







文章目录
NumPy 基础
这些文档阐明了 NumPy 中的核心概念、设计决策和技术限制。这里是理解 NumPy 基础理念和哲学的最佳起点。
数组创建
https://numpy.org/doc/stable/user/basics.creation.html
另请参阅:数组创建例程
简介
创建数组通常有以下6种方法:
1、从其他Python数据结构转换(如列表和元组)
2、使用NumPy内置的数组创建函数(如arange、ones、zeros等)
3、复制、连接或修改现有数组
4、从磁盘读取数组数据(标准格式或自定义格式)
5、通过字符串或缓冲区从原始字节创建数组
6、使用特殊库函数(例如random模块)
这些方法可用于创建ndarray或结构化数组。本文档将重点介绍ndarray创建的通用方法。
1) 将Python序列转换为NumPy数组
NumPy数组可以通过Python序列(如列表和元组)来定义。列表和元组分别使用[...]和(...)进行定义。列表和元组可用于创建ndarray:
- 数字列表将创建一维数组
- 列表的列表将创建二维数组
- 更深层嵌套的列表将创建更高维度的数组
在NumPy中,任何数组对象通常都被称为ndarray。
>>> import numpy as np
>>> a1D = np.array([1, 2, 3, 4])
>>> a2D = np.array([[1, 2], [3, 4]])
>>> a3D = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
当你使用 numpy.array 定义新数组时,应当考虑数组中元素的 dtype,该参数可以显式指定。这一特性让你能更精准地控制底层数据结构以及元素在 C/C++ 函数中的处理方式。
如果数值超出范围且你指定了 dtype,NumPy 可能会抛出错误:
>>> import numpy as np
>>> np.array([127, 128, 129], dtype=np.int8)
Traceback (most recent call last):
...
OverflowError: Python integer 128 out of bounds for int8
一个8位有符号整数表示从-128到127的整数。如果将int8数组赋给超出此范围的整数,会导致溢出。这个特性经常容易被误解。如果你使用不匹配的dtypes进行计算,可能会得到不想要的结果,例如:
>>> import numpy as np
>>> a = np.array([2, 3, 4], dtype=np.uint32)
>>> b = np.array([5, 6, 7], dtype=np.uint32)
>>> c_unsigned32 = a - b
>>> print('unsigned c:', c_unsigned32, c_unsigned32.dtype)
unsigned c: [4294967293 4294967293 4294967293] uint32
>>> c_signed32 = a - b.astype(np.int32)
>>> print('signed c:', c_signed32, c_signed32.dtype)
signed c: [-3 -3 -3] int64
请注意,当你对两个相同dtype(如uint32)的数组进行操作时,结果数组会保持相同类型。而当操作涉及不同dtype时,NumPy会分配一个能够容纳所有参与计算数组元素的新类型——例如uint32和int32可以统一表示为int64。
NumPy的默认行为是创建32位或64位有符号整数数组(取决于平台,与C语言的long类型大小一致)或双精度浮点数数组。如果你需要确保整数数组是特定类型,必须在创建数组时显式指定dtype参数。
2) NumPy 数组创建的内置函数
NumPy 提供了超过 40 个内置函数用于创建数组,具体列在数组创建例程中。根据所创建数组的维度,这些函数大致可以分为三类:
1、一维数组
2、二维数组
3、多维数组
1 - 一维数组创建函数
一维数组创建函数如 numpy.linspace 和 numpy.arange 通常至少需要两个输入参数:start 和 stop。
numpy.arange 用于创建数值均匀递增的数组。查阅完整文档可获取详细信息和使用示例。以下展示部分示例:
>>> import numpy as np
>>> np.arange(10)
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> np.arange(2, 10, dtype=float)
array([2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.arange(2, 3, 0.1)
array([2、, 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9])
注意:numpy.arange 的最佳实践是使用整数类型的起始值、结束值和步长值。关于 dtype 有一些需要注意的细节。在第二个示例中,明确指定了 dtype。第三个示例中,数组使用 dtype=float 以适应 0.1 的步长。由于舍入误差,stop 值有时会被包含在结果中。
numpy.linspace 会创建具有指定数量元素的数组,这些元素在指定的起始值和结束值之间均匀分布。例如:
>>> import numpy as np
>>> np.linspace(1., 4., 6)
array([1、, 1.6, 2.2, 2.8, 3.4, 4、])
这个创建函数的优势在于,它能确保元素数量以及起始点和结束点。而之前的
arange(start, stop, step) 函数不会包含 stop 这个值。
2 - 二维数组创建函数
二维数组创建函数,例如 numpy.eye、numpy.diag 和 numpy.vander,用于定义以二维数组表示的特殊矩阵属性。
np.eye(n, m) 定义一个二维单位矩阵。其中 i=j(行索引与列索引相等)的元素为 1,其余元素为 0,如下所示:
>>> import numpy as np
>>> np.eye(3)
array([[1., 0., 0.],
[0., 1., 0.],
[0., 0., 1.]])
>>> np.eye(3, 5)
array([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.]])
numpy.diag 可以定义两种形式的数组:一种是沿对角线填充给定值的二维方阵,另一种是当输入二维数组时返回仅包含对角线元素的一维数组。这两个数组创建函数在进行线性代数运算时非常实用,例如:
>>> import numpy as np
>>> np.diag([1, 2, 3])
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
>>> np.diag([1, 2, 3], 1)
array([[0, 1, 0, 0],
[0, 0, 2, 0],
[0, 0, 0, 3],
[0, 0, 0, 0]])
>>> a = np.array([[1, 2], [3, 4]])
>>> np.diag(a)
array([1, 4])
vander(x, n) 定义一个范德蒙矩阵为二维 NumPy 数组。该范德蒙矩阵的每一列都是输入一维数组(或列表/元组)x 的递减幂次,其中最高多项式阶数为 n-1。此数组生成例程有助于构建线性最小二乘模型,例如:
>>> import numpy as np
>>> np.vander(np.linspace(0, 2, 5), 2)
array([[0、, 1、], [0.5, 1、], [1、, 1、], [1.5, 1、], [2、, 1、]])
>>> np.vander([1, 2, 3, 4], 2)
array([[1, 1],
[2, 1],
[3, 1],
[4, 1]])
>>> np.vander((1, 2, 3, 4), 4)
array([[ 1, 1, 1, 1],
[ 8, 4, 2, 1],
[27, 9, 3, 1],
[64, 16, 4, 1]])
3 - 通用 ndarray 创建函数
ndarray 创建函数如 numpy.ones、numpy.zeros 和 random 会根据指定的形状来定义数组。这些 ndarray 创建函数能够通过元组或列表指定维度和各维度的长度,从而创建任意维度的数组。
numpy.zeros 会创建一个填充 0 值的数组,其形状由参数指定。默认的 dtype 是 float64:
>>> import numpy as np
>>> np.zeros((2, 3))
array([[0., 0., 0.],
[0., 0., 0.]])
>>> np.zeros((2, 3, 2))
array([[[0., 0.],
[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.],
[0., 0.]]])
numpy.ones 会创建一个填充值为1的数组。在其他所有方面,它与 zeros 函数完全相同,具体表现如下:
>>> import numpy as np
>>> np.ones((2, 3))
array([[1., 1., 1.],
[1., 1., 1.]])
