







文章目录
- 一、关于 PantoMatrix
- 二、快速入门(推理)
- 三、可视化
- 四、评估
- 五、训练
- 六、参考文献
- 1、EMAGE:Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling (CVPR 2024)
- 2、BEAT:A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis (ECCV 2022)
- 3、DisCo:Disentangled Implicit Content and Rhythm Learning for Diverse Co-Speech Gesture Synthesis (ACMMM 2022)
一、关于 PantoMatrix
PantoMatrix 是一个开源和研究项目,用于从语音中生成3D身体和面部动画。
它作为API输入语音音频并输出身体和面部运动参数。您可以将这些运动参数转换为其他格式,如Iphone ARKit Blendshape Weights或Vicon Skeleton bvh文件。
- github : https://github.com/PantoMatrix/PantoMatrix
- EMAGE 主页:https://pantomatrix.github.io/EMAGE/
- 视频介绍:https://www.youtube.com/watch?v=T0OYPvViFGE
- replicate : https://replicate.com/camenduru/emage
- colab : https://colab.research.google.com/drive/1bB3LqAzceNTW2urXeMpOTPoJYTRoKlzB?usp=sharing
- huggingface : https://huggingface.co/spaces/H-Liu1997/EMAGE
- BEAT 主页:https://pantomatrix.github.io/BEAT/
- DisCo 主页:https://pantomatrix.github.io/DisCo/
新闻
欢迎志愿者就相关主题进行贡献和协作。请随时提交拉取请求!目前此repo主要由 haiyangliu1997@gmail.com自2022年以来免费维护。
- [2025/01]新的推理api,可视化api,评估api,训练代码库,可用!
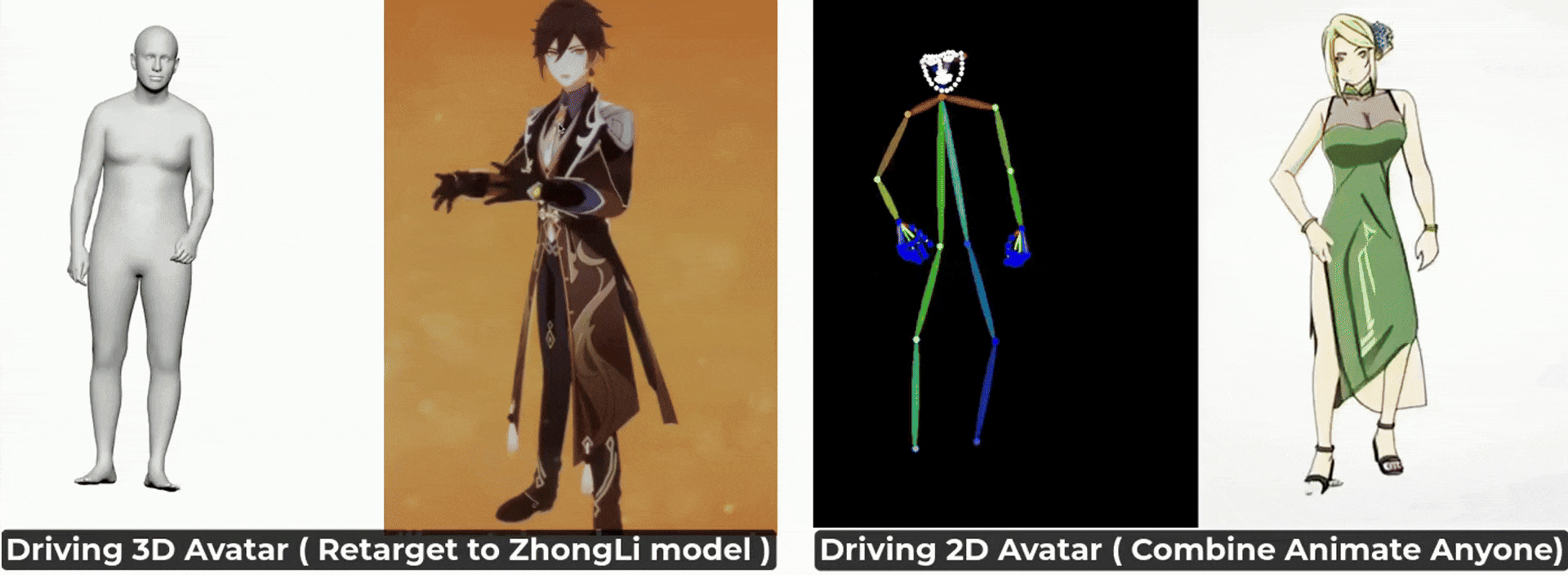
- [2024/07] 下载smplx运动(在. npz)文件,用我们的搅拌机插件可视化并重新定位到您的头像!
