







文章目录
本文翻译整理自:https://docs.llamaindex.ai/en/stable/module_guides/evaluating/
一、Evaluating 概览
概念
评估和基准测试是LLM发展中的关键概念。为了提高 LLM 应用程序(RAG、代理)的性能,您必须有一种方法来衡量它。
LlamaIndex 提供了衡量生成结果质量 和 检索质量 的关键模块。
- 响应评估:响应是否与检索到的上下文匹配?它也与查询匹配吗?它与参考答案或指南相符吗?
- 检索评估:检索到的来源与查询相关吗?
Response 评估
评估生成的结果可能很困难,因为与传统的机器学习不同,预测结果不是单个数字,并且很难定义此问题的定量指标。
LlamaIndex 提供基于LLM的评估模块来衡量结果的质量。
这使用“gold”LLM(例如 GPT-4)以多种方式决定预测答案是否正确。
请注意,许多当前的评估模块不需要真实标签。
可以通过查询、上下文、响应的某种组合来完成评估,并将这些与 LLM 调用结合起来。
这些评估模块有以下形式:
- 正确性 :生成的答案是否与给定查询的参考答案匹配(需要标签)。
- 语义相似度 :预测答案在语义上是否与参考答案相似(需要标签)。
- 忠实性 :评估答案是否忠实于检索到的上下文(换句话说,是否存在幻觉)。
- 上下文相关性 :检索到的上下文是否与查询相关。
- 答案相关性 :生成的答案是否与查询相关。
- 遵循指南 :预测答案是否遵循特定指南。
问题生成
除了评估查询之外,LlamaIndex 还可以使用您的数据 生成要评估的问题。
这意味着您可以 自动生成问题,然后运行评估管道 来测试LLM是否真的可以使用您的数据准确回答问题。
Retrieval Evaluation
我们还提供模块来帮助独立评估检索。
检索评估的概念并不新鲜。
给定问题数据集和真实排名,我们可以使用平均倒数排名(MRR)、命中率、精度等排名指标来评估检索器。
核心检索评估步骤围绕以下内容:
- 数据集生成 :给定非结构化文本语料库,综合生成(问题,上下文)对。
- 检索评估 :给定检索器和一组问题,使用排名指标评估检索结果。
集成
我们还集成了社区评估工具。
- UpTrain
- Tonic Validate(包括用于可视化结果的 Web UI)
- DeepEval
- Ragas
使用模式
有关完整的使用详细信息,请参阅下面的使用模式。
二、使用模式(反应评估)
1、使用BaseEvaluator
LlamaIndex 中的所有评估模块都实现了该类BaseEvaluator,有两个主要方法:
1、该evaluate方法接受query、contexts、response和其他关键字参数。
def evaluate(
self,
query: Optional[str] = None,
contexts: Optional[Sequence[str]] = None,
response: Optional[str] = None,
**kwargs: Any,
) -> EvaluationResult:
2、该evaluate_response方法提供了一个替代接口,它接受 llamaindex Response对象(包含响应字符串和源节点),而不是单独的contexts和response。
def evaluate_response(
self,
query: Optional[str] = None,
response: Optional[Response] = None,
**kwargs: Any,
) -> EvaluationResult:
它在功能上与 相同evaluate,只是在直接使用 llamaindex 对象时使用起来更简单。
2、使用EvaluationResult
每个评估器在执行时输出 EvaluationResult:
eval_result = evaluator.evaluate(query=..., contexts=..., response=...)
eval_result.passing # binary pass/fail
eval_result.score # numerical score
eval_result.feedback # string feedback
不同的评估者可能会填充结果字段的子集。
3、评估响应的可信度(即幻觉)
评估 FaithfulnessEvaluator 答案是否忠实于检索到的上下文(换句话说,是否存在幻觉)。
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import FaithfulnessEvaluator
# create llm
llm = OpenAI(model="gpt-4", temperature=0.0)
# build index
...
