








一、关于 Mooncake
Mooncake 是 kini的服务平台,是Moonshot AI 提供的 领先的大模型服务。
以KVCache为中心的分解 体系结构,用于LLM服务。
🔄更新
- 2024年12月16日:vLLM正式支持Mooncake 传输引擎进行分解预填充和KV缓存传输。
- 2024年11月28日:我们开源了Mooncake 的核心组件Transfer Engine。我们还提供了两个传输引擎演示:P2P商店和vLLM集成。
- 2024年7月9日:我们将跟踪开源为jsonl文件!。
- 2024年6月27日:我们展示了一系列关于知乎1、2、3、4的更多讨论的中文博客。
- 2024年6月26日:初始技术报告发布。
🎉概览
Mooncake 具有以KVCache为中心的分解架构,将预填充和解码集群分开。它还利用GPU集群未充分利用的CPU、DRAM和SSD资源来实现KVCache的分解缓存。
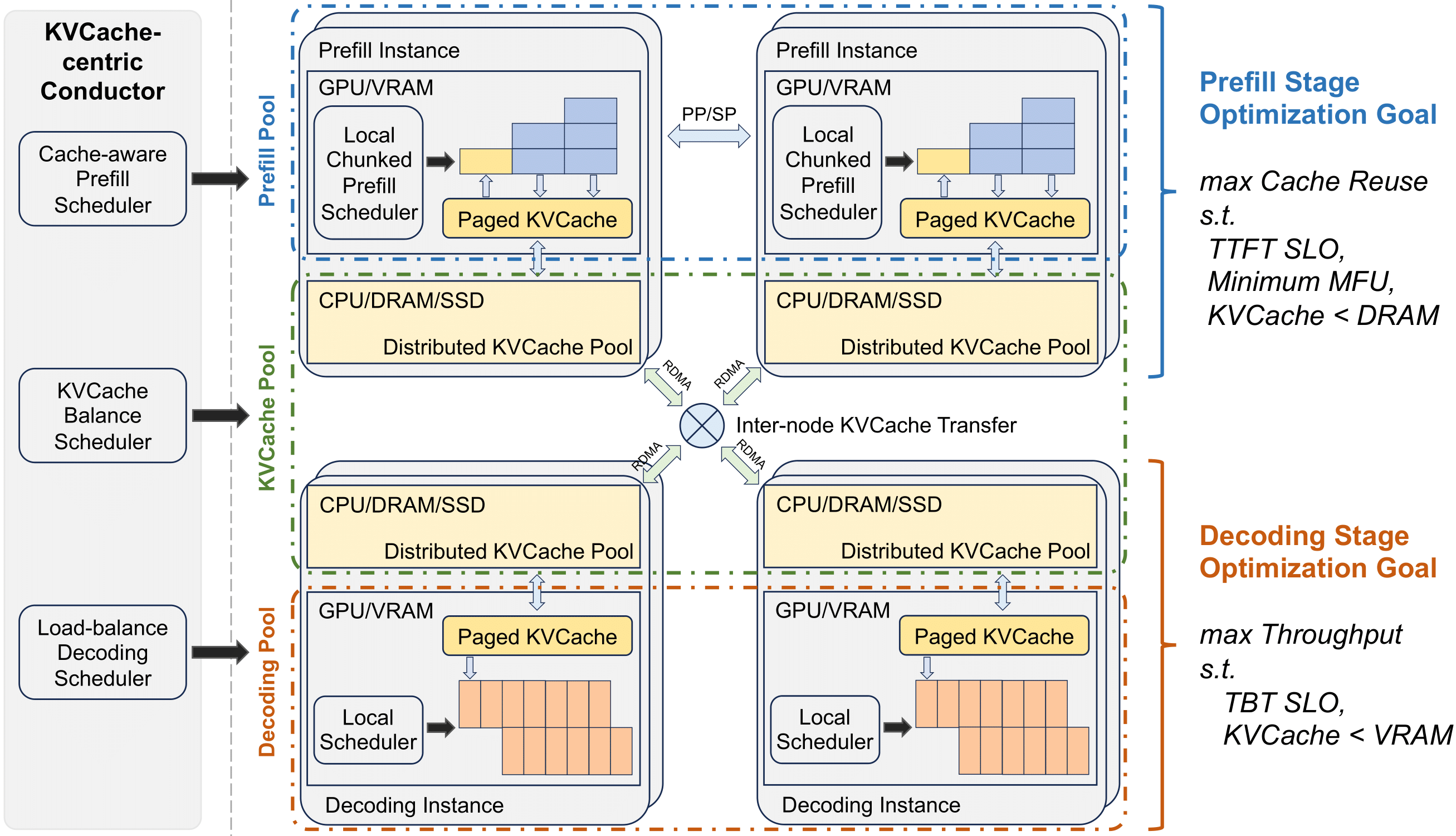
Mooncake的核心是其以KVCache为中心的调度器,它在满足与延迟相关的服务级别目标(SLO)要求的同时,平衡了最大化整体有效吞吐量。
与假设所有请求都会被处理的传统研究不同,Mooncake 面临着由于高度超载的情况而带来的挑战。为了缓解这些问题,我们开发了一种基于预测的早期拒绝策略。
实验表明,Mooncake 在长上下文场景中表现出色。与基线方法相比,Mooncake 在某些模拟场景中可以实现高达525%的吞吐量增长,同时遵守SLO。
在实际工作负载下,Mooncake的创新架构使Kimi能够处理75%以上的请求。
🧩组件
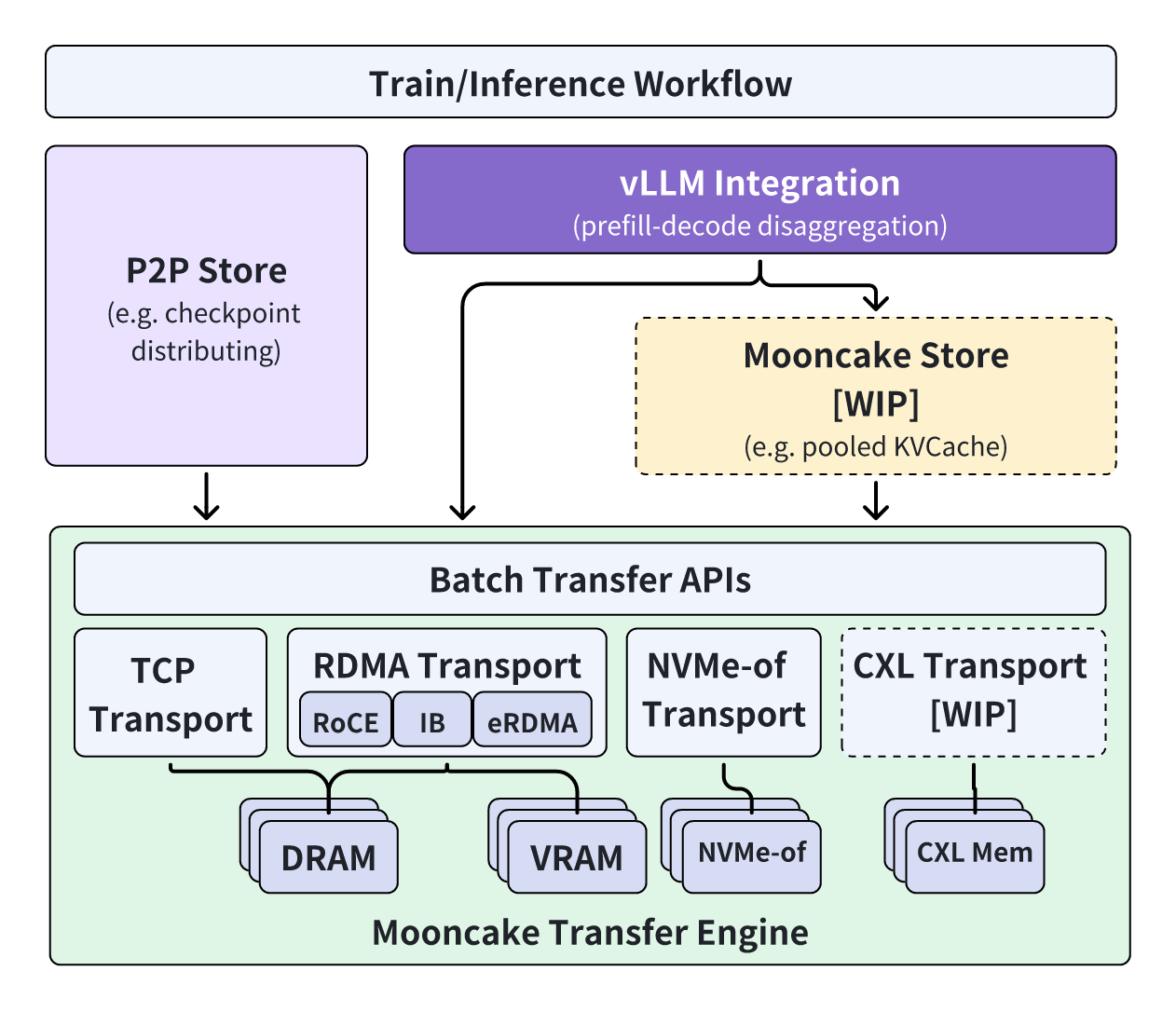
- Mooncake 的底部是传输引擎,它支持通过TCP、RDMA、基于NVIDIA GPUDirect的RDMA和NVMe over Fabric(NVMe-of)协议进行快速、可靠和灵活的数据搬迁。与Gloo(分布式PyTorch使用)和TCP相比,Mooncake 传输引擎具有最低的I/O延迟。
- 基于Transfer Engine,我们实现了P2P Store库,支持在集群中的节点之间共享临时对象(例如检查点文件)。它避免了单台机器上的带宽饱和。