- **[2024/04]**感谢@camne u,提供复制版EMAGE!您可以通过API直接调用EMAGE!
- **[2024/03]**感谢@sunday9999将推理视频渲染从1000s加速到25s!
- **[2024/02]**感谢@wuBowen416在推理过程中自动视频可视化#83的脚本!
- [2023/05] BEAT_GENEA在GENEA2023中允许进行预训练!感谢GENEA的组织者!
模型和工具列表
| Model | Paper | Inputs | Outputs** | Language (Train) | Full Body FGD | Weights |
|---|---|---|---|---|---|---|
| DisCo | ACMMM 2022 | Audio | Upper + Hands | English (Speaker 2) | 2.233 | Link |
| CaMN | ECCV 2022 | Audio | Upper + Hands | English (Speaker 2) | 2.120 | Link |
| EMAGE | CVPR 2024 | Audio | Full Body + Face | English (Speaker 2) | 0.615 | Link |
输出采用SMPLX和FLAME参数。
二、快速入门(推理)
方式一:使用Hugging Face Space
上传您的音频并直接从我们的Hugging Face 空间下载结果。
方式2:本地设置
克隆存储库并在本地设置。
git clone https://github.com/PantoMatrix/PantoMatrix.git
cd PantoMatrix/
bash setup.sh
source /content/py39/bin/activate
python test_camn_audio.py --visualization
# if you have trouble in install pytroch3d
# use --nopytorch3d, this will not render the 2D openpose style video
python test_camn_audio.py --visualization --nopytorch3d
# try differnet models with your data, put your audio in --audio_folder
# DisCo (ACMMM2022), upper body motion, with data resampling and rhythm content disentanglement.
python test_disco_audio.py --visualization --audio_folder ./examples/audio --save_folder ./examples/motion
# BEAT (ECCV2022), upper body motion, with body2hands decoder
python test_camn_audio.py --visualization --audio_folder ./examples/audio --save_folder ./examples/motion
# EMAGE (CVPR2024), full body + face animation
python test_emage_audio.py --visualization --audio_folder ./examples/audio --save_folder ./examples/motion
方式3:直接调用API
# copy the ./models folder iin your project folder
from .model.camn_audio import CaMNAudioModel
model = CaMNAudioModel.from_pretrained("H-Liu1997/huggingface-model/camn_audio")
model.cuda().eval()
import librosa
import numpy as np
import torch
# copy the ./emage_utils folder in your project folder
from emage_utils import beat_format_save
audio_np, sr = librosa.load("/audio_path.wav", sr=model.cfg.audio_sr)
audio = torch.from_numpy(audio_np).float().cuda().unsqueeze(0)
motion_pred = model(audio)["motion_axis_angle"]
motion_pred_np = motion_pred.cpu().numpy()
beat_format_save(motion_pred_np, "/result_motion.npz")
三、可视化
当您运行测试脚本时,有一个参数--visualization来自动启用可视化。
此外,您还可以通过以下方式尝试可视化。
方式一:搅拌机(推荐)
使用Blender渲染输出通过下载搅拌机插件
方式二:3D网格
# render a npz file to a mesh video
from emage_utils import fast_render
fast_render.render_one_sequence_no_gt("/result_motion.npz", "/audio_path.wav", "/result_video.mp4", remove_global=True)
| 迪斯科(网格) | CaMN(网格) | EMAGE(网格) |
|---|---|---|
 视频示例 |
方式三、2D OpenPose风格视频(需要Pytorch3D)
from trochvision.io import write_video
from emage_utils.format_transfer import render2d
from emage_utils import fast_render
motion_dict = np.load(npz_path, allow_pickle=True)
