage.backend=hbase
storage.hostname=localhost
cache.db-cache=true
cache.db-cache-clean-wait=20
cache.db-cache-time=180000
cache.db-cache-size=0.5
index.search.backend=elasticsearch
index.search.hostname=localhost
#storage.hbase.ext.zookeeper.znode.parent=/hbase-unsecure
storage.hbase.table=Medical-POC
index.search.index-name=Medical-POC
hadoop-graphson.properties
#gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
#gremlin.hadoop.graphReader=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoInputFormat
#gremlin.hadoop.graphWriter=org.apache.tinkerpop.gremlin.hadoop.structure.io.gryo.GryoOutputFormat
#gremlin.hadoop.jarsInDistributedCache=true
gremlin.hadoop.defaultGraphComputer=org.apache.tinkerpop.gremlin.spark.process.computer.SparkGraphComputer
gremlin.graph=org.apache.tinkerpop.gremlin.hadoop.structure.HadoopGraph
gremlin.hadoop.graphInputFormat=org.apache.tinkerpop.gremlin.hadoop.structure.io.graphson.GraphSONInputFormat
gremlin.hadoop.graphOutputFormat=org.apache.hadoop.mapreduce.lib.output.NullOutputFormat
gremlin.hadoop.inputLocation=./data/byz/test-modern.json
gremlin.hadoop.outputLocation=output
gremlin.hadoop.jarsInDistributedCache=true
#####################################
# GiraphGraphComputer Configuration
#####################################
giraph.minWorkers=2
giraph.maxWorkers=2
giraph.useOutOfCoreGraph=true
giraph.useOutOfCoreMessages=true
mapred.map.child.java.opts=-Xmx1024m
mapred.reduce.child.java.opts=-Xmx1024m
giraph.numInputThreads=4
giraph.numComputeThreads=4
giraph.maxMessagesInMemory=100000
#
# SparkGraphComputer Configuration
#
#spark.master=local[4]
spark.master=spark://localhost:7077
spark.executor.memory=1g
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.kryo.registrator=org.apache.tinkerpop.gremlin.spark.structure.io.gryo.GryoRegistrator
spark.driver.memory=1g
# 为了executor能找到janus相关包
spark.executor.extraClassPath=/home/raini/app/janusgraph/lib/*
编写数据Schema:
janusgraph-schema.groovy
def defineGratefulDeadSchema(janusGraph) {
m = janusGraph.openManagement()
//人信息节点label
person = m.makeVertexLabel("person").make()
//properties
//使用IncrementBulkLoader导入时,去掉下面注释
//blid = m.makePropertyKey("bulkLoader.vertex.id").dataType(Long.class).make()
birth = m.makePropertyKey("birth").dataType(Date.class).make()
age = m.makePropertyKey("age").dataType(Integer.class).make()
name = m.makePropertyKey("name").dataType(String.class).make()
//index
index = m.buildIndex("nameCompositeIndex", Vertex.class).addKey(name).unique().buildCompositeIndex()
//使用IncrementBulkLoader导入时,去掉下面注释
//bidIndex = m.buildIndex("byBulkLoaderVertexId", Vertex.class).addKey(blid).indexOnly(person).buildCompositeIndex()
m.commit()
}
执行Gremlin数据导入语句:
raini@biyuzhe:~/app/janusgraph$ bin/gremlin.sh
(1)
:load /home/raini/pro/GraphDatabase/test/src/main/scala/janusgraph-load/test-janusgraph-schema.groovy
graph = JanusGraphFactory.open('/home/raini/pro/GraphDatabase/test/src/main/scala/janusgraph-load/janusgraph-test.properties')
defineGratefulDeadSchema(graph)
(2)
graph = GraphFactory.open('data/zl/hadoop-graphson.properties')
blvp = BulkLoaderVertexProgram.build().bulkLoader(OneTimeBulkLoader).writeGraph('data/zl/janusgraph-test.properties').create(graph)
graph.compute(SparkGraphComputer).program(blvp).submit().get()
报错:
java.lang.InstantiationException
(3)
graph = JanusGraphFactory.open('data/zl/janusgraph-test.properties')
g = graph.traversal()
g.V().valueMap()
Configuring JanusGraph Server for ConfiguredGraphFactory
(配置JanusGraph的默认图形配置)
配置在:/home/raini/app/janusgraph/conf/gremlin-server/gremlin-server-configuration.yaml
文档说明:https://docs.janusgraph.org/latest/configuredgraphfactory.html