# define evaluator
evaluator = FaithfulnessEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
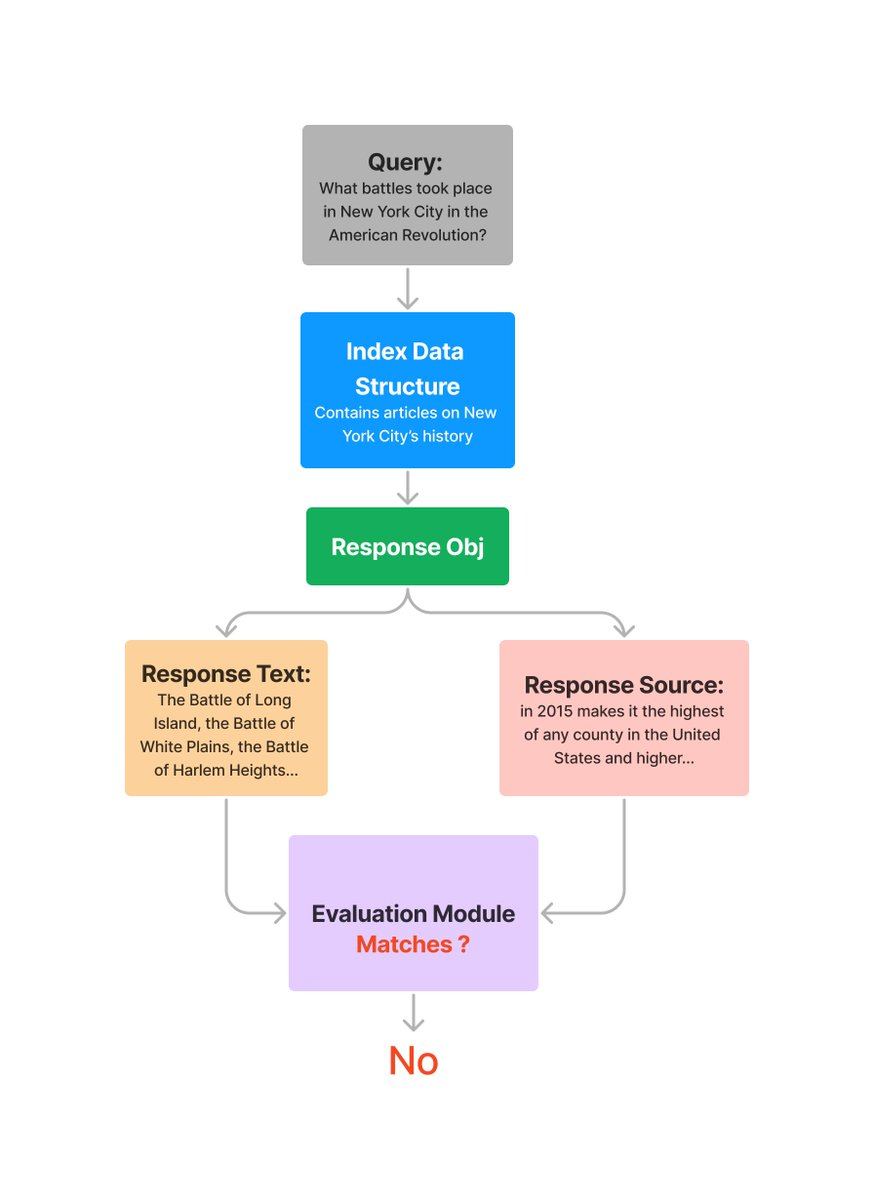
response = query_engine.query(
"What battles took place in New York City in the American Revolution?"
)
eval_result = evaluator.evaluate_response(response=response)
print(str(eval_result.passing))
您还可以选择单独评估每个源上下文:
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import FaithfulnessEvaluator
# create llm
llm = OpenAI(model="gpt-4", temperature=0.0)
# build index
...
# define evaluator
evaluator = FaithfulnessEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
response = query_engine.query(
"What battles took place in New York City in the American Revolution?"
