







本文翻译整理自:https://github.com/descriptinc/descript-audio-codec
文章目录
一、关于 Descript Audio Codec
该代码库包含Descript音频编解码器(.dac)的训练和推理脚本,这是一种高保真通用神经音频编解码器,相关技术发表于论文《基于改进RVQGAN的高保真音频压缩》。
👉 通过Descript音频编解码器,您可以将44.1 KHz音频压缩为8 kbps低比特率的离散编码
🤌 实现约90倍压缩比的同时保持卓越保真度并最小化伪影
💪 通用模型适用于所有音频领域(语音、环境音、音乐等),可广泛用于各类音频生成建模
👌 可作为EnCodec的直接替代方案,适用于所有音频语言建模应用(如AudioLMs、MusicLMs、MusicGen等)
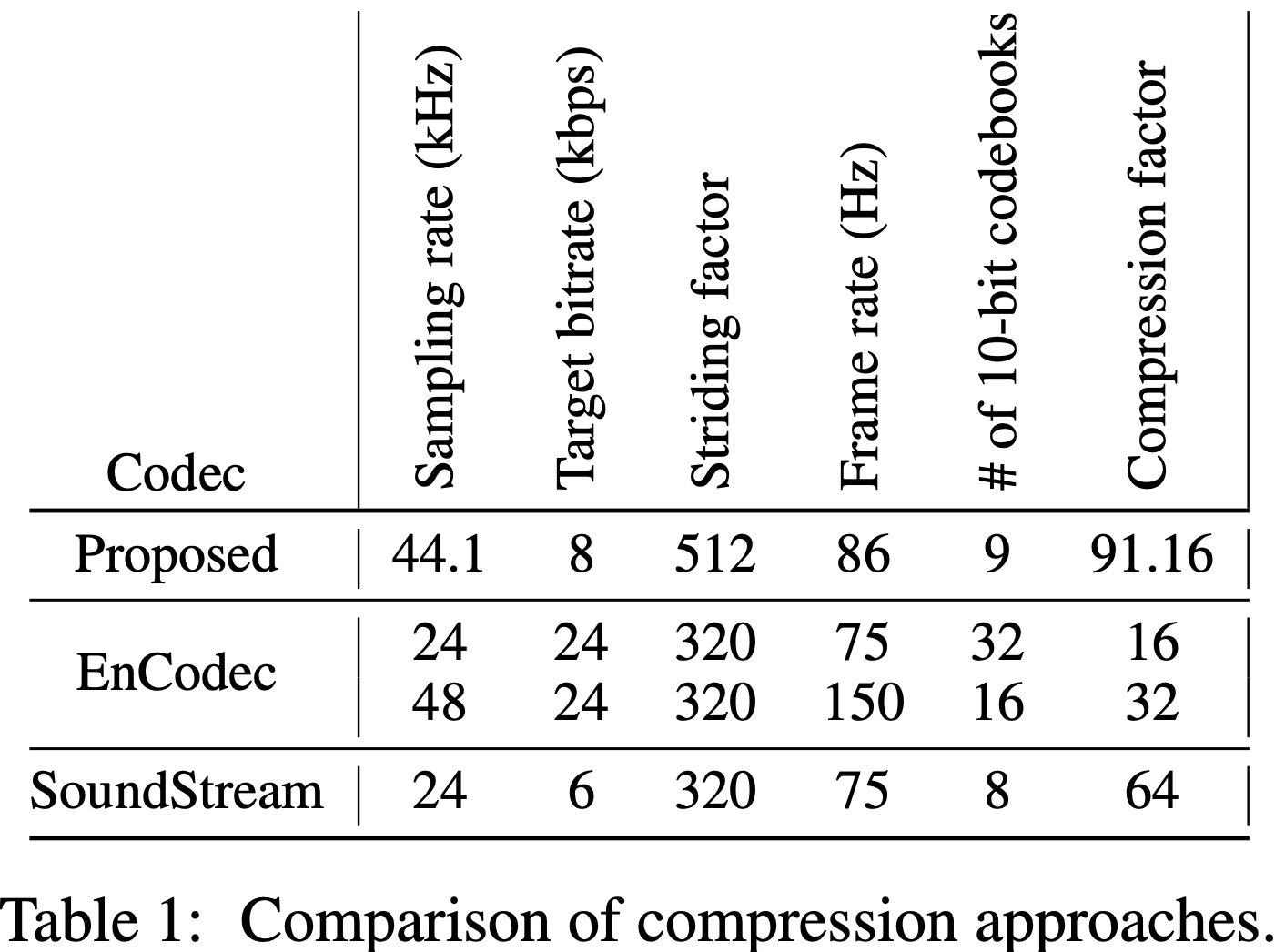
对比不同压缩方法。我们的模型实现了比所有基线方法更高的压缩比。与EnCodec的32倍和SoundStream的64倍压缩比相比,我们达到约90倍压缩比。注意:我们工作在8 kbps目标比特率下(EnCodec为24 kbps,SoundStream为6 kbps),采样率为44.1 kHz(EnCodec为48 kHz,SoundStream为24 kHz)
- paper:High-Fidelity Audio Compression with Improved RVQGANhttp://arxiv.org/abs/2306.06546
- 📈 演示站点 : https://descript.notion.site/Descript-Audio-Codec-11389fce0ce2419891d6591a68f814d5
- ⚙ 模型权重 : https://github.com/descriptinc/descript-audio-codec/releases/download/0.0.1/weights.pth
二、安装
安装方式
pip install descript-audio-codec
或
pip install git+https://github.com/descriptinc/descript-audio-codec
模型权重
权重文件通过MIT许可证随本代码库发布,支持16 kHz、24kHz和44.1kHz采样率的原生模型。首次运行encode或decode命令时会自动下载权重,也可通过以下命令预下载:
python3 -m dac download # 下载默认44kHz版本
python3 -m dac download --model_type 44khz # 下载44kHz版本
python3 -m dac download --model_type 24khz # 下载24kHz版本
