






文章目录
- 一、关于 SoftVC VITS Singing Voice Conversion
- 二、📝 模型简介
- 三、📥 预先下载的模型文件
- 四、📊 数据集准备
- 五、🛠️ 数据预处理
- 六、🏋️ 训练
- 七、🤖 推理
- 八、🤔 可选项
- 九、🗜️ 模型压缩
- 十、👨🔧 声线混合
- 十一、📤 Onnx 导出
- 十二、📎 引用及论文
- 📚 一些法律条例参考
- 任何国家,地区,组织和个人使用此项目必须遵守以下法律
- 《民法典》
- 《[中华人民共和国宪法](http://www.gov.cn/guoqing/2018-03/22/content_5276318.htm)》
- 《[中华人民共和国刑法](http://gongbao.court.gov.cn/Details/f8e30d0689b23f57bfc782d21035c3.html?sw=中华人民共和国刑法)》
- 《[中华人民共和国民法典](http://gongbao.court.gov.cn/Details/51eb6750b8361f79be8f90d09bc202.html)》
- 《[中华人民共和国合同法](http://www.npc.gov.cn/zgrdw/npc/lfzt/rlyw/2016-07/01/content_1992739.htm)》
一、关于 SoftVC VITS Singing Voice Conversion
- ✨ 带有 F0 曲线编辑器,角色混合时间轴编辑器的推理端 (Onnx 模型的用途): MoeVoiceStudio
- ✨ 改善了交互的一个分支推荐: 34j/so-vits-svc-fork
- ✨ 支持实时转换的一个客户端: w-okada/voice-changer
本项目与 Vits 有着根本上的不同。Vits 是 TTS,本项目是 SVC。本项目无法实现 TTS,Vits 也无法实现 SVC,这两个项目的模型是完全不通用的。
重要通知
这个项目是为了让开发者最喜欢的动画角色唱歌而开发的,任何涉及真人的东西都与开发者的意图背道而驰。
声明
本项目为开源、离线的项目,SvcDevelopTeam 的所有成员与本项目的所有开发者以及维护者(以下简称贡献者)对本项目没有控制力。本项目的贡献者从未向任何组织或个人提供包括但不限于数据集提取、数据集加工、算力支持、训练支持、推理等一切形式的帮助;本项目的贡献者不知晓也无法知晓使用者使用该项目的用途。故一切基于本项目训练的 AI 模型和合成的音频都与本项目贡献者无关。一切由此造成的问题由使用者自行承担。
此项目完全离线运行,不能收集任何用户信息或获取用户输入数据。因此,这个项目的贡献者不知道所有的用户输入和模型,因此不负责任何用户输入。
本项目只是一个框架项目,本身并没有语音合成的功能,所有的功能都需要用户自己训练模型。同时,这个项目没有任何模型,任何二次分发的项目都与这个项目的贡献者无关。
📏 使用规约
Warning:请自行解决数据集授权问题,禁止使用非授权数据集进行训练!任何由于使用非授权数据集进行训练造成的问题,需自行承担全部责任和后果!与仓库、仓库维护者、svc develop team 无关!
- 本项目是基于学术交流目的建立,仅供交流与学习使用,并非为生产环境准备。
- 任何发布到视频平台的基于 sovits 制作的视频,都必须要在简介明确指明用于变声器转换的输入源歌声、音频,例如:使用他人发布的视频 / 音频,通过分离的人声作为输入源进行转换的,必须要给出明确的原视频、音乐链接;若使用是自己的人声,或是使用其他歌声合成引擎合成的声音作为输入源进行转换的,也必须在简介加以说明。
- 由输入源造成的侵权问题需自行承担全部责任和一切后果。使用其他商用歌声合成软件作为输入源时,请确保遵守该软件的使用条例,注意,许多歌声合成引擎使用条例中明确指明不可用于输入源进行转换!