- 此外,我们修改了vLLM以集成传输引擎。它利用RDMA设备使预填充解码分解更高效。
- 未来,我们计划在Transfer Engine的基础上构建Mooncake 店,支持池化KVCache,实现更灵活的P/D分解。
二、🔥案例展示
1、使用独立传输引擎
指南 : https://github.com/kvcache-ai/Mooncake/blob/main/doc/en/transfer-engine.md
传输引擎(Transfer Engine) 是一个高性能的数据搬迁框架。传输引擎提供了一个统一的接口来传输来自DRAM、VRAM或NVMe的数据,同时隐藏了与硬件相关的技术细节。
传输引擎支持TCP、RDMA(InfiniBand/RoCEv2/eRDMA/NVIDIA GPUDirect)和 NVMe over Fabric(NVMe-of)协议。
亮点
- 高效使用多个RDMA网卡设备。传输引擎支持使用多个RDMA网卡设备来实现传输带宽的聚合。
- 拓扑感知路径选择。传输引擎可以根据源和目标的位置(NUMA亲和力等)选择最佳设备。
- 对临时网络错误更健壮。一旦传输失败,Transfer Engine将尝试使用替代路径自动传输数据。
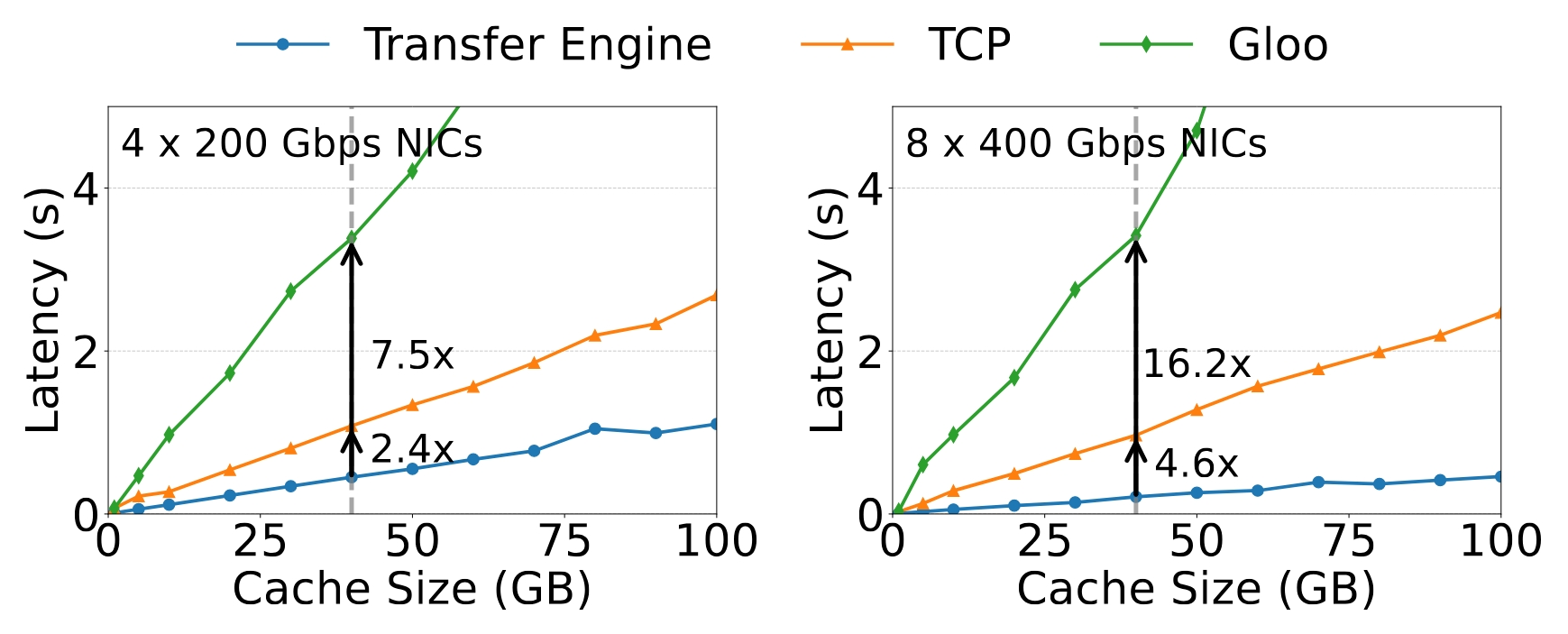
性能
87 GB/s190 GB/s2.4x和4.6x更快
2、P2P Store
指南 : https://github.com/kvcache-ai/Mooncake/blob/main/doc/en/p2p-store.md
P2P Store已用于Moonshot AI的关卡转移服务。
亮点
- 去中心化架构。P2P商店利用纯客户端架构,全局元数据由etcd服务管理。
- 高效的数据分发。P2P Store旨在提高大规模数据分发的效率,通过允许复制节点直接共享数据来避免带宽饱和问题。这降低了数据提供商(例如培训师)的CPU/RDMA网卡压力。
性能
硬件输入带宽
3、vLLM集成
Guide v0.2 : https://github.com/kvcache-ai/Mooncake/blob/main/doc/en/vllm-integration-v0.2.md
为了优化LLM推理,vLLM社区正在努力支持 分类预填充(PR 10502)。此功能允许在不同过程中将预填充阶段与解码阶段分开。vLLM默认使用“nccl”和“gloo”作为传输层,但目前它无法有效地解耦不同机器中的两个相位。