>>> np.ones((2, 3, 2))
array([[[1., 1.],
[1., 1.],
[1., 1.]],
[[1., 1.],
[1., 1.],
[1., 1.]]])
default_rng方法返回结果的random方法会创建一个填充0到1之间随机值的数组。该功能包含在numpy.random库中。
下面创建了两个形状分别为(2,3)和(2,3,2)的数组。随机种子设为42以便复现这些伪随机数:
>>> import numpy as np
>>> from numpy.random import default_rng
>>> default_rng(42).random((2,3))
array([[0.77395605, 0.43887844, 0.85859792],
[0.69736803, 0.09417735, 0.97562235]])
>>> default_rng(42).random((2,3,2))
array([[[0.77395605, 0.43887844],
[0.85859792, 0.69736803],
[0.09417735, 0.97562235]],
[[0.7611397 , 0.78606431],
[0.12811363, 0.45038594],
[0.37079802, 0.92676499]]])
numpy.indices 会创建一组数组(堆叠为一个更高维的数组),每个维度对应一个数组,分别表示该维度的变化情况:
>>> import numpy as np
>>> np.indices((3,3))
array([[[0, 0, 0],
[1, 1, 1],
[2, 2, 2]],
[[0, 1, 2],
[0, 1, 2],
[0, 1, 2]]])
这对于在规则网格上评估多维函数特别有用。
3) 复制、连接或修改现有数组
创建数组后,可以通过复制、连接或修改现有数组来生成新数组。当您将数组或其元素赋值给新变量时,必须显式调用 numpy.copy 方法复制数组,否则该变量将成为原始数组的视图。请看以下示例:
>>> import numpy as np
>>> a = np.array([1, 2, 3, 4, 5, 6])
>>> b = a[:2]
>>> b += 1
>>> print('a =', a, '; b =', b) a = [2 3 3 4 5 6] ; b = [2 3]
在这个示例中,您并没有创建新数组。您创建了一个变量b,它指向数组a的前两个元素。当您对b加1时,效果等同于直接对a[:2]加1。
如果需要创建全新数组,请使用numpy.copy数组创建例程,如下所示:
>>> import numpy as np
>>> a = np.array([1, 2, 3, 4])
>>> b = a[:2].copy()
>>> b += 1
>>> print('a = ', a, 'b = ', b) a = [1 2 3 4] b = [2 3]
如需更多信息和示例,请参阅副本与视图。
现有多种用于连接数组的例程,例如 numpy.vstack、numpy.hstack 和 numpy.block。以下是一个使用 block 将四个 2x2 数组合并为一个 4x4 数组的示例:
>>> import numpy as np
>>> A = np.ones((2, 2))
>>> B = np.eye(2, 2)
>>> C = np.zeros((2, 2))
>>> D = np.diag((-3, -4))
>>> np.block([[A, B], [C, D]])
array([[ 1., 1., 1., 0.],
[ 1., 1., 0., 1.],
[ 0., 0., -3., 0.],
[ 0., 0., 0., -4.]])
其他例程使用类似的语法来连接 ndarray。更多示例和语法请查阅各例程的文档说明。
4) 从磁盘读取数组(标准或自定义格式)
这是创建大型数组最常见的情况。具体细节很大程度上取决于磁盘上的数据格式。本节将提供处理各种格式的通用指导。如需更详细的IO示例,请参阅如何读写文件。
标准二进制格式
不同领域都有针对数组数据的标准格式。以下列出了已知可以通过Python库读取并返回NumPy数组的格式(可能还存在其他能够读取并转换为NumPy数组的格式,请同时查阅最后一节内容):
注:保持代码块和术语原样,如"NumPy arrays"不翻译
HDF5: h5py
FITS: Astropy
无法直接读取但易于转换的格式示例包括PIL等库支持的格式(能够读写多种图像格式如jpg、png等)。
常见ASCII格式
诸如逗号分隔值(csv)和制表符分隔值(tsv)这类定界文件,常用于Excel和LabView等程序。Python函数可以逐行读取和解析这些文件。NumPy提供了两个标准例程来导入带分隔符的数据文件:numpy.loadtxt和numpy.genfromtxt。这些函数在文件读写中有更复杂的应用场景。以下是一个使用simple.csv的简单示例:
$ cat simple.csv
x, y
0, 0
1, 1
2, 4
3, 9
导入 simple.csv 文件可通过 numpy.loadtxt 实现:
>>> import numpy as np
>>> np.loadtxt('simple.csv', delimiter = ',', skiprows = 1)
array([[0., 0.],
[1., 1.],
[2., 4.],
[3., 9.]])
更通用的ASCII文件可以通过scipy.io和Pandas读取。
5) 通过字符串或缓冲区从原始字节创建数组
有多种方法可供选择。如果文件格式相对简单,可以编写一个简单的I/O库,并使用NumPy的fromfile()函数和.tofile()方法直接读写NumPy数组(但要注意字节顺序!)。如果已有现成的C或C++库能够读取数据,可以通过多种技术封装该库,不过这显然需要更多工作量,并且需要更高级的知识来实现与C或C++的交互。
6) 使用特殊库函数(如SciPy、pandas和OpenCV)
NumPy是Python科学计算栈中数组容器的核心基础库。包括SciPy、Pandas和OpenCV在内的许多Python库,都将NumPy的ndarray作为数据交换的通用格式。这些库能够创建、操作并处理NumPy数组。
在 ndarrays 上进行索引
https://numpy.org/doc/stable/user/basics.indexing.html
另请参阅:索引例程
ndarrays 可以使用标准的 Python x[obj] 语法进行索引,其中 x 是数组,obj 是选择项。根据 obj 的不同,有以下几种索引类型:基本索引、高级索引和字段访问。
以下大多数示例展示了在引用数组数据时使用索引的情况。这些示例同样适用于对数组进行赋值操作。具体示例和关于赋值工作原理的解释,请参阅为索引数组赋值。
请注意,在 Python 中,x[(exp1, exp2, ..., expN)] 等价于 x[exp1, exp2, ..., expN];后者只是前者的语法糖。
基础索引
单元素索引
单元素索引的工作方式与其他标准 Python 序列完全相同。它采用基于 0 的索引系统,并接受负数索引从数组末尾开始定位。
>>> x = np.arange(10)
>>> x[2]
2
>>> x[-2]
8
无需将每个维度的索引单独放在方括号中。
>>> x.shape = (2, 5) # now x is 2-dimensional
>>> x[1, 3]
8
>>> x[1, -1]
9
请注意,如果使用比维度数更少的索引来访问多维数组,将会得到一个子维度数组。例如:
>>> x[0]
array([0, 1, 2, 3, 4])
也就是说,每个指定的索引会选择与其余选定维度相对应的数组。在上面的例子中,选择0意味着长度为5的剩余维度未被指定,返回的是具有该维度和大小的数组。
需要注意的是,返回的数组是一个视图,也就是说,它不是原始数组的副本,而是指向与原始数组相同的内存值。
在这种情况下,会返回第一个位置(0)的一维数组。
因此,对返回的数组使用单个索引,将返回单个元素。即:
>>> x[0][2]
2
请注意,x[0, 2] == x[0][2],但第二种方式的效率较低,因为在第一次索引后会创建一个新的临时数组,随后再用2进行索引。
注意:NumPy采用C语言风格的索引顺序。这意味着最后一个索引通常代表内存中变化最快的位置,这与Fortran或IDL不同,后者的第一个索引代表内存中变化最快的位置。这种差异可能导致严重的混淆。
切片与步进
基础切片将 Python 的基本切片概念扩展到了 N 维。当 obj 是 slice 对象(通过括号内的 start:stop:step 表示法构造)、整数或由切片对象与整数组成的元组时,就会发生基础切片。此外,Ellipsis 和 newaxis 对象也可以穿插其中。
使用 N 个整数进行索引的最简单情况会返回一个表示对应项的数组标量。与 Python 一样,所有索引从零开始:对于第 i 个索引 \(n_i),其有效范围是 \(0 \le n_i < d_i),其中 \(d_i) 是数组形状的第 i 个元素。负数索引会被解释为从数组末尾开始计数(即如果 \(n_i < 0),则表示 \(n_i + d_i))。