- 禁止使用该项目从事违法行为与宗教、政治等活动,该项目维护者坚决抵制上述行为,不同意此条则禁止使用该项目。
- 继续使用视为已同意本仓库 README 所述相关条例,本仓库 README 已进行劝导义务,不对后续可能存在问题负责。
- 如果将此项目用于任何其他企划,请提前联系并告知本仓库作者,十分感谢。
二、📝 模型简介
歌声音色转换模型,通过 SoftVC 内容编码器提取源音频语音特征,与 F0 同时输入 VITS 替换原本的文本输入达到歌声转换的效果。同时,更换声码器为 NSF HiFiGAN 解决断音问题。
🆕 4.1-Stable 版本更新内容
- 特征输入更换为 Content Vec 的第 12 层 Transformer 输出,并兼容 4.0 分支
- 更新浅层扩散,可以使用浅层扩散模型提升音质
- 增加 whisper 语音编码器的支持
- 增加静态/动态声线融合
- 增加响度嵌入
- 增加特征检索,来自于 RVC
🆕 关于兼容 4.0 模型的问题
- 可通过修改 4.0 模型的 config.json 对 4.0 的模型进行支持,需要在 config.json 的 model 字段中添加 speech_encoder 字段,具体见下
"model": {
.........
"ssl_dim": 256,
"n_speakers": 200,
"speech_encoder":"vec256l9"
}
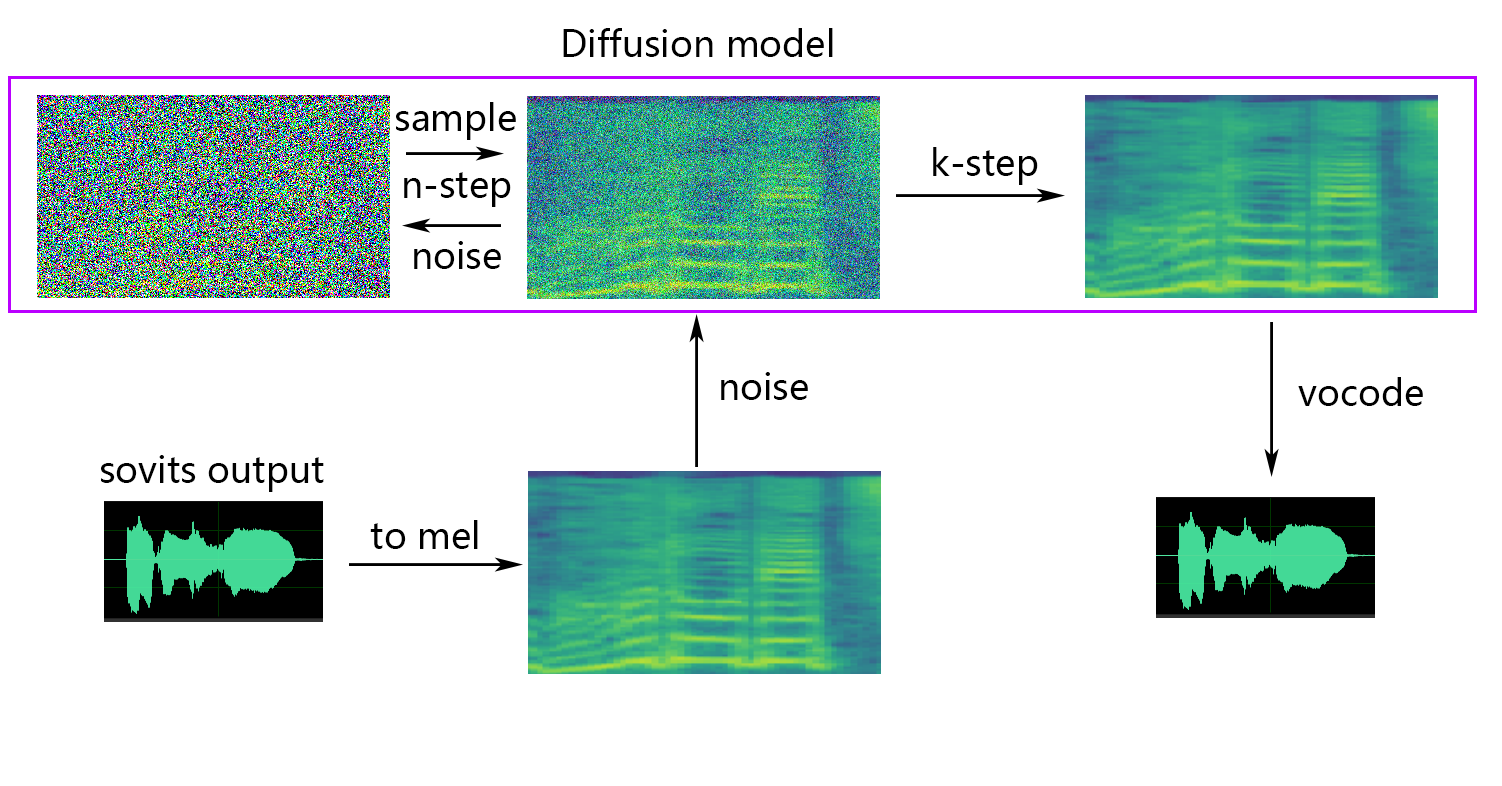
🆕 关于浅扩散
💬 关于 Python 版本问题
在进行测试后,我们认为Python 3.8.9能够稳定地运行该项目
三、📥 预先下载的模型文件
必须项
以下编码器需要选择一个使用
1. 若使用 contentvec 作为声音编码器(推荐)
vec768l12与vec256l9 需要该编码器
-
contentvec :checkpoint_best_legacy_500.pt
- 放在
pretrain目录下
- 放在
或者下载下面的 ContentVec,大小只有 199MB,但效果相同:
-
contentvec :hubert_base.pt
- 将文件名改为
checkpoint_best_legacy_500.pt后,放在pretrain目录下
- 将文件名改为
# contentvec
wget -P pretrain/ https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/hubert_base.pt -O checkpoint_best_legacy_500.pt
# 也可手动下载放在 pretrain 目录
2. 若使用 hubertsoft 作为声音编码器
-
soft vc hubert:hubert-soft-0d54a1f4.pt
- 放在
pretrain目录下
- 放在
3. 若使用 Whisper-ppg 作为声音编码器
-
下载模型 medium.pt, 该模型适配
whisper-ppg -
下载模型 large-v2.pt, 该模型适配
whisper-ppg-large- 放在
pretrain目录下
- 放在
4. 若使用 cnhubertlarge 作为声音编码器
-
下载模型 chinese-hubert-large-fairseq-ckpt.pt
- 放在
pretrain目录下
- 放在
5. 若使用 dphubert 作为声音编码器
-
下载模型 DPHuBERT-sp0.75.pth
- 放在
pretrain目录下
- 放在
6. 若使用 WavLM 作为声音编码器
-
下载模型 WavLM-Base+.pt, 该模型适配
wavlmbase+- 放在