)
response_str = response.response
for source_node in response.source_nodes:
eval_result = evaluator.evaluate(
response=response_str, contexts=[source_node.get_content()]
)
print(str(eval_result.passing))
您将得到一个结果列表,对应于 中的每个源节点response.source_nodes。
4、评估查询 + 响应相关性
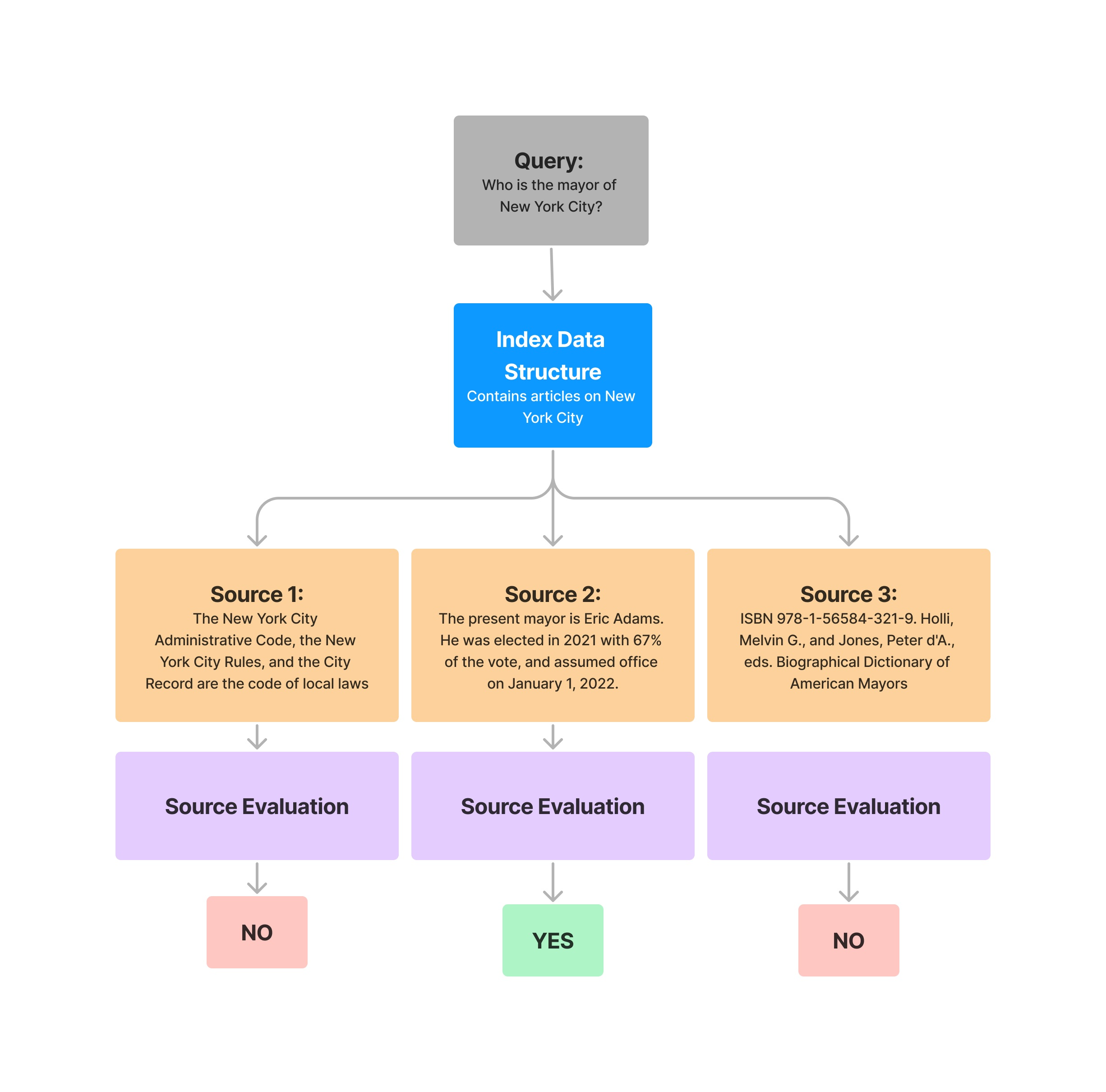
评估 RelevancyEvaluator 检索到的上下文 和 答案对于给定查询是否相关且一致。
请注意,除了对象之外,该求值器还需要query传入Response。
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import RelevancyEvaluator
# create llm
llm = OpenAI(model="gpt-4", temperature=0.0)
# build index
...