通过基础切片生成的所有数组始终是原始数组的视图。
注意:NumPy 切片会创建视图,而不是像 Python 内置序列(如字符串、元组和列表)那样创建副本。从大型数组中提取一小部分时需要特别小心,因为提取后的大数组可能变得无用,但提取的小部分仍包含对原始大数组的引用,其内存直到所有派生数组被垃圾回收后才会释放。在这种情况下,建议显式使用 copy()。
序列切片的标准规则适用于每个维度上的基础切片(包括使用步进索引)。以下是一些需要记住的有用概念:
- 基础切片语法为
i:j:k,其中 i 是起始索引,j 是停止索引,k 是步长(\(k\neq0))。这会选择对应维度上索引值为 i、i + k、…、i + (m - 1) k 的 m 个元素,其中 \(m = q + (r\neq0)),q 和 r 是通过将 j - i 除以 k 得到的商和余数:j - i = q k + r,因此 i + (m - 1) k < j。
例如:
>>> x = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> x[1:7:2]
array([1, 3, 5])
- 负数 i 和 j 会被解释为 n + i 和 n + j,其中
n 表示对应维度中的元素数量。 - 负数 k 会使步进方向朝向较小的索引。
从上述示例可以看出:
>>> x[-2:10]
array([8, 9])
>>> x[-3:3:-1]
array([7, 6, 5, 4])
假设 n 是被切片维度中的元素数量。那么:
- 如果未指定 i,则默认值为:当 k > 0 时为 0,当 k < 0 时为 n - 1
- 如果未指定 j,则默认值为:当 k > 0 时为 n,当 k < 0 时为 -n-1
- 如果未指定 k,则默认值为 1
注意::: 等同于 :,表示沿该轴选择所有索引。
根据上述示例:
>>> x[5:]
array([5, 6, 7, 8, 9])
- 如果选择元组中的对象数量小于
N,则后续维度将默认使用 :。
例如:
>>> x = np.array([[[1],[2],[3]], [[4],[5],[6]]])
>>> x.shape
(2, 3, 1)
>>> x[1:2]
array([[[4],
[5],
[6]]])
- 一个整数 i 返回的值与
i:i+1相同
例外情况:返回对象的维度会降低
1、特别地,当选择元组中第 p 个元素为整数(其他所有元素为 :)时,将返回维度为 N - 1 的对应子数组。如果
N
=
1
N = 1
N=1,则返回的对象是一个数组标量。这些对象在标量中有详细说明。
- 如果选择元组中除第 p 个条目是切片对象
i:j:k外,其他条目均为:,则返回的数组维度为 N,由沿第 p 轴堆叠元素 i、i+k、…、i + (m - 1) k < j 的整数索引子数组构成。 - 当切片元组中包含多个非
:条目时,基础切片的行为类似于重复应用单次非:条目的切片操作,其中非:条目依次被处理(其他非:条目替换为:)。因此,x[ind1, ..., ind2,:]在基础切片下的行为类似于x[ind1][..., ind2, :]。
警告:上述情况不适用于高级索引。
- 可以使用切片设置数组中的值,但(与列表不同)无法扩展数组。
x[obj] = value中待设置值的大小必须(可广播为)与x[obj]的形状相同。 - 切片元组始终可以构造为 obj 并用于
x[obj]表示法。在构造过程中,切片对象可替代[start:stop:step]表示法。例如,x[1:10:5, ::-1]也可通过obj = (slice(1, 10, 5), slice(None, None, -1)); x[obj]实现。这对于构建适用于任意维度数组的通用代码非常有用。更多信息请参阅程序中处理可变数量索引。
维度索引工具
提供了一些工具来简化数组形状与表达式及赋值操作的匹配。
Ellipsis 会扩展为所需数量的 : 对象,以使选择元组能够索引所有维度。在大多数情况下,这意味着扩展后的选择元组长度为 x.ndim。一个选择元组中只能出现单个省略号。
从上面的例子可以看出:
>>> x[..., 0]
array([[1, 2, 3], [4, 5, 6]])
这相当于:
>>> x[:, :, 0]
array([[1, 2, 3], [4, 5, 6]])
在选择元组中,每个 newaxis 对象都会将结果选择的维度扩展一个单位长度。新增的维度位置对应于 newaxis 对象在选择元组中的位置。newaxis 是 None 的别名,实际使用时可以用 None 替代,效果相同。
从上面的例子可以看出:
>>> x[:, np.newaxis, :, :].shape
(2, 1, 3, 1)
>>> x[:, None, :, :].shape
(2, 1, 3, 1)
这在某些情况下非常实用,可以将两个数组合并起来,而无需显式地进行重塑操作。例如:
>>> x = np.arange(5)
>>> x[:, np.newaxis] + x[np.newaxis, :]
array([[0, 1, 2, 3, 4], [1, 2, 3, 4, 5], [2, 3, 4, 5, 6], [3, 4, 5, 6, 7], [4, 5, 6, 7, 8]])
高级索引
当选择对象 obj 是以下情况之一时,会触发高级索引:
- 非元组的序列对象
- 数据类型为整数或布尔值的
ndarray - 包含至少一个序列对象或数据类型为整数/布尔值的 ndarray 的元组
高级索引分为两种类型:整数索引和布尔索引。
与返回视图的基本切片不同,高级索引总是返回数据的副本。
警告:高级索引的定义意味着 x[(1, 2, 3),] 与 x[(1, 2, 3)] 有本质区别。后者等价于 x[1, 2, 3] 会触发基本选择,而前者会触发高级索引。务必理解这一差异的原因。
整数数组索引
整数数组索引允许基于元素的N维坐标来选取数组中的任意项。每个整数数组代表该维度上的一组索引值。
索引数组中允许出现负值,其作用机制与单索引或切片操作中的负值相同:
>>> x = np.arange(10, 1, -1)
>>> x
array([10, 9, 8, 7, 6, 5, 4, 3, 2])
>>> x[np.array([3, 3, 1, 8])]
array([7, 7, 9, 2])
>>> x[np.array([3, 3, -3, 8])]
array([7, 7, 4, 2])
如果索引值超出范围,则会抛出 IndexError 异常:
>>> x = np.array([[1, 2], [3, 4], [5, 6]])
>>> x[np.array([1, -1])]
array([[3, 4], [5, 6]])
>>> x[np.array([3, 4])]
Traceback (most recent call last):
...
IndexError: index 3 is out of bounds for axis 0 with size 3
当索引由与数组维度数量相同的整数数组组成时,索引操作虽然直接明了,但与切片操作有所不同。
高级索引总是会进行广播并作为一个整体进行迭代:
result[i_1,
..., i_M] == x[ind_1[i_1,
..., i_M], ind_2[i_1,
..., i_M],
..., ind_N[i_1,
..., i_M]]
请注意,最终生成的形状与(广播后的)索引数组形状 ind_1, ..., ind_N 完全一致。如果这些索引无法广播为相同形状,系统会抛出异常 IndexError: shape mismatch: indexing arrays could not be broadcast together with shapes...。
使用多维索引数组进行索引的情况较为少见,但这是被允许的,并且对某些特定问题非常有用。我们将从最简单的多维情况开始讲解:
>>> y = np.arange(35).reshape(5, 7)
>>> y
array([[ 0, 1, 2, 3, 4, 5, 6],
[ 7, 8, 9, 10, 11, 12, 13],
[14, 15, 16, 17, 18, 19, 20],
[21, 22, 23, 24, 25, 26, 27],
[28, 29, 30, 31, 32, 33, 34]])
>>> y[np.array([0, 2, 4]), np.array([0, 1, 2])]
array([ 0, 15, 30])
在这种情况下,如果索引数组具有匹配的形状,并且对于被索引数组的每个维度都有一个索引数组,那么结果数组的形状将与索引数组相同,其值对应于索引数组中每个位置所指向的索引集合。在本例中,两个索引数组的第一个索引值都是0,因此结果数组的第一个值为y[0, 0]。下一个值是y[2, 1],最后一个是y[4, 2]。
如果索引数组的形状不相同,系统会尝试将它们广播为相同形状。若无法广播为相同形状,则会抛出异常:
>>> y[np.array([0, 2, 4]), np.array([0, 1])]
Traceback (most recent call last):
...