我们已经实现了vLLM集成,它使用传输引擎作为网络层,而不是“nccl”和“gloo”,以支持节点间KVCache传输(PR 10884)。
传输引擎提供了更简单的接口和更有效的RDMA设备使用。未来,我们计划在Transfer Engine的基础上构建月饼商店,该引擎支持池式预填充/解码分解。
更新[2024年12月16日]:这是最新的vLLM集成(Guide v0.2) 它基于vLLM的主分支。
性能
通过支持拓扑感知路径选择和多卡带宽聚合,带有传输引擎的vLLM的平均TTFT比传统的基于TCP的传输低25%。未来,我们将通过GPUDirect RDMA和零拷贝进一步改进TTFT。
| 后端/设置 | 输出令牌吞吐量(tok/s) | 总令牌吞吐量(tok/s) | 平均TTFT(ms) | 中值TTFT(ms) | P99 TTFT(ms) |
|---|---|---|---|---|---|
| 传输引擎(RDMA) | 12.06 | 2042.74 | 1056.76 | 635.00 | 4006.59 |
| TCP | 12.05 | 2041.13 | 1414.05 | 766.23 | 6035.36 |
- 单击此处访问详细的基准测试结果。
更多高级功能即将推出,敬请期待!
三、🚀快速入门
1、准备
为了安装和使用Mooncake ,需要一些准备。
- RDMA驱动程序和SDK(例如,Mellanox OFED)。
- Linux-使用gcc、g++(9.4+)和cmake(3.16+)x86_64。
- Python(3.10或以上)
此外,为了支持月饼传输引擎的更多功能,我们建议您安装以下组件:
-
CUDA 12.1及以上版本,包括NVIDIA GPUDirect存储支持,如果您想使用
-DUSE_CUDA构建。你可以从这里安装:https://developer.nvidia.com/cuda-downloads
# Adding CUDA to PATH export PATH=/usr/local/cuda/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH export CUDA_PATH=/usr/local/cuda
- Go 1.20+,如果你想建立