pretrain目录下
- 放在
7. 若使用 OnnxHubert/ContentVec 作为声音编码器
-
下载模型 MoeSS-SUBModel
- 放在
pretrain目录下
- 放在
编码器列表
- “vec768l12”
- “vec256l9”
- “vec256l9-onnx”
- “vec256l12-onnx”
- “vec768l9-onnx”
- “vec768l12-onnx”
- “hubertsoft-onnx”
- “hubertsoft”
- “whisper-ppg”
- “cnhubertlarge”
- “dphubert”
- “whisper-ppg-large”
- “wavlmbase+”
可选项(强烈建议使用)
- 预训练底模文件:
G_0.pthD_0.pth- 放在
logs/44k目录下
- 放在
- 扩散模型预训练底模文件:
model_0.pt- 放在
logs/44k/diffusion目录下
- 放在
从 svc-develop-team(待定)或任何其他地方获取 Sovits 底模
扩散模型引用了 Diffusion-SVC 的 Diffusion Model,底模与 Diffusion-SVC 的扩散模型底模通用,可以去 Diffusion-SVC 获取扩散模型的底模
虽然底模一般不会引起什么版权问题,但还是请注意一下,比如事先询问作者,又或者作者在模型描述中明确写明了可行的用途
可选项(根据情况选择)
NSF-HIFIGAN
如果使用NSF-HIFIGAN 增强器或浅层扩散的话,需要下载预训练的 NSF-HIFIGAN 模型,如果不需要可以不下载
-
预训练的 NSF-HIFIGAN 声码器 :nsf_hifigan_20221211.zip
- 解压后,将四个文件放在
pretrain/nsf_hifigan目录下
- 解压后,将四个文件放在
# nsf_hifigan
wget -P pretrain/ https://github.com/openvpi/vocoders/releases/download/nsf-hifigan-v1/nsf_hifigan_20221211.zip
unzip -od pretrain/nsf_hifigan pretrain/nsf_hifigan_20221211.zip
# 也可手动下载放在 pretrain/nsf_hifigan 目录
# 地址:https://github.com/openvpi/vocoders/releases/tag/nsf-hifigan-v1
RMVPE
如果使用rmvpeF0预测器的话,需要下载预训练的 RMVPE 模型
- 下载模型rmvpe.zip,目前首推该权重。
- 解压缩
rmvpe.zip,并将其中的model.pt文件改名为rmvpe.pt并放在pretrain目录下
- 解压缩
下载模型 rmvpe.pt放在pretrain目录下
FCPE(预览版)
你说的对,但是FCPE是由svc-develop-team自主研发的一款全新的F0预测器,后面忘了
FCPE(Fast Context-base Pitch Estimator)是一个为实时语音转换所设计的专用F0预测器,他将在未来成为Sovits实时语音转换的首选F0预测器.(论文未来会有的)
如果使用 fcpe F0预测器的话,需要下载预训练的 FCPE 模型
-
下载模型 fcpe.pt
- 放在
pretrain目录下
- 放在
四、📊 数据集准备
仅需要以以下文件结构将数据集放入 dataset_raw 目录即可。
dataset_raw
├───speaker0
│ ├───xxx1-xxx1.wav
│ ├───...