IndexError: shape mismatch: indexing arrays could not be broadcast
together with shapes (3,) (2,)
广播机制允许索引数组与其他索引的标量值结合使用。其效果是将标量值应用于索引数组的所有对应位置:
>>> y[np.array([0, 2, 4]), 1]
array([ 1, 15, 29])
在提升到下一个复杂度层级时,我们可以仅用索引数组对数组进行部分索引。理解这类情况下的运作机制需要稍加思考。例如,当我们仅对 y 使用单个索引数组时:
>>> y[np.array([0, 2, 4])]
array([[ 0, 1, 2, 3, 4, 5, 6],
[14, 15, 16, 17, 18, 19, 20],
[28, 29, 30, 31, 32, 33, 34]])
这将构建一个新数组,其中索引数组的每个值从被索引的数组中选取一行,最终生成的数组形状为(索引元素数量,行大小)。
通常,结果数组的形状将是索引数组形状(或所有索引数组广播后的形状)与被索引数组中未使用维度(未被索引的维度)形状的串联。
示例:
需要从每一行中选择特定元素。行索引为[0, 1, 2],列索引指定了对应行要选取的元素,此处为[0, 1, 0]。结合使用两者,可以通过高级索引解决该任务:
>>> x = np.array([[1, 2], [3, 4], [5, 6]])
>>> x[[0, 1, 2], [0, 1, 0]]
array([1, 4, 5])
要实现类似于上述基础切片的行为,可以使用广播机制。函数 ix_ 可辅助实现这种广播操作,通过示例能更直观地理解其用法。
示例:
假设需要从一个4x3数组中通过高级索引选取角落元素,即选择所有满足列号为[0, 2]且行号为[0, 3]的元素。使用高级索引时,必须显式地选择所有目标元素。根据前文介绍的方法,可以这样实现:
>>> x = np.array([[ 0, 1, 2],
...
[ 3, 4, 5],
...
[ 6, 7, 8],
...
[ 9, 10, 11]])
>>> rows = np.array([[0, 0],
... [3, 3]], dtype=np.intp)
>>> columns = np.array([[0, 2],
... [0, 2]], dtype=np.intp)
>>> x[rows, columns]
array([[ 0, 2],
[ 9, 11]])
然而,由于上述索引数组只是不断重复自身,因此可以利用广播机制(对比类似rows[:, np.newaxis] + columns的操作)来简化这一过程:
>>> rows = np.array([0, 3], dtype=np.intp)
>>> columns = np.array([0, 2], dtype=np.intp)
>>> rows[:, np.newaxis]
array([[0],
[3]])
>>> x[rows[:, np.newaxis], columns]
array([[ 0, 2],
[ 9, 11]])
这种广播操作也可以通过 ix_ 函数实现:
>>> x[np.ix_(rows, columns)]
array([[ 0, 2],
[ 9, 11]])
请注意,如果不调用 np.ix_,则只会选择对角线元素:
>>> x[rows, columns]
array([ 0, 11])
关于使用多个高级索引进行索引时,最需要记住的关键区别在于:
示例:
高级索引在实际应用中的一个典型场景是颜色查找表。假设我们需要将图像中的像素值映射为用于显示的RGB三元组。查找表可能具有(nlookup, 3)的形状。当使用dtype=np.uint8(或任何整型,只要值在查找表范围内)的形状为(ny, nx)的图像来索引这个数组时,将得到一个形状为(ny, nx, 3)的数组,其中每个像素位置都关联着一个RGB三元组。
布尔数组索引
当 obj 是一个布尔类型的数组对象时(例如通过比较运算符返回的结果),就会发生这种高级索引操作。单个布尔索引数组实际上等同于 x[obj.nonzero()],如上所述,obj.nonzero() 会返回一个由整数索引数组组成的元组(长度为 obj.ndim),这些数组标明了 obj 中 True 元素的位置。不过当 obj.shape == x.shape 时,这种操作会更快。
如果 obj.ndim == x.ndim,x[obj] 会返回一个一维数组,其中填充了 x 中与 obj 的 True 值对应的元素。搜索顺序将按照 行优先 的 C 语言风格进行。如果 obj 的形状与 x 的对应维度不匹配,无论这些值是 True 还是 False,都会引发索引错误。
这种索引的一个常见用途是筛选所需的元素值。例如,可能需要从一个数组中选出所有不是 numpy.nan 的条目:
>>> x = np.array([[1., 2.], [np.nan, 3.], [np.nan, np.nan]])
>>> x[~np.isnan(x)]
array([1., 2., 3.])
或者希望对所有负元素添加一个常量:
>>> x = np.array([1., -1., -2., 3])
>>> x[x < 0] += 20
>>> x
array([ 1., 19., 18., 3.])
通常情况下,如果一个索引包含布尔数组,其结果等同于将 obj.nonzero() 插入相同位置并使用前文描述的整数数组索引机制。
x[ind_1, boolean_array, ind_2] 等价于 x[(ind_1,) + boolean_array.nonzero() + (ind_2,)]。
当仅存在一个布尔数组且没有整数索引数组时,操作较为直接。唯一需要注意的是确保布尔索引的维度数量严格匹配其预期操作的维度数。
一般来说,当布尔数组的维度少于被索引数组时,这等价于 x[b, ...],表示 x 由 b 索引后补充足够数量的 : 以填满 x 的秩。因此结果的形状包含两个部分:第一个维度是布尔数组中 True 元素的数量,其后跟随被索引数组剩余的维度。
>>> x = np.arange(35).reshape(5, 7)
>>> b = x > 20
>>> b[:, 5]
array([False, False, False, True, True])
>>> x[b[:, 5]]
array([[21, 22, 23, 24, 25, 26, 27], [28, 29, 30, 31, 32, 33, 34]])
这里从索引数组中选择了第4和第5行,并组合成一个二维数组。
示例:
从一个数组中,选出所有行之和小于或等于2的行:
>>> x = np.array([[0, 1], [1, 1], [2, 2]])
>>> rowsum = x.sum(-1)
>>> x[rowsum <= 2, :]
array([[0, 1],
[1, 1]])
结合多个布尔索引数组或将布尔值与整数索引数组结合使用时,通过类比 obj.nonzero() 函数可以更好地理解其原理。函数 ix_ 同样支持布尔数组,并能稳定运行不产生意外结果。
示例:
使用布尔索引筛选所有行总和为偶数的行,同时通过高级整数索引选择第0列和第2列。借助 ix_ 函数,可按如下方式实现:
>>> x = np.array([[ 0, 1, 2],
...
[ 3, 4, 5],
...
[ 6, 7, 8],
...
[ 9, 10, 11]])
>>> rows = (x.sum(-1) % 2) == 0
>>> rows
array([False, True, False, True])
>>> columns = [0, 2]
>>> x[np.ix_(rows, columns)]
array([[ 3, 5],
[ 9, 11]])
如果不使用 np.ix_ 调用,则只会选中对角线元素。
或者不使用 np.ix_(与整数数组示例对比):
>>> rows = rows.nonzero()[0]
>>> x[rows[:, np.newaxis], columns]
array([[ 3, 5],
[ 9, 11]])
示例:
使用形状为 (2, 3) 的二维布尔数组(包含四个 True 元素)从形状为 (2, 3, 5) 的三维数组中筛选行,最终会得到一个形状为 (4, 5) 的二维结果数组:
>>> x = np.arange(30).reshape(2, 3, 5)
>>> x
array([[[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]], [[15, 16, 17, 18, 19],
[20, 21, 22, 23, 24],
[25, 26, 27, 28, 29]]])
>>> b = np.array([[True, True, False], [False, True, True]])
>>> x[b]
array([[ 0, 1, 2, 3, 4], [ 5, 6, 7, 8, 9], [20, 21, 22, 23, 24], [25, 26, 27, 28, 29]])
高级索引与基础索引的结合使用
当索引中至少包含一个切片(:)、省略号(...)或 newaxis(或者数组的维度多于高级索引的数量时),其行为可能会更加复杂。这类似于将每个高级索引元素的索引结果进行拼接。
在最简单的情况下,只有一个单独的高级索引与切片结合使用。例如:
>>> y = np.arange(35).reshape(5,7)
>>> y[np.array([0, 2, 4]), 1:3]
array([[ 1, 2],
[15, 16],
[29, 30]])
实际上,切片操作和索引数组操作是相互独立的。切片操作会提取索引为1和2的列(即第2和第3列),随后索引数组操作会提取索引为0、2和4的行(即第1、第3和第5行)。这等价于:
>>> y[:, 1:3][np.array([0, 2, 4]), :]
array([[ 1, 2],
[15, 16],
[29, 30]])
例如,一个高级索引可以替代切片,结果数组将是相同的。但这是一个副本,可能具有不同的内存布局。在可能的情况下,优先使用切片。
例如:
>>> x = np.array([[ 0, 1, 2],
...