# define evaluator
evaluator = RelevancyEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
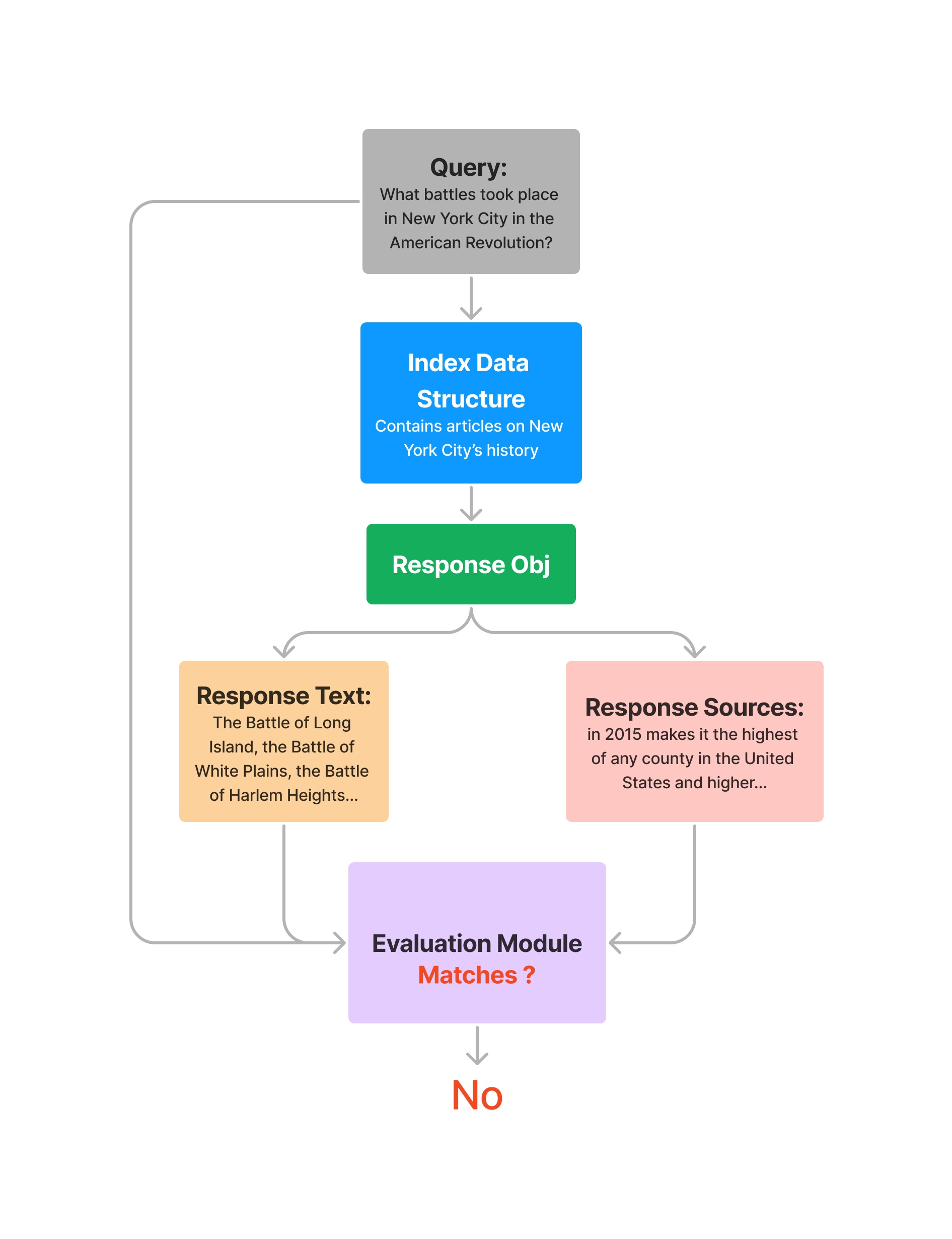
query = "What battles took place in New York City in the American Revolution?"
response = query_engine.query(query)
eval_result = evaluator.evaluate_response(query=query, response=response)
print(str(eval_result))
同样,您也可以在特定源节点上进行评估。
from llama_index.core import VectorStoreIndex
from llama_index.llms.openai import OpenAI
from llama_index.core.evaluation import RelevancyEvaluator
# create llm
llm = OpenAI(model="gpt-4", temperature=0.0)
# build index
...
# define evaluator
evaluator = RelevancyEvaluator(llm=llm)
# query index
query_engine = vector_index.as_query_engine()
query = "What battles took place in New York City in the American Revolution?"