# face
v2d_face = render2d(motion_dict, (512, 512), face_only=True, remove_global=True)
write_video(npz_path.replace(".npz", "_2dface.mp4"), v2d_face.permute(0, 2, 3, 1), fps=30)
fast_render.add_audio_to_video(npz_path.replace(".npz", "_2dface.mp4"), audio_path, npz_path.replace(".npz", "_2dface_audio.mp4"))
# body
v2d_body = render2d(motion_dict, (720, 480), face_only=False, remove_global=True)
write_video(npz_path.replace(".npz", "_2dbody.mp4"), v2d_body.permute(0, 2, 3, 1), fps=30)
fast_render.add_audio_to_video(npz_path.replace(".npz", "_2dbody.mp4"), audio_path, npz_path.replace(".npz", "_2dbody_audio.mp4"))
| 迪斯科(2D姿势) | CaMN(2D姿势) | EMAGE(2D姿势) | EMAGE-Face(2D姿势) |
|---|---|---|---|
 |  | 视频示例 |  |
四、评估
对于学术用户,评估代码被组织成评估API。
# copy the ./emage_evaltools folder into your folder
from emage_evaltools.metric import FGD, BC, L1Div, LVDFace, MSEFace
# init
fgd_evaluator = FGD(download_path="./emage_evaltools/")
bc_evaluator = BC(download_path="./emage_evaltools/", sigma=0.3, order=7)
l1div_evaluator= L1div()
lvd_evaluator = LVDFace()
mse_evaluator = MSEFace()
# Example usage
for motion_pred in all_motion_pred:
# bc and l1 require position representation
motion_position_pred = get_motion_rep_numpy(motion_pred, device=device, betas=betas)["position"] # t*55*3
motion_position_pred = motion_position_pred.reshape(t, -1)
# ignore the start and end 2s, this may for beat dataset only
audio_beat = bc_evaluator.load_audio(test_file["audio_path"], t_start=2 * 16000, t_end=int((t-60)/30*16000))
motion_beat = bc_evaluator.load_motion(motion_position_pred, t_start=60, t_end=t-60, pose_fps=30, without_file=True)
bc_evaluator.compute(audio_beat, motion_beat, length=t-120, pose_fps=30)
l1_evaluator.compute(motion_position_pred)
face_position_pred = get_motion_rep_numpy(motion_pred, device=device, expressions=expressions_pred, expression_only=True, betas=betas)["vertices"] # t -1
face_position_gt = get_motion_rep_numpy(motion_gt, device=device, expressions=expressions_gt, expression_only=True, betas=betas)["vertices"]
lvd_evaluator.compute(face_position_pred, face_position_gt)
mse_evaluator.compute(face_position_pred, face_position_gt)
# fgd requires rotation 6d representaiton
motion_gt = torch.from_numpy(motion_gt).to(device).unsqueeze(0)
motion_pred = torch.from_numpy(motion_pred).to(device).unsqueeze(0)
motion_gt = rc.axis_angle_to_rotation_6d(motion_gt.reshape(1, t, 55, 3)).reshape(1, t, 55*6)
motion_pred = rc.axis_angle_to_rotation_6d(motion_pred.reshape(1, t, 55, 3)).reshape(1, t, 55*6)
fgd_evaluator.update(motion_pred.float(), motion_gt.float())
metrics = {}
metrics["fgd"] = fgd_evaluator.compute()
metrics["bc"] = bc_evaluator.avg()
metrics["l1"] = l1_evaluator.avg()
metrics["lvd"] = lvd_evaluator.avg()
metrics["mse"] = mse_evaluator.avg()