[ 3, 4, 5],
...
[ 6, 7, 8],
...
[ 9, 10, 11]])
>>> x[1:2, 1:3]
array([[4, 5]])
>>> x[1:2, [1, 2]]
array([[4, 5]])
理解多重高级索引组合的最简单方式可能是从结果形状的角度思考。索引操作包含两个部分:由基础索引(不包括整数)定义的子空间和来自高级索引部分的子空间。需要区分两种索引组合情况:
- 高级索引之间被切片、
Ellipsis或newaxis分隔。例如x[arr1, :, arr2]。 - 所有高级索引彼此相邻。例如
x[..., arr1, arr2, :],但不包括x[arr1, :, 1],因为此处的1被视为高级索引。
第一种情况下,高级索引操作产生的维度会出现在结果数组的开头,子空间维度紧随其后。
第二种情况下,高级索引操作产生的维度会被插入到结果数组中与原始数组相同的位置(后者的逻辑使得简单高级索引的行为与切片一致)。
示例:
假设x.shape为(10,20,30),ind是一个形状为(2,5,2)的索引intp数组,那么result = x[..., ind, :]的形状将是(10,2,5,2,30),因为(20,)形状的子空间已被广播为(2,5,2)形状的索引子空间。如果让i,j,k遍历(2,5,2)形状的子空间,那么result[..., i,j,k,:] = x[..., ind[i,j,k], :]。此示例产生的结果与x.take(ind, axis=-2)相同。
示例:
设x.shape为(10,20,30,40,50),假设ind_1和ind_2可广播为(2,3,4)形状。那么x[:, ind_1, ind_2]的形状将是(10,2,3,4,40,50),因为X中(20,30)形状的子空间已被索引的(2,3,4)子空间替代。然而x[:, ind_1, :, ind_2]的形状是(2,3,4,10,30,50),因为没有明确位置插入索引子空间,因此被附加到开头。始终可以使用.transpose()将子空间移动到所需位置。注意此示例无法通过take复现。
示例:
切片可与广播的布尔索引结合使用:
>>> x = np.arange(35).reshape(5, 7)
>>> b = x > 20
>>> b
array([[False, False, False, False, False, False, False], [False, False, False, False, False, False, False], [False, False, False, False, False, False, False], [ True, True, True, True, True, True, True], [ True, True, True, True, True, True, True]])
>>> x[b[:, 5], 1:3]
array([[22, 23], [29, 30]])
字段访问
另请参阅:结构化数组
如果 ndarray 对象是结构化数组,则可以通过字符串字典式索引来访问数组的字段。
索引操作 x['field-name'] 会返回数组的一个新视图,该视图与 x 形状相同(除非字段是子数组),但数据类型为 x.dtype['field-name'],并且仅包含指定字段的数据部分。此外,记录数组标量也可以通过这种方式进行“索引”。
结构化数组的索引操作还可以使用字段名列表,例如 x[['field-name1', 'field-name2']]。从 NumPy 1.16 开始,这会返回一个仅包含这些字段的视图。在旧版本的 NumPy 中,它会返回一个副本。有关多字段索引的更多信息,请参阅用户指南中的结构化数组部分。
如果访问的字段是子数组,则子数组的维度会被附加到结果的形状中。
例如:
>>> x = np.zeros((2, 2), dtype=[('a', np.int32), ('b', np.float64, (3, 3))])
>>> x['a'].shape
(2, 2)
>>> x['a'].dtype
dtype('int32')
>>> x['b'].shape
(2, 2, 3, 3)
>>> x['b'].dtype
dtype('float64')
扁平迭代器索引
x.flat 返回一个能遍历整个数组的迭代器(按C语言连续存储风格,最后一个索引变化最快)。只要选择对象不是元组,该迭代器对象同样支持基础切片或高级索引操作。这一点从x.flat是一维视图的事实中可以明确看出。它可用于通过一维C风格扁平索引进行整数索引,因此返回数组的形状始终与整数索引对象的形状一致。
为索引数组赋值
如前所述,可以通过单一索引、切片、索引数组和掩码数组来选择数组的子集进行赋值。被赋值到索引数组的值必须满足形状一致性要求(即与索引产生的形状相同,或可广播为该形状)。例如,允许将常量赋值给切片:
>>> x = np.arange(10)
>>> x[2:7] = 1
或者一个大小合适的数组:
>>> x[2:7] = np.arange(5)
请注意,赋值操作可能会导致以下情况发生改变:将高精度类型赋给低精度类型(例如将浮点数赋给整数),甚至可能引发异常(例如将复数赋给浮点数或整数)。
>>> x[1] = 1.2
>>> x[1]
1
>>> x[1] = 1.2j
Traceback (most recent call last):
...
TypeError: can't convert complex to int
与某些引用(如数组和掩码索引)不同,赋值操作总是直接作用于数组中的原始数据(事实上,其他任何方式都没有意义!)。但需注意,某些操作可能不会如人们直观预期那样工作。以下这个典型例子常常让人感到意外:
>>> x = np.arange(0, 50, 10)
>>> x
array([ 0, 10, 20, 30, 40])
>>> x[np.array([1, 1, 3, 1])] += 1
>>> x
array([ 0, 11, 20, 31, 40])
人们预期第一个位置的值会增加3,但实际上只会增加1。原因是系统会从原数组中提取一个临时新数组(包含位置1、1、3、1的值),然后对这个临时数组中的值1进行加1操作,最后再将临时数组重新赋值给原数组。因此,x[1] + 1的结果会被赋值给x[1]三次,而不是对x[1]进行三次递增操作。
在程序中处理可变数量的索引
索引语法虽然功能强大,但在处理可变数量索引时会受到限制。例如,如果您想编写一个函数,能够处理不同维度的参数,而不必为每种可能的维度编写特殊情况的代码,该如何实现?
当向索引提供一个元组时,该元组将被解释为索引列表。例如:
>>> z = np.arange(81).reshape(3, 3, 3, 3)
>>> indices = (1, 1, 1, 1)
>>> z[indices]
40
可以使用代码构建任意数量索引的元组,然后在索引中使用这些元组。
在程序中可以通过Python的slice()函数来指定切片。例如:
>>> indices = (1, 1, 1, slice(0, 2)) # same as [1, 1, 1, 0:2]
>>> z[indices]
array([39, 40])
同样,也可以通过使用 Ellipsis 对象来用代码指定省略号:
>>> indices = (1, Ellipsis, 1) # same as [1,
..., 1]
>>> z[indices]
array([[28, 31, 34],
[37, 40, 43],
[46, 49, 52]])
因此,可以直接将 np.nonzero() 函数的输出用作索引,因为该函数总是返回一个由索引数组组成的元组。
由于元组的特殊处理方式,它们不会像列表那样被自动转换为数组。例如:
>>> z[[1, 1, 1, 1]] # produces a large array
array([[[[27, 28, 29],
[30, 31, 32],
...