response = query_engine.query(query)
response_str = response.response
for source_node in response.source_nodes:
eval_result = evaluator.evaluate(
query=query,
response=response_str,
contexts=[source_node.get_content()],
)
print(str(eval_result.passing))
5、问题生成
LlamaIndex 还可以使用您的数据生成问题来回答。
与上述评估器结合使用,您可以对数据创建完全自动化的评估管道。
from llama_index.core import SimpleDirectoryReader
from llama_index.llms.openai import OpenAI
from llama_index.core.llama_dataset.generator import RagDatasetGenerator
# create llm
llm = OpenAI(model="gpt-4", temperature=0.0)
# build documents
documents = SimpleDirectoryReader("./data").load_data()
# define generator, generate questions
dataset_generator = RagDatasetGenerator.from_documents(
documents=documents,
llm=llm,
num_questions_per_chunk=10, # set the number of questions per nodes
)
rag_dataset = dataset_generator.generate_questions_from_nodes()
questions = [e.query for e in rag_dataset.examples]
6、批量评估
我们还提供了一个批量评估运行程序,用于针对许多问题运行一组评估程序。
from llama_index.core.evaluation import BatchEvalRunner
runner = BatchEvalRunner(
{"faithfulness": faithfulness_evaluator, "relevancy": relevancy_evaluator},
workers=8,
)
eval_results = await runner.aevaluate_queries(
vector_index.as_query_engine(), queries=questions
)
7、集成
我们还集成了社区评估工具。
深度评估 (使用DeepEval)
DeepEval提供 6 个评估器(包括 3 个 RAG 评估器,用于检索器和生成器评估),由其专有的评估指标提供支持。
安装deepeval:
pip install -U deepeval
然后,您可以从 导入并使用评估器deepeval。
完整示例:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
from deepeval.integrations.llama_index import DeepEvalAnswerRelevancyEvaluator
documents = SimpleDirectoryReader("YOUR_DATA_DIRECTORY").load_data()
index = VectorStoreIndex.from_documents(documents)
rag_application = index.as_query_engine()
# An example input to your RAG application
user_input = "What is LlamaIndex?"
# LlamaIndex returns a response object that contains
# both the output string and retrieved nodes
response_object = rag_application.query(user_input)
evaluator = DeepEvalAnswerRelevancyEvaluator()
evaluation_result = evaluator.evaluate_response(
query=user_input, response=response_object
)
print(evaluation_result)
您可以通过以下方式导入全部 6 个评估器deepeval:
from deepeval.integrations.llama_index import (
DeepEvalAnswerRelevancyEvaluator,
DeepEvalFaithfulnessEvaluator,
DeepEvalContextualRelevancyEvaluator,
DeepEvalSummarizationEvaluator,
DeepEvalBiasEvaluator,
DeepEvalToxicityEvaluator,
)
要详细了解如何将deepeval的评估指标与 LlamaIndex 结合使用并利用其完整的 LLM 测试套件,请访问文档。
三、使用模式(检索)
1、使用RetrieverEvaluator
这对给定检索器的单个查询+真实文档集进行评估。
标准做法是使用 指定一组有效的指标from_metrics。
from llama_index.core.evaluation import RetrieverEvaluator
# define retriever somewhere (e.g. from index)
# retriever = index.as_retriever(similarity_top_k=2)
retriever = ...
retriever_evaluator = RetrieverEvaluator.from_metric_names(
["mrr", "hit_rate"], retriever=retriever
)
retriever_evaluator.evaluate(
query="query", expected_ids=["node_id1", "node_id2"]
)
2、构建评估数据集
您可以手动策划问题 + 节点 ID 的检索评估数据集。
我们还使用我们的generate_question_context_pairs函数 在现有文本语料库上 提供合成数据集生成 :
from llama_index.core.evaluation import generate_question_context_pairs
qa_dataset = generate_question_context_pairs(
nodes, llm=llm, num_questions_per_chunk=2
)