│ └───Lxx-0xx8.wav
└───speaker1
├───xx2-0xxx2.wav
├───...
└───xxx7-xxx007.wav
对于每一个音频文件的名称并没有格式的限制(000001.wav~999999.wav之类的命名方式也是合法的),不过文件类型必须是wav。
可以自定义说话人名称
dataset_raw
└───suijiSUI
├───1.wav
├───...
└───25788785-20221210-200143-856_01_(Vocals)_0_0.wav
五、🛠️ 数据预处理
0、音频切片
将音频切片至5s - 15s, 稍微长点也无伤大雅,实在太长可能会导致训练中途甚至预处理就爆显存
可以使用 audio-slicer-GUI、audio-slicer-CLI
一般情况下只需调整其中的Minimum Interval,普通陈述素材通常保持默认即可,歌唱素材可以调整至100甚至50
切完之后手动删除过长过短的音频
如果你使用 Whisper-ppg 声音编码器进行训练,所有的切片长度必须小于 30s
1、重采样至 44100Hz 单声道
python resample.py
注意
虽然本项目拥有重采样、转换单声道与响度匹配的脚本 resample.py,但是默认的响度匹配是匹配到 0db。这可能会造成音质的受损。而 python 的响度匹配包 pyloudnorm 无法对电平进行压限,这会导致爆音。所以建议可以考虑使用专业声音处理软件如adobe audition等软件做响度匹配处理。若已经使用其他软件做响度匹配,可以在运行上述命令时添加--skip_loudnorm跳过响度匹配步骤。如:
python resample.py --skip_loudnorm
2、自动划分训练集、验证集,以及自动生成配置文件
python preprocess_flist_config.py --speech_encoder vec768l12
speech_encoder 拥有以下选择
vec768l12
vec256l9
hubertsoft
whisper-ppg
whisper-ppg-large
cnhubertlarge
dphubert
wavlmbase+
如果省略 speech_encoder 参数,默认值为 vec768l12
使用响度嵌入
若使用响度嵌入,需要增加--vol_aug参数,比如:
python preprocess_flist_config.py --speech_encoder vec768l12 --vol_aug
使用后训练出的模型将匹配到输入源响度,否则为训练集响度。
此时可以在生成的 config.json 与 diffusion.yaml 修改部分参数
config.json
keep_ckpts:训练时保留最后几个模型,0为保留所有,默认只保留最后3个all_in_mem:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 远大于 数据集体积时可以启用batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可vocoder_name: 选择一种声码器,默认为nsf-hifigan.
diffusion.yaml
cache_all_data:加载所有数据集到内存中,某些平台的硬盘 IO 过于低下、同时内存容量 远大于 数据集体积时可以启用duration:训练时音频切片时长,可根据显存大小调整,注意,该值必须小于训练集内音频的最短时间!batch_size:单次训练加载到 GPU 的数据量,调整到低于显存容量的大小即可timesteps: 扩散模型总步数,默认为 1000.k_step_max: 训练时可仅训练k_step_max步扩散以节约训练时间,注意,该值必须小于timesteps,0 为训练整个扩散模型,注意,如果不训练整个扩散模型将无法使用仅扩散模型推理!