>>> z[(1, 1, 1, 1)] # returns a single value
40
详细说明
以下是一些详细说明,这些内容在日常索引操作中并不重要(无特定顺序):
- NumPy的原生索引类型是
intp,可能与默认整数数组类型不同。intp是能够安全索引任何数组的最小数据类型;在高级索引操作中,它可能比其他类型更快。 - 对于高级赋值操作,通常无法保证迭代顺序。这意味着如果一个元素被多次设置,最终结果将不可预测。
- 空(元组)索引是对零维数组的完整标量索引。
x[()]在x为零维时返回一个标量,否则返回视图。而x[...]总是返回视图。 - 如果索引中包含零维数组且是完整整数索引,结果将是标量而非零维数组(不会触发高级索引)。
- 当省略号(
...)存在但没有指定大小(即替换零个:)时,结果仍将保持为数组。如果没有高级索引则返回视图,否则返回副本。 - 布尔数组的
nonzero等价性不适用于零维布尔数组。 - 当高级索引操作结果为空,但个别索引越界时,是否引发
IndexError是未定义的(例如x[[], [123]]中123越界的情况)。 - 当赋值过程中发生类型转换错误(例如使用字符串序列更新数值数组),被赋值的数组可能处于不可预测的部分更新状态。但如果发生其他错误(如索引越界),数组将保持不变。
- 高级索引结果的内存布局针对每次索引操作进行了优化,不能假定特定的内存顺序。
- 使用子类(特别是那些操作形状的子类)时,默认的
ndarray.__setitem__行为会对基本索引调用__getitem__,但对高级索引不会。对于这类子类,最好使用数据的基础类ndarray视图来调用ndarray.__setitem__。如果子类的__getitem__不返回视图,则必须这样做。
NumPy 的输入输出操作
https://numpy.org/doc/stable/user/basics.io.html
使用 genfromtxt 导入数据
https://numpy.org/doc/stable/user/basics.io.genfromtxt.html
NumPy 提供了多个从表格数据创建数组的函数。这里我们重点介绍 genfromtxt 函数。
简而言之,genfromtxt 会运行两个主要循环:
1、第一个循环将文件的每一行转换为字符串序列
2、第二个循环将每个字符串转换为适当的数据类型
这种机制虽然比单循环慢,但提供了更大的灵活性。特别是 genfromtxt 能够处理缺失数据,而像 loadtxt 这样更快更简单的函数则无法做到。
注意:在给出示例时,我们将遵循以下约定:
>>> import numpy as np
>>> from io import StringIO
定义输入
genfromtxt 唯一必需的参数是数据源。它可以是字符串、字符串列表、生成器或具有 read 方法的类文件对象(例如文件或 io.StringIO 对象)。如果提供单个字符串,则假定为本地或远程文件的名称。如果提供字符串列表或返回字符串的生成器,则每个字符串被视为文件中的一行。当传入远程文件的 URL 时,文件会自动下载到当前目录并打开。
支持识别的文件类型包括文本文件和压缩文件。目前该函数支持识别 gzip 和 bz2(bzip2)压缩文件。压缩文件类型通过文件扩展名确定:如果文件名以 '.gz' 结尾,则视为 gzip 压缩文件;如果以 'bz2' 结尾,则视为 bzip2 压缩文件。
将行拆分为列
delimiter 参数
当文件定义并打开以供读取后,genfromtxt 会将每个非空行拆分为字符串序列。空行或注释行会被直接跳过。delimiter 关键字用于定义拆分方式。
通常情况下,单个字符会标记列之间的分隔。例如,逗号分隔文件(CSV)使用逗号(,)或分号(;)作为分隔符:
>>> data = "1, 2, 3\n4, 5, 6"
>>> np.genfromtxt(StringIO(data), delimiter=",")
array([[1., 2., 3.],
[4., 5., 6.]])
另一个常见的分隔符是"\t"(制表符)。但我们不仅限于单个字符,任何字符串都可以作为分隔符。默认情况下,genfromtxt假定delimiter=None,这意味着按空白字符(包括制表符)分割行,并且连续的空白字符会被视为单个空白字符。
此外,我们可能处理的是固定宽度的文件,其中列被定义为特定数量的字符。在这种情况下,我们需要将delimiter设置为单个整数(如果所有列的宽度相同)或整数序列(如果列的宽度可以不同):
>>> data = " 1 2 3\n 4 5 67\n890123 4"
>>> np.genfromtxt(StringIO(data), delimiter=3)
array([[ 1., 2., 3.],
[ 4., 5., 67.],
[890., 123., 4.]])
>>> data = "123456789\n 4 7 9\n 4567 9"
>>> np.genfromtxt(StringIO(data), delimiter=(4, 3, 2))
array([[1234., 567., 89.],
[ 4., 7., 9.],
[ 4., 567., 9.]])
autostrip 参数
默认情况下,当一行文本被分解为多个字符串时,各个条目不会去除首尾的空白字符。可以通过将可选参数 autostrip 设置为 True 来覆盖此行为。
>>> data = "1, abc , 2\n 3, xxx, 4"
>>> # Without autostrip
>>> np.genfromtxt(StringIO(data), delimiter=",", dtype="|U5")
array([['1', ' abc ', ' 2'],
['3', ' xxx', ' 4']], dtype='<U5')
>>> # With autostrip
>>> np.genfromtxt(StringIO(data), delimiter=",", dtype="|U5", autostrip=True)
array([['1', 'abc', '2'],
['3', 'xxx', '4']], dtype='<U5')
comments 参数
可选参数 comments 用于定义标记注释起始位置的字符串。默认情况下,genfromtxt 会假定 comments='#'。注释标记可以出现在行的任意位置,该标记之后的所有字符都会被忽略。
>>> data = """#
... # Skip me !
... # Skip me too !
... 1, 2
... 3, 4
... 5, 6 #This is the third line of the data
... 7, 8
... # And here comes the last line
... 9, 0
... """
>>> np.genfromtxt(StringIO(data), comments="#", delimiter=",")
array([[1., 2.],
[3., 4.],
[5., 6.],
[7., 8.],
[9., 0.]])
版本 1.7.0 新增功能:当 comments 参数设为 None 时,所有行都不会被视为注释行。
注意:此行为有一个重要例外情况:如果指定可选参数 names=True,系统仍会检查第一个注释行以获取名称信息。
跳过行与选择列
skip_header 和 skip_footer 参数
文件中存在表头可能会妨碍数据处理。此时,我们需要使用可选的 skip_header 参数。该参数的值必须是一个整数,表示在文件开头跳过的行数(在执行其他操作之前)。类似地,我们可以通过使用 skip_footer 属性并赋予其值 n 来跳过文件的最后 n 行。
>>> data = "\n".join(str(i) for i in range(10))
>>> np.genfromtxt(StringIO(data),)
array([0., 1., 2., 3., 4., 5., 6., 7., 8., 9.])
>>> np.genfromtxt(StringIO(data),
... skip_header=3, skip_footer=5)
array([3., 4.])
默认情况下,skip_header=0 且 skip_footer=0,表示不会跳过任何行。
usecols 参数
在某些情况下,我们并不需要导入数据的所有列,而只关注其中的几列。这时可以使用 usecols 参数来选择要导入的列。该参数接受一个整数或整数序列,对应要导入列的索引位置。
请注意:
- 按照惯例,第一列的索引为 0
- 负整数的行为与常规 Python 负索引一致
例如,若只需导入第一列和最后一列,可以使用:usecols=(0, -1)
>>> data = "1 2 3\n4 5 6"
>>> np.genfromtxt(StringIO(data), usecols=(0, -1))
array([[1., 3.],
[4., 6.]])