返回的结果是一个 EmbeddingQAFinetuneDataset对象(包含queries、relevant_docs 和corpus)。
将其插入RetrieverEvaluator
我们提供了一个方便的函数来以RetrieverEvaluator批处理模式 运行数据集。
eval_results = await retriever_evaluator.aevaluate_dataset(qa_dataset)
这应该比您尝试单独在每个查询调用 .evaluate 运行得快得多。
四、模块
下面可以找到使用这些组件的笔记本。
Response Evaluation
- Faithfulness
- Relevancy
- Answer and Context Relevancy
- Deepeval Integration
- Guideline Eval
- Correctness Eval
- Semantic Eval
- Question Generation
- Batch Eval
- Multi-Modal RAG eval
- Uptrain Integration
Retrieval Evaluation
五、贡献 LabelledRagDataset
构建更强大的 RAG 系统需要多样化的评估套件。这就是我们在 llama-hub 推出LlamaDatasets 的原因。
在本页中,我们讨论如何在 llama-hub 中贡献第一种 LlamaDataset ,即LabelledRagDataset 。
贡献 LabelledRagDataset涉及两个高级步骤。
一般来说,您必须创建LabelledRagDataset、将其保存为 json 并将该 json 文件和源文本文件提交到我们的llama-datasets 存储库。
此外,您必须发出拉取请求,将数据集所需的元数据上传到我们的llama-hub 存储库。
为了使提交过程更加顺利,我们准备了一个模板笔记本,您可以按照它LabelledRagDataset从头开始创建一个(或将类似结构的问答数据集转换为一个)并执行其他所需的步骤来提交。
请参阅下面链接的“LlamaDataset 提交模板笔记本”。
贡献其他 llama 数据集
贡献我们的任何其他 llama 数据集(例如 LabelledEvaluatorDataset )的一般过程 与 前面描述的LabelledRagDataset相同。
这些其他数据集的提交模板将在后续推出。
提交示例
见:https://docs.llamaindex.ai/en/stable/examples/llama_dataset/ragdataset_submission_template/
六、使用 LabelledRagDataset 评估
1、概述
我们已经了解了评估模块中的核心抽象,该模块支持基于 LLM 的应用程序或系统(包括 RAG 系统)的各种评估方法。
当然,评估系统需要评估方法、系统本身以及评估数据集。
在来自不同来源和领域的几个不同数据集上测试 LLM 应用程序被认为是最佳实践。
这样做有助于确保系统的整体稳健性(即系统在未见过的新情况下工作的水平)。
为此,我们已将LabelledRagDataset抽象包含在我们的库中。
它们的核心目的是通过使系统 易于创建、易于使用和广泛可用,促进对各种数据集的系统评估。
该数据集由示例组成,其中示例带有 一个 query、 一个 reference_answer以及reference_contexts。
使用 的主要原因LabelledRagDataset是通过首先预测对给定的响应query,然后将预测(或生成)的响应与 reference_answer 进行比较来测试 RAG 系统的性能。
from llama_index.core.llama_dataset import (
LabelledRagDataset,
CreatedBy,
CreatedByType,
LabelledRagDataExample,
)
example1 = LabelledRagDataExample(
query="This is some user query.",
query_by=CreatedBy(type=CreatedByType.HUMAN),
reference_answer="This is a reference answer. Otherwise known as ground-truth answer.",
reference_contexts=[
"This is a list",
"of contexts used to",
"generate the reference_answer",
],
reference_by=CreatedBy(type=CreatedByType.HUMAN),
)
# a sad dataset consisting of one measely example
rag_dataset = LabelledRagDataset(examples=[example1])
2、构建一个 LabelledRagDataset
正如我们在上一节末尾看到的,我们可以通过逐个LabelledRagDataset 构建 来手动构建 LabelledRagDataExample。
然而,这有点乏味,虽然人工注释的数据集非常有价值,但由强大的LLM生成的数据集也非常有用。
因此,该llama_dataset模块配备了RagDatasetGenerator能够生成LabelledRagDataset多个源Document的。
from llama_index.core.llama_dataset.generator import RagDatasetGenerator
from llama_index.llms.openai import OpenAI
import nest_asyncio
nest_asyncio.apply()
documents = ... # a set of documents loaded by using for example a Reader
llm = OpenAI(model="gpt-4")
dataset_generator = RagDatasetGenerator.from_documents(
documents=documents,
llm=llm,
num_questions_per_chunk=10, # set the number of questions per nodes
)
rag_dataset = dataset_generator.generate_dataset_from_nodes()
3、使用一个LabelledRagDataset
如前所述,我们希望使用LabelledRagDatasetRAG 系统来评估基于相同源的 RAG 系统的Document性能。
这样做需要执行两个步骤:(1) 对数据集进行预测(即生成对每个单独示例的查询的响应),以及 (2) 通过将预测响应与参考答案进行比较来评估预测响应。
在步骤(2)中,我们还评估 RAG 系统的检索上下文并将其与参考上下文进行比较,以获得对 RAG 系统的检索组件的评估。
为了方便起见,我们有一个LlamaPack称为RagEvaluatorPack简化此评估过程的工具!