超参数可能因数据集而异。
例如,对于BEAT数据集,我们使用(0.3, 7);对于TalkShow数据集,我们使用(0.5, 7)。您可以根据您的数据进行调整。
五、训练
这个新的代码库只有纯音频版本模型,用于更好的实际应用。
要在论文中再现音频+文本结果,请检查并参考下面以前的代码库。
| Model | Inputs (Paper) | Old Codebase | Input (Current Codebase) |
|---|---|---|---|
| DisCo | Audio + Text | link | Audio |
| CaMN | Audio + Text + Emotion + Facial | link | Audio |
| EMAGE | Audio + Text | link | Audio |
开始前
环境设置,如果您已经设置了推理,请跳过。
# if you didn't run test, run the below four commands.
# git clone https://github.com/PantoMatrix/PantoMatrix.git
# cd PantoMatrix/
# bash setup.sh
# source /content/py39/bin/activate
# Download the BEAT2
sudo apt-get update
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/datasets/H-Liu1997/BEAT2
您的文件夹应该遵循正确的路径
/your_root/
|-- PantoMatrix
|-- BEAT2
`-- train_emage_audio.py
方式1:训练EMAGE
# Preprocessing Extract the foot contact data
python ./datasets/foot_contact.py
# (todo) train the vqvae
# train the audio2motion model
torchrun --nproc_per_node 1 --nnodes 1 train_emage_audio.py --config ./configs/emage_audio.yaml --evaluation
根据需要使用这些标志:
--evaluation:计算测试度量。--wandb:激活对WandB的日志记录。--visualization:渲染测试结果(慢;禁用效率)。--test:测试模式;加载最后一个检查点并评估。--debug:调试模式;迭代一个数据点以进行快速测试。
方式2:训练 CaMN
torchrun --nproc_per_node 1 --nnodes 1 train_camn_audio.py --config ./configs/camn_audio.yaml --evaluation
方式3:训练 DisCo
# (optional) Extract the cluster information
# python ./datasets/clustering.py
# train audio2motion
torchrun --nproc_per_node 1 --nnodes 1 train_disco_audio.py --config ./configs/disco_audio.yaml --evaluation
六、参考文献
1、EMAGE:Towards Unified Holistic Co-Speech Gesture Generation via Expressive Masked Audio Gesture Modeling (CVPR 2024)
通过表达式掩蔽音频手势建模实现统一的整体协同语音手势生成(CVPR 2024)
- Project Page - Paper - Video - Code - Demo - Dataset - Blender Add-On -
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Naoya Iwamoto, Bo Zheng, Michael J. Black


2、BEAT:A Large-Scale Semantic and Emotional Multi-Modal Dataset for Conversational Gestures Synthesis (ECCV 2022)
用于会话手势合成的大规模语义和情感多模态数据集(ECCV 2022)
- Project Page - Paper - Video - Code - Colab Demo - Dataset - Benchmark -
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, Bo Zheng

-项目页面-论文-视频-代码-Colab演示-数据集-基准测试-

3、DisCo:Disentangled Implicit Content and Rhythm Learning for Diverse Co-Speech Gesture Synthesis (ACMMM 2022)
用于多种共语音手势合成的解构隐式内容和节奏学习(ACMMM 2022)
- Project Page - Paper - Video - Code -
Haiyang Liu, Naoya Iwamoto, Zihao Zhu, Zhengqing Li, You Zhou, Elif Bozkurt, Bo Zheng


2025-01-07(二)



















 1605
1605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