为了能够使用ConfiguredGraphFactory,您必须配置服务器以使用ConfigurationManagementGraphAPI。为此,您必须在服务器的YAML graphs映射中注入名为“ConfigurationManagementGraph”的图形变量。例如:
graphManager: org.janusgraph.graphdb.management.JanusGraphManager
graphs: {
ConfigurationManagementGraph: <--(修改这里文件为默认配置,如后端改为Hbase
conf/JanusGraph-configurationmanagement.properties
}
在此示例中,我们的ConfigurationManagementGraph图形将使用存储在conf/JanusGraph-configurationmanagement.properties其中的属性进行配置 ,例如,如下所示:
gremlin.graph=org.janusgraph.core.JanusGraphFactory
storage.backend=cql
graph.graphname=ConfigurationManagementGraph
storage.hostname=127.0.0.1
PS:(如上几个参数一定为必填项)
JG的3中使用方式
[1] 以嵌入式开发(Java)的方式访问;
[2] 通过Gremlin Console控制台访问;
[3] 通过JanusGraph Server的方式访问;
小测试例子
1.使用JanusGraph Gremlin Console方式
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-berkeleyje-es.properties')
gremlin>graph.io(IoCore.graphson()).readGraph('/home/raini/app/janusgraph/data/tinkerpop-sink-v2d01.json')
gremlin> dennis = graph.addVertex(T.label, "person", "name", "Dennis","city", "Chengdu")
jady = graph.addVertex(T.label, "person", "name", "Jady","city", "Beijing")
dennis.addEdge("knows", jady, "date", "20121201")
或者gremlin> g.addV('person').property('name','Dennis')
执行图遍历:
gremlin> g = graph.traversal()
使用Spark:gremlin> g=graph.traversal().withComputer(SparkGraphComputer)
gremlin> g.V().has('name', 'Dennis').values()
// ==>Dennis
// ==>Chengdu
gremlin> g.V().count()
// ==>2
gremlin> g.V().hasLabel('person')
// ==>v[4296]
// ==>v[4232] <---- lable是节点唯一值
2.使用GraphFactory Gremlin Console方式
graph = GraphFactory.open(...)
g = graph.traversal()
jupiter = g.addV("god").property("name", "jupiter").property("age", 5000).next()
sky = g.addV("location").property("name", "sky").next()
g.V(jupiter).as("a").V(sky).addE("lives").property("reason", "loves fresh breezes").from("a").next()
g.tx().commit()
g.V().has("name", "jupiter").valueMap(true).tryNext()
3.使用Gremlin io 录入GraphSon数据
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-hbase-spark.properties')
gremlin>graph.io(IoCore.graphson()).readGraph('/home/raini/app/janusgraph/data/tinkerpop-sink-v2d01.json')
gremlin> dennis = graph.addVertex(T.label, "person", "name", "Dennis","city", "Chengdu")
jady = graph.addVertex(T.label, "person", "name", "Jady","city", "Beijing")
dennis.addEdge("knows", jady, "date", "20121201")
//g = graph.traversal() 需要在.properties配置使用Spark
g=graph.traversal().withComputer(SparkGraphComputer)
问题:
远程使用
:load ../schema.groovy
时,请注意其中
.cardinality(Cardinality.SINGLE)
的
Cardinality
使用的类:
正确为应为janusgraph中的类:
gremlin> Cardinality.SINGLE
==>SINGLE
gremlin> Cardinality
==>class org.janusgraph.core.Cardinality
而remote的为tinkerpop中的类:
gremlin> :remote connect tinkerpop.server conf/byz-remote.yaml session
==>Configured biyuzhe/127.0.0.1:8182-[2ed42d86-882c-42b6-af31-6ca4fb5ee712]
gremlin> :remote console
==>All scripts will now be sent to Gremlin Server - [biyuzhe/127.0.0.1:8182]-[2ed42d86-882c-42b6-af31-6ca4fb5ee712] - type ':remote console' to return to local mode
gremlin> Cardinality.SINGLE
No such property: SINGLE for class: org.apache.tinkerpop.gremlin.structure.VertexProperty$Cardinality
Type ':help' or ':h' for help.
Display stack trace? [yN]
gremlin> Cardinality
==>class org.apache.tinkerpop.gremlin.structure.VertexProperty$Cardinality
解决:
name = mgmt.makePropertyKey("name").dataType(String.class).cardinality(Cardinality.SINGLE).make()
改为明确类:
.cardinality(org.janusgraph.core.Cardinality.SINGLE)
还有BulkLoader:
gremlin> BulkLoaderVertexProgram
==>class org.apache.tinkerpop.gremlin.process.computer.bulkloading.BulkLoaderVertexProgram














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