如果列有名称,我们还可以通过向usecols参数提供列名来选择要导入的列,列名可以是一个字符串序列或以逗号分隔的字符串:
>>> data = "1 2 3\n4 5 6"
>>> np.genfromtxt(StringIO(data),
... names="a, b, c", usecols=("a", "c"))
array([(1., 3.), (4., 6.)], dtype=[('a', '<f8'), ('c', '<f8')])
>>> np.genfromtxt(StringIO(data),
... names="a, b, c", usecols=("a, c"))
array([(1., 3.), (4., 6.)], dtype=[('a', '<f8'), ('c', '<f8')])
选择数据类型
控制从文件读取的字符串序列如何转换为其他类型的主要方式是通过设置 dtype 参数。该参数可接受以下值:
- 单一类型,例如
dtype=float。输出将是具有指定 dtype 的二维数组,除非使用names参数为每列关联了名称(详见下文)。注意dtype=float是genfromtxt的默认值。 - 类型序列,例如
dtype=(int, float, float)。 - 逗号分隔的字符串,例如
dtype="i4,f8,|U3"。 - 包含两个键
'names'和'formats'的字典。 - 元组序列
(name, type),例如dtype=[('A', int), ('B', float)]。 - 现有的
numpy.dtype对象。 - 特殊值
None。此时列的类型将由数据本身决定(详见下文)。
除第一种情况外,其他所有情况的输出都将是一个具有结构化 dtype 的一维数组。该 dtype 的字段数与序列中的项数相同,字段名通过 names 关键字定义。
当 dtype=None 时,每列的类型将通过迭代其数据来确定。首先检查字符串是否可以转换为布尔值(即字符串是否匹配小写的 true 或 false);然后检查是否可以转换为整数,接着是浮点数,然后是复数,最后是字符串。
提供 dtype=None 选项是为了方便,但它的速度明显比显式设置 dtype 慢得多。
设置名称
names参数
在处理表格数据时,一种自然的做法是为每列分配名称。第一种方式是使用显式的结构化dtype,如前所述:
>>> data = StringIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=[(_, int) for _ in "abc"])
array([(1, 2, 3), (4, 5, 6)],
dtype=[('a', '<i8'), ('b', '<i8'), ('c', '<i8')])
另一种更简单的选择是使用names关键字配合字符串序列或逗号分隔的字符串:
>>> data = StringIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, names="A, B, C")
array([(1., 2., 3.), (4., 5., 6.)],
dtype=[('A', '<f8'), ('B', '<f8'), ('C', '<f8')])
在上面的示例中,我们利用了默认情况下 dtype=float 的特性。
通过提供一系列名称,我们强制将输出转换为结构化数据类型。
有时可能需要从数据本身定义列名。这种情况下,必须使用值为 True 的 names 关键字。此时列名会从第一行读取(跳过 skip_header 指定的行数),即使该行是被注释掉的也不例外:
>>> data = StringIO("So it goes\n#a b c\n1 2 3\n 4 5 6")
>>> np.genfromtxt(data, skip_header=1, names=True)
array([(1., 2., 3.), (4., 5., 6.)],
dtype=[('a', '<f8'), ('b', '<f8'), ('c', '<f8')])
names 的默认值为 None。如果为该关键字指定其他值,新名称将覆盖我们可能已通过 dtype 定义的字段名称。
>>> data = StringIO("1 2 3\n 4 5 6")
>>> ndtype=[('a',int), ('b', float), ('c', int)]
>>> names = ["A", "B", "C"]
>>> np.genfromtxt(data, names=names, dtype=ndtype)
array([(1, 2., 3), (4, 5., 6)],
dtype=[('A', '<i8'), ('B', '<f8'), ('C', '<i8')])
defaultfmt 参数
当 names=None 但需要结构化数据类型时,系统会使用 NumPy 的标准默认命名规则 "f%i" 来定义名称,生成类似 f0、f1 这样的字段名。
>>> data = StringIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int))
array([(1, 2., 3), (4, 5., 6)],
dtype=[('f0', '<i8'), ('f1', '<f8'), ('f2', '<i8')])
同样地,如果我们提供的名称数量不足以匹配 dtype 的长度,缺失的名称将使用以下默认模板定义:
>>> data = StringIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int), names="a")
array([(1, 2., 3), (4, 5., 6)],
dtype=[('a', '<i8'), ('f0', '<f8'), ('f1', '<i8')])
我们可以通过 defaultfmt 参数覆盖这个默认值,该参数接受任何格式字符串。
>>> data = StringIO("1 2 3\n 4 5 6")
>>> np.genfromtxt(data, dtype=(int, float, int), defaultfmt="var_%02i")
array([(1, 2., 3), (4, 5., 6)],
dtype=[('var_00', '<i8'), ('var_01', '<f8'), ('var_02', '<i8')])
注意:需要记住的是,defaultfmt 仅在预期某些名称但未定义时才会被使用。
验证名称
具有结构化数据类型的NumPy数组也可以被视为recarray,其中字段可以像属性一样被访问。因此,我们需要确保字段名不包含任何空格或无效字符,也不与标准属性名(如size或shape)相同,否则会干扰解释器。genfromtxt接受三个可选参数,用于更精细地控制名称:
deletechars
提供一个字符串,包含所有必须从名称中删除的字符。默认情况下,无效字符为:
~!@#$%^&*()-=+~|]}[{';: /?.>,<。
excludelist
提供一个需要排除的名称列表,例如return、file、print等。如果输入名称在此列表中,将自动在其后追加下划线字符('_')。
case_sensitive
控制名称是否区分大小写(case_sensitive=True)、转换为大写(case_sensitive=False或case_sensitive='upper')或转换为小写(case_sensitive='lower')。
转换调优
converters 参数
通常情况下,定义 dtype 就足以确定字符串序列应如何转换。但有时可能需要额外的控制。例如,我们可能希望确保格式为 YYYY/MM/DD 的日期被转换为 datetime 对象,或者像 xx% 这样的字符串被正确转换为 0 到 1 之间的浮点数。在这种情况下,我们可以使用 converters 参数来定义转换函数。
该参数的值通常是一个字典,其中键为列索引或列名,值为转换函数。这些转换函数可以是实际函数或 lambda 函数。无论哪种情况,它们都应仅接受字符串作为输入,并输出所需类型的单个元素。
在以下示例中,第二列从表示百分比的字符串转换为 0 到 1 之间的浮点数:
>>> convertfunc = lambda x: float(x.strip("%"))/100、>>> data = "1, 2.3%, 45.\n6, 78.9%, 0"
>>> names = ("i", "p", "n")
>>> # General case .....
>>> np.genfromtxt(StringIO(data), delimiter=",", names=names)
array([(1., nan, 45.), (6., nan, 0.)],
dtype=[('i', '<f8'), ('p', '<f8'), ('n', '<f8')])
需要记住的是,默认情况下 dtype=float。因此第二列预期是浮点类型。然而字符串 ' 2.3%' 和 ' 78.9%' 无法转换为浮点数,最终会得到 np.nan。现在让我们使用一个转换器:
>>> # Converted case ...
>>> np.genfromtxt(StringIO(data), delimiter=",", names=names,
... converters={1: convertfunc})
array([(1., 0.023, 45.), (6., 0.789, 0.)],
dtype=[('i', '<f8'), ('p', '<f8'), ('n', '<f8')])
同样的结果可以通过使用第二列的名称("p")作为键来替代其索引(1)获得:
>>> # Using a name for the converter ...
>>> np.genfromtxt(StringIO(data), delimiter=",", names=names,
... converters={"p": convertfunc})
array([(1., 0.023, 45.), (6., 0.789, 0.)],
dtype=[('i', '<f8'), ('p', '<f8'), ('n', '<f8')])
转换器还可用于为缺失条目提供默认值。在以下示例中,转换器 convert 会将去除空白的字符串转换为对应的浮点数,若字符串为空则返回 -999。
需要注意的是,我们必须显式去除字符串中的空格,因为默认情况下不会自动执行此操作。
>>> data = "1, , 3\n 4, 5, 6"
>>> convert = lambda x: float(x.strip() or -999)
>>> np.genfromtxt(StringIO(data), delimiter=",",
... converters={1: convert})
array([[ 1., -999., 3.],
[ 4., 5., 6.]])