-DWITH_P2P_STORE。你可以从这里下载。 - Rust Toolclain,如果你想用
-DWITH_WITH_RUST_EXAMPLE构建。 hiredis,如果你想用-DUSE_REDIS构建,这样你就可以使用Redis而不是etcd作为元数据服务器。curl,如果你想用-DUSE_HTTP构建,这样你就可以使用HTTP而不是etcd作为元数据服务器。
2、安装
1、初始化源代码
git clone https://github.com/kvcache-ai/Mooncake.git
cd Mooncake
2、安装依赖项
bash dependencies.sh
3、编译Mooncake 和示例
mkdir build
cd build
cmake .. # (optional) Specify build options like -D
make -j
四、项目发展
🛣️即将到来的里程碑
- Mooncake 首次发布并与最新的vLLM集成
- 跨多个服务引擎共享KV缓存
- 用户和开发者文档
📦开源跟踪
{
"timestamp": 27482,
"input_length": 6955,
"output_length": 52,
"hash_ids": [46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 2353, 2354]
}
{
"timestamp": 30535,
"input_length": 6472,
"output_length": 26,
"hash_ids": [46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 2366]
}
上面展示了我们跟踪数据集中的两个样本。跟踪包括请求到达的时间、进审量令牌、输出令牌的数量和重新映射的块哈希。为了保护我们客户的隐私,我们应用了几种机制来删除用户相关信息,同时保留数据集用于模拟评估的效用。跟踪的更多描述(例如,高达50%的缓存命中率)可以在论文第3版的第4节中找到。
2025-01-29(三)



















 738
738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