声码器列表
nsf-hifigan
nsf-snake-hifigan
3、生成 hubert 与 f0
python preprocess_hubert_f0.py --f0_predictor dio
f0_predictor 拥有以下选择
crepe
dio
pm
harvest
rmvpe
fcpe
如果训练集过于嘈杂,请使用 crepe 处理 f0
如果省略 f0_predictor 参数,默认值为 rmvpe
尚若需要浅扩散功能(可选),需要增加–use_diff 参数,比如
python preprocess_hubert_f0.py --f0_predictor dio --use_diff
加速预处理 如若您的数据集比较大,可以尝试添加--num_processes参数:
python preprocess_hubert_f0.py --f0_predictor dio --use_diff --num_processes 8
所有的Workers会被自动分配到多个线程上
执行完以上步骤后 dataset 目录便是预处理完成的数据,可以删除 dataset_raw 文件夹了
六、🏋️ 训练
主模型训练
python train.py -c configs/config.json -m 44k
扩散模型(可选)
尚若需要浅扩散功能,需要训练扩散模型,扩散模型训练方法为:
python train_diff.py -c configs/diffusion.yaml
模型训练结束后,模型文件保存在logs/44k目录下,扩散模型在logs/44k/diffusion下
七、🤖 推理
# 例
python inference_main.py -m "logs/44k/G_30400.pth" -c "configs/config.json" -n "君の知らない物語-src.wav" -t 0 -s "nen"
必填项部分:
-m|--model_path:模型路径-c|--config_path:配置文件路径-n|--clean_names:wav 文件名列表,放在 raw 文件夹下-t|--trans:音高调整,支持正负(半音)-s|--spk_list:合成目标说话人名称-cl|--clip:音频强制切片,默认 0 为自动切片,单位为秒/s
可选项部分:部分具体见下一节
-lg|--linear_gradient:两段音频切片的交叉淡入长度,如果强制切片后出现人声不连贯可调整该数值,如果连贯建议采用默认值 0,单位为秒-f0p|--f0_predictor:选择 F0 预测器,可选择 crepe,pm,dio,harvest,rmvpe,fcpe, 默认为 pm(注意:crepe 为原 F0 使用均值滤波器)-a|--auto_predict_f0:语音转换自动预测音高,转换歌声时不要打开这个会严重跑调-cm|--cluster_model_path:聚类模型或特征检索索引路径,留空则自动设为各方案模型的默认路径,如果没有训练聚类或特征检索则随便填-cr|--cluster_infer_ratio:聚类方案或特征检索占比,范围 0-1,若没有训练聚类模型或特征检索则默认 0 即可-eh|--enhance:是否使用 NSF_HIFIGAN 增强器,该选项对部分训练集少的模型有一定的音质增强效果,但是对训练好的模型有反面效果,默认关闭-shd|--shallow_diffusion:是否使用浅层扩散,使用后可解决一部分电音问题,默认关闭,该选项打开时,NSF_HIFIGAN 增强器将会被禁止-usm|--use_spk_mix:是否使用角色融合/动态声线融合-lea|--loudness_envelope_adjustment:输入源响度包络替换输出响度包络融合比例,越靠近 1 越使用输出响度包络-fr|--feature_retrieval:是否使用特征检索,如果使用聚类模型将被禁用,且 cm 与 cr 参数将会变成特征检索的索引路径与混合比例
浅扩散设置:
-dm|--diffusion_model_path:扩散模型路径-dc|--diffusion_config_path:扩散模型配置文件路径-ks|--k_step:扩散步数,越大越接近扩散模型的结果,默认 100-od|--only_diffusion:纯扩散模式,该模式不会加载 sovits 模型,以扩散模型推理-se|--second_encoding:二次编码,浅扩散前会对原始音频进行二次编码,玄学选项,有时候效果好,有时候效果差
注意!
如果使用whisper-ppg 声音编码器进行推理,需要将--clip设置为 25,-lg设置为 1。否则将无法正常推理。
八、🤔 可选项
如果前面的效果已经满意,或者没看明白下面在讲啥,那后面的内容都可以忽略,不影响模型使用(这些可选项影响比较小,可能在某些特定数据上有点效果,但大部分情况似乎都感知不太明显)
自动 f0 预测
4.0 模型训练过程会训练一个 f0 预测器,对于语音转换可以开启自动音高预测,如果效果不好也可以使用手动的,但转换歌声时请不要启用此功能!!!会严重跑调!!