python3 -m dac download --model_type 16khz # 下载16kHz版本
我们提供了包含编解码所需全部依赖的Dockerfile,构建过程中会将默认模型权重缓存至镜像内,使镜像可在无网络环境下使用。
三、使用指南
音频压缩
python3 -m dac encode /path/to/input --output /path/to/output/codes
该命令会生成与输入文件同名的.dac文件,并保持输入目录的相对结构。更多选项请使用python -m dac encode --help查看。
从压缩编码重建音频
python3 -m dac decode /path/to/output/codes --output /path/to/reconstructed_input
该命令会生成与输入文件同名的.wav文件,并保持输入目录的相对结构。更多选项请使用python -m dac decode --help查看。
编程式调用
import dac
from audiotools import AudioSignal
# 下载模型
model_path = dac.utils.download(model_type="44khz")
model = dac.DAC.load(model_path)
model.to('cuda')
# 加载音频文件
signal = AudioSignal('input.wav')
# 将音频信号编码为单个长文件
# (长文件可能导致GPU内存不足)
signal.to(model.device)
x = model.preprocess(signal.audio_data, signal.sample_rate)
z, codes, latents, _, _ = model.encode(x)
# 解码音频信号
y = model.decode(z)
# 也可使用`compress`和`decompress`函数处理长文件
signal = signal.cpu()
x = model.compress(signal)
# 保存到磁盘及加载
x.save("compressed.dac")
x = dac.DACFile.load("compressed.dac")
# 解压回AudioSignal对象
y = model.decompress(x)
# 写入文件
y.write('output.wav')
Docker镜像
我们提供包含全部依赖的Dockerfile:
1、构建镜像
docker build -t dac .
2、使用镜像
CPU模式:
docker run dac <command>
GPU模式:
docker run --gpus=all dac <command>
<command>可为前文列出的压缩/重建命令,例如执行压缩:
docker run --gpus=all dac python3 -m dac encode ...