from llama_index.core.llama_pack import download_llama_pack
RagEvaluatorPack = download_llama_pack("RagEvaluatorPack", "./pack")
rag_evaluator = RagEvaluatorPack(
query_engine=query_engine, # built with the same source Documents as the rag_dataset
rag_dataset=rag_dataset,
)
benchmark_df = await rag_evaluator.run()
上面benchmark_df包含之前介绍的评估措施的平均分数:Correctness、Relevancy,Faithfulness以及Context Similarity 测量参考上下文以及 RAG 系统检索的上下文之间的语义相似性以生成预测响应。
4、哪里可以找到 LabelledRagDataset
可以在 llamahub中找到所有LabelledRagDataset内容。
您可以浏览其中的每一个,并决定是否决定使用它来对 RAG 管道进行基准测试,然后您可以通过以下两种方式之一方便地下载数据集以及源:使用实用函数的 Python 代码 。
# using cli
llamaindex-cli download-llamadataset PaulGrahamEssayDataset --download-dir ./data
# using python
from llama_index.core.llama_dataset import download_llama_dataset
# a LabelledRagDataset and a list of source Document's
rag_dataset, documents = download_llama_dataset(
"PaulGrahamEssayDataset", "./data"
)
贡献者ALabelledRagDataset
您还可以LabelledRagDataset向llamahub贡献一份力量。
贡献 aLabelledRagDataset涉及两个高级步骤。
一般来说,您必须创建LabelledRagDataset,将其保存为 json 并将该 json 文件和源文本文件提交到我们的llama_datasets Github 存储库。
此外,您还必须发出拉取请求,将数据集所需的元数据上传到我们的llama_hub Github 存储库。
请参阅下面链接的“LlamaDataset 提交模板笔记本”。
5、现在,开始构建强大的 LLM 应用程序
LlamaDataset希望本页面能够成为您创建、下载和使用构建强大且高性能的 LLM 应用程序的良好起点。
要了解更多信息,我们建议阅读下面提供的笔记本指南。
资源
七、使用LabelledEvaluatorDataset 评估Evaluators
llama 数据集的目的是为构建者提供快速对 LLM 系统或任务进行基准测试的方法。
本着这种精神,它的LabelledEvaluatorDataset存在是为了促进评估者以无缝且轻松的方式进行评估。
该数据集由主要带有以下属性的示例组成: query、answer、ground_truth_answer、reference_score以及reference_feedback一些其他补充属性。
使用该数据集进行评估的用户流程包括使用提供的 LLM 评估器对数据集进行预测,然后通过计算将评估与相应的参考进行比较来计算衡量评估优劣的指标。
EvaluatorBenchmarkerPack下面是利用来方便地处理上述流程的代码片段。
from llama_index.core.llama_dataset import download_llama_dataset
from llama_index.core.llama_pack import download_llama_pack
from llama_index.core.evaluation import CorrectnessEvaluator
from llama_index.llms.gemini import Gemini
# download dataset
evaluator_dataset, _ = download_llama_dataset(
"MiniMtBenchSingleGradingDataset", "./mini_mt_bench_data"
)
# define evaluator
gemini_pro_llm = Gemini(model="models/gemini-pro", temperature=0)
evaluator = CorrectnessEvaluator(llm=gemini_pro_llm)
# download EvaluatorBenchmarkerPack and define the benchmarker
EvaluatorBenchmarkerPack = download_llama_pack(
"EvaluatorBenchmarkerPack", "./pack"
)
evaluator_benchmarker = EvaluatorBenchmarkerPack(
evaluator=evaluators["gpt-3.5"],
eval_dataset=evaluator_dataset,
show_progress=True,
)
# produce the benchmark result
benchmark_df = await evaluator_benchmarker.arun(
batch_size=5, sleep_time_in_seconds=0.5
)
相关的LabelledPairwiseEvaluatorDataset
一个相关的 llama 数据集是LabelledPairwiseEvaluatorDataset,它同样是为了评估评估者,但这次评估者的任务是将一对 LLM 响应与给定的查询进行比较,并确定其中更好的一个。
上述使用流程与 的使用流程完全相同 LabelledEvaluatorDataset,不同之处在于必须配备 LLM 评估器来执行成对评估任务 - 即应该是PairwiseComparisonEvaluator.
更多学习资料
要查看这些数据集的实际应用,请务必查看下面列出的笔记本,这些笔记本是在稍微修改的 MT-Bench 数据集版本上对 LLM 评估者进行基准测试的。
2024-04-16(二)
















 196
196











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