- 在 inference_main 中设置 auto_predict_f0 为 true 即可
聚类音色泄漏控制
介绍:聚类方案可以减小音色泄漏,使得模型训练出来更像目标的音色(但其实不是特别明显),但是单纯的聚类方案会降低模型的咬字(会口齿不清)(这个很明显),本模型采用了融合的方式,可以线性控制聚类方案与非聚类方案的占比,也就是可以手动在"像目标音色" 和 “咬字清晰” 之间调整比例,找到合适的折中点
使用聚类前面的已有步骤不用进行任何的变动,只需要额外训练一个聚类模型,虽然效果比较有限,但训练成本也比较低
- 训练过程:
- 使用 cpu 性能较好的机器训练,据我的经验在腾讯云 6 核 cpu 训练每个 speaker 需要约 4 分钟即可完成训练
- 执行
python cluster/train_cluster.py,模型的输出会在logs/44k/kmeans_10000.pt - 聚类模型目前可以使用 gpu 进行训练,执行
python cluster/train_cluster.py --gpu
- 推理过程:
inference_main.py中指定cluster_model_path为模型输出文件,留空则默认为logs/44k/kmeans_10000.ptinference_main.py中指定cluster_infer_ratio,0为完全不使用聚类,1为只使用聚类,通常设置0.5即可
特征检索
介绍:跟聚类方案一样可以减小音色泄漏,咬字比聚类稍好,但会降低推理速度,采用了融合的方式,可以线性控制特征检索与非特征检索的占比,
- 训练过程: 首先需要在生成 hubert 与 f0 后执行:
python train_index.py -c configs/config.json
模型的输出会在logs/44k/feature_and_index.pkl
- 推理过程:
- 需要首先指定
--feature_retrieval,此时聚类方案会自动切换到特征检索方案 inference_main.py中指定cluster_model_path为模型输出文件,留空则默认为logs/44k/feature_and_index.pklinference_main.py中指定cluster_infer_ratio,0为完全不使用特征检索,1为只使用特征检索,通常设置0.5即可
- 需要首先指定
九、🗜️ 模型压缩
生成的模型含有继续训练所需的信息。如果确认不再训练,可以移除模型中此部分信息,得到约 1/3 大小的最终模型。
# 例
python compress_model.py -c="configs/config.json" -i="logs/44k/G_30400.pth" -o="logs/44k/release.pth"
十、👨🔧 声线混合
静态声线混合
参考webUI.py文件中,小工具/实验室特性的静态声线融合。
介绍:该功能可以将多个声音模型合成为一个声音模型(多个模型参数的凸组合或线性组合),从而制造出现实中不存在的声线 注意:
- 该功能仅支持单说话人的模型
- 如果强行使用多说话人模型,需要保证多个模型的说话人数量相同,这样可以混合同一个 SpaekerID 下的声音
- 保证所有待混合模型的 config.json 中的 model 字段是相同的
- 输出的混合模型可以使用待合成模型的任意一个 config.json,但聚类模型将不能使用
- 批量上传模型的时候最好把模型放到一个文件夹选中后一起上传
- 混合比例调整建议大小在 0-100 之间,也可以调为其他数字,但在线性组合模式下会出现未知的效果
- 混合完毕后,文件将会保存在项目根目录中,文件名为 output.pth
- 凸组合模式会将混合比例执行 Softmax 使混合比例相加为 1,而线性组合模式不会
动态声线混合
参考spkmix.py文件中关于动态声线混合的介绍
角色混合轨道 编写规则:
角色 ID : [[起始时间 1, 终止时间 1, 起始数值 1, 起始数值 1], [起始时间 2, 终止时间 2, 起始数值 2, 起始数值 2]]
起始时间和前一个的终止时间必须相同,第一个起始时间必须为 0,最后一个终止时间必须为 1 (时间的范围为 0-1)
全部角色必须填写,不使用的角色填、[[0., 1., 0., 0.]] 即可
融合数值可以随便填,在指定的时间段内从起始数值线性变化为终止数值,内部会自动确保线性组合为 1(凸组合条件),可以放心使用
推理的时候使用--use_spk_mix参数即可启用动态声线混合
十一、📤 Onnx 导出
- 新建文件夹:
checkpoints并打开 - 在
checkpoints文件夹中新建一个文件夹作为项目文件夹,文件夹名为你的项目名称,比如aziplayer - 将你的模型更名为
model.pth,配置文件更名为config.json,并放置到刚才创建的aziplayer文件夹下 - 将 onnx_export.py 中
path = "NyaruTaffy"的"NyaruTaffy"修改为你的项目名称,path = "aziplayer" (onnx_export_speaker_mix,为支持角色混合的 onnx 导出) - 运行 onnx_export.py
- 等待执行完毕,在你的项目文件夹下会生成一个
model.onnx,即为导出的模型
注意:Hubert Onnx 模型请使用 MoeSS 提供的模型,目前无法自行导出(fairseq 中 Hubert 有不少 onnx 不支持的算子和涉及到常量的东西,在导出时会报错或者导出的模型输入输出 shape 和结果都有问题)
十二、📎 引用及论文
| URL | 名称 | 标题 | 源码 |
|---|---|---|---|
| 2106.06103 | VITS (Synthesizer) | Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech | jaywalnut310/vits |