四、模型训练
准备工作
安装必要依赖:
pip install -e ".[dev]"
环境配置
我们提供了Dockerfile和docker compose配置简化实验环境:
1、构建镜像:
docker compose build
2、启动容器:
docker compose run -p 8888:8888 -p 6006:6006 dev
端口参数(-p)可选,用于在容器内启动Jupyter和Tensorboard。Jupyter默认密码为password,当前目录会挂载至/u/home/src并设为工作目录。
单GPU训练
export CUDA_VISIBLE_DEVICES=0
python scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
多GPU训练
export CUDA_VISIBLE_DEVICES=0,1
torchrun --nproc_per_node gpu scripts/train.py --args.load conf/ablations/baseline.yml --save_path runs/baseline/
五、测试验证
我们提供两个测试脚本验证CLI和训练功能,请确保满足训练前提条件后运行:
python -m pytest tests
六、性能表现
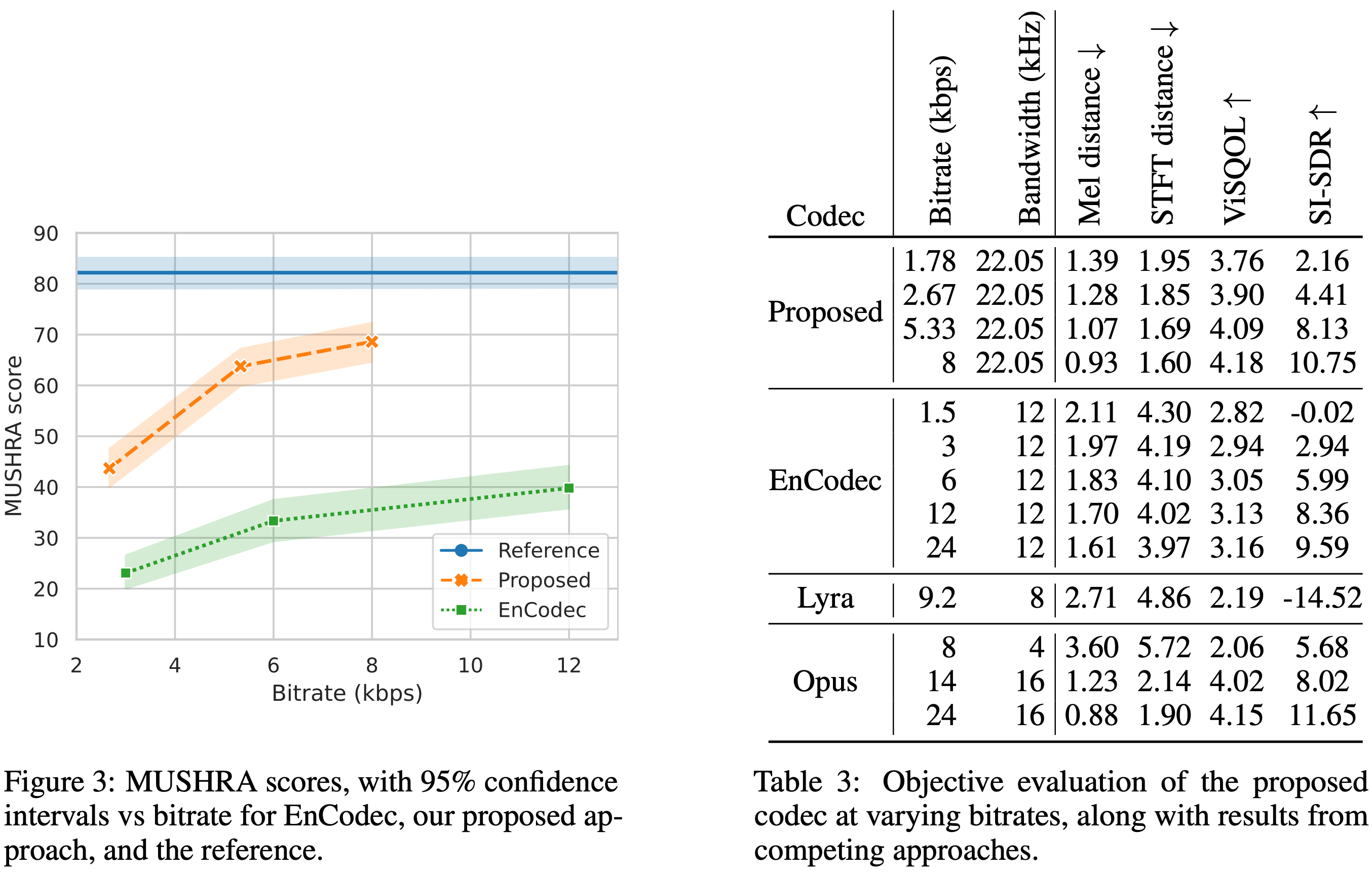
伊织 xAI 2025-04-29(二)




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