| 2111.02392 | SoftVC (Speech Encoder) | A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion | bshall/hubert |
| 2204.09224 | ContentVec (Speech Encoder) | ContentVec: An Improved Self-Supervised Speech Representation by Disentangling Speakers | auspicious3000/contentvec |
| 2212.04356 | Whisper (Speech Encoder) | Robust Speech Recognition via Large-Scale Weak Supervision | openai/whisper |
| 2110.13900 | WavLM (Speech Encoder) | WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing | microsoft/unilm/wavlm |
| 2305.17651 | DPHubert (Speech Encoder) | DPHuBERT: Joint Distillation and Pruning of Self-Supervised Speech Models | pyf98/DPHuBERT |
| DOI:10.21437/Interspeech.2017-68 | Harvest (F0 Predictor) | Harvest: A high-performance fundamental frequency estimator from speech signals | mmorise/World/harvest |
| aes35-000039 | Dio (F0 Predictor) | Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech | mmorise/World/dio |
| 8461329 | Crepe (F0 Predictor) | Crepe: A Convolutional Representation for Pitch Estimation | maxrmorrison/torchcrepe |
| DOI:10.1016/j.wocn.2018.07.001 | Parselmouth (F0 Predictor) | Introducing Parselmouth: A Python interface to Praat | YannickJadoul/Parselmouth |
| 2306.15412v2 | RMVPE (F0 Predictor) | RMVPE: A Robust Model for Vocal Pitch Estimation in Polyphonic Music | Dream-High/RMVPE |
| 2010.05646 | HIFIGAN (Vocoder) | HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis | jik876/hifi-gan |
| 1810.11946 | NSF (Vocoder) | Neural source-filter-based waveform model for statistical parametric speech synthesis | openvpi/DiffSinger/modules/nsf_hifigan |
| 2006.08195 | Snake (Vocoder) | Neural Networks Fail to Learn Periodic Functions and How to Fix It | EdwardDixon/snake |
| 2105.02446v3 | Shallow Diffusion (PostProcessing) | DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism | CNChTu/Diffusion-SVC |
| K-means | Feature K-means Clustering (PreProcessing) | Some methods for classification and analysis of multivariate observations | 本代码库 |
| Feature TopK Retrieval (PreProcessing) | Retrieval based Voice Conversion | RVC-Project/Retrieval-based-Voice-Conversion-WebUI |
📚 一些法律条例参考
任何国家,地区,组织和个人使用此项目必须遵守以下法律
《民法典》
第一千零一十九条
任何组织或者个人不得以丑化、污损,或者利用信息技术手段伪造等方式侵害他人的肖像权。未经肖像权人同意,不得制作、使用、公开肖像权人的肖像,但是法律另有规定的除外。未经肖像权人同意,肖像作品权利人不得以发表、复制、发行、出租、展览等方式使用或者公开肖像权人的肖像。对自然人声音的保护,参照适用肖像权保护的有关规定。
第一千零二十四条
【名誉权】民事主体享有名誉权。任何组织或者个人不得以侮辱、诽谤等方式侵害他人的名誉权。
第一千零二十七条
【作品侵害名誉权】行为人发表的文学、艺术作品以真人真事或者特定人为描述对象,含有侮辱、诽谤内容,侵害他人名誉权的,受害人有权依法请求该行为人承担民事责任。行为人发表的文学、艺术作品不以特定人为描述对象,仅其中的情节与该特定人的情况相似的,不承担民事责任。



















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