处理缺失值与填充值
在我们尝试导入的数据集中,某些条目可能存在缺失值。在前面的示例中,我们使用转换器将空字符串转换为浮点数。然而,用户自定义的转换器可能很快变得难以管理。
genfromtxt 函数提供了另外两个互补机制:
missing_values参数用于识别缺失数据filling_values参数用于处理这些缺失数据
missing_values
默认情况下,任何空字符串都会被标记为缺失值。我们也可以考虑更复杂的字符串,例如"N/A"或"???"来表示缺失或无效数据。missing_values参数接受三种类型的值:
1、字符串或以逗号分隔的字符串
该字符串将作为所有列的缺失数据标记
2、字符串序列
这种情况下,每个项按顺序与对应列关联
3、字典
字典的值可以是字符串或字符串序列。对应的键可以是列索引(整数)或列名(字符串)。此外,特殊键None可用于定义适用于所有列的默认值。
filling_values
我们知道如何识别缺失数据,但仍需要为这些缺失项提供填充值。默认情况下,该值会根据预期数据类型从下表中确定:
| 预期类型 | 默认值 |
|---|---|
bool | False |
int | -1 |
float | np.nan |
complex | np.nan+0j |
string | '???' |
通过可选参数 filling_values 可以更精细地控制缺失值的转换。与 missing_values 类似,该参数接受多种形式的输入:
- 单个值:将作为所有列的默认填充值
- 值序列:每个元素将作为对应列的默认填充值
- 字典:键可以是列索引或列名,对应的值应为单个对象。可使用特殊键
None为所有列定义默认值
在以下示例中,我们假设第一列的缺失值标记为 "N/A",第三列标记为 "???"。我们的目标是将第一列和第二列出现的缺失值转换为 0,最后一列出现的缺失值转换为 -999:
>>> data = "N/A, 2, 3\n4, ,???"
>>> kwargs = dict(delimiter=",",
...
dtype=int,
... names="a,b,c",
... missing_values={0:"N/A", 'b':" ", 2:"???"},
... filling_values={0:0, 'b':0, 2:-999})
>>> np.genfromtxt(StringIO(data), **kwargs)
array([(0, 2, 3), (4, 0, -999)],
dtype=[('a', '<i8'), ('b', '<i8'), ('c', '<i8')])
usemask
我们可能还需要通过构建布尔掩码来跟踪缺失数据的出现情况,其中True表示数据缺失,False表示数据存在。要实现这一点,只需将可选参数usemask设置为True(默认为False)。这样,输出数组将是一个MaskedArray。
数据类型
https://numpy.org/doc/stable/user/basics.types.html
另请参阅:数据类型对象
数组类型与类型转换
NumPy 支持的数值类型比 Python 更加丰富。本节将介绍可用的数值类型,以及如何修改数组的数据类型。
NumPy 的数值类型都是 numpy.dtype(数据类型)对象的实例,每个类型都有其独特特性。通过 import numpy as np 导入 NumPy 后,您可以使用 NumPy 顶层 API 中的标量类型(如 numpy.bool、numpy.float32 等)来创建指定数据类型的数组。
许多 NumPy 函数或方法都接受 dtype 关键字参数,这些标量类型可以作为参数传入。例如:
>>> z = np.arange(3, dtype=np.uint8)
>>> z
array([0, 1, 2], dtype=uint8)
数组类型也可以通过字符代码来引用,例如:
>>> np.array([1, 2, 3], dtype='f')
array([1., 2., 3.], dtype=float32)
>>> np.array([1, 2, 3], dtype='d')
array([1., 2., 3.], dtype=float64)
请参阅指定和构造数据类型获取关于指定和构造数据类型对象的更多信息,包括如何指定字节顺序等参数。
要转换数组类型,请使用.astype()方法。例如:
>>> z.astype(np.float64)
array([0., 1., 2.])
请注意,在上面的例子中,我们可以使用 Python 的 float 对象作为 dtype,而不必使用 numpy.float64。NumPy 知道:
其他数据类型没有对应的 Python 等效类型。
要确定数组的类型,可以查看 dtype 属性:
>>> z.dtype
dtype('uint8')
dtype对象还包含类型相关信息,如位宽和字节序。该数据类型也可间接用于查询类型属性,例如判断是否为整数类型。
>>> d = np.dtype(np.int64)
>>> d
dtype('int64')
>>> np.issubdtype(d, np.integer)
True
>>> np.issubdtype(d, np.floating)
False
数值数据类型
共有5种基本数值类型,分别表示布尔值(bool)、整数(int)、无符号整数(uint)、浮点数(float)和复数(complex)。基本数值类型名称与数字位宽结合可定义具体类型。位宽是指在内存中表示单个值所需的比特数。例如,numpy.float64是一种64位浮点数据类型。某些类型(如numpy.int_和numpy.intp)的位宽会因平台不同而变化(例如32位与64位CPU架构)。在与低级代码(如C或Fortran)进行交互时,需要特别注意这一点,因为这些代码会直接操作原始内存。
字符串与字节的数据类型
除了数值类型外,NumPy 还支持通过以下方式存储数据:
- Unicode 字符串:使用
numpy.str_数据类型(字符代码U) - 以空字符结尾的字节序列:通过
numpy.bytes_(字符代码S) - 任意字节序列:通过
numpy.void(字符代码V)
以上均为固定宽度数据类型。它们通过宽度参数化,该宽度以字节或 Unicode 点为单位,表示数组中单个数据元素必须适应的空间大小。这意味着,使用此类 dtype 存储字节序列或字符串数组时,需要预先知道或计算最长文本/字节序列的长度。
例如,我们可以创建一个存储单词 "hello" 和 "world!" 的数组:
>>> np.array(["hello", "world!"])
array(['hello', 'world!'], dtype='<U6')
这里检测到的数据类型是一个最大长度为6个码位的Unicode字符串,足以存储这两个条目而不会被截断。如果我们指定更短或更长的数据类型,字符串会根据指定的宽度进行截断或用零填充。
>>> np.array(["hello", "world!"], dtype="U5")
array(['hello', 'world'], dtype='<U5')
>>> np.array(["hello", "world!"], dtype="U7")
array(['hello', 'world!'], dtype='<U7')
如果使用字节数据类型并让NumPy打印出数组缓冲区中的字节,我们能更清楚地看到零填充的情况:
>>> np.array(["hello", "world"], dtype="S7").tobytes()
b'hello\x00\x00world\x00\x00'
每个条目都会填充两个额外的空字节。但需要注意,NumPy无法区分故意存储的末尾空字节和填充用的空字节:
>>> x = [b"hello\0\0", b"world"]
>>> a = np.array(x, dtype="S7")
>>> print(a[0])
b"hello"
>>> a[0] == x[0]
False
如果需要存储并往返传输任何尾随的空字节,您需要使用非结构化的 void 数据类型:
>>> a = np.array(x, dtype="V7")
>>> a
array([b'\x68\x65\x6C\x6C\x6F\x00\x00', b'\x77\x6F\x72\x6C\x64\x00\x00'],
dtype='|V7')
>>> a[0] == np.void(x[0])
True
上面未列出的高级类型将在
结构化数组 部分进行探讨。
NumPy 数据类型与 C 数据类型的对应关系
NumPy 既提供了按位宽命名的类型,也提供了基于 C 类型命名的类型。由于 C 类型的定义与平台相关,因此在编写使用 NumPy 的程序时,应优先选择明确指定位宽的类型,以避免平台依赖性行为。
为了便于与 C 代码集成(在 C 代码中引用平台相关的 C 类型更为自然),NumPy 还提供了与平台 C 类型对应的类型别名。部分 dtype 带有下划线后缀,以避免与 Python 内置类型名称混淆,例如 numpy.bool_。
| 标准 Python API 名称 | Python API “类 C” 名称 | 实际 C 类型 | 描述 |
|---|---|---|---|
numpy.bool 或 numpy.bool_ | 无 | bool (定义于 stdbool.h) | 以字节存储的布尔值(True 或 False) |
numpy.int8 | numpy.byte | signed char | 平台定义的 8 位有符号整数类型 |
numpy.uint8 | numpy.ubyte | unsigned char | 平台定义的 8 位无符号整数类型 |
numpy.int16 | numpy.short | short | 平台定义的 16 位有符号整数类型 |
numpy.uint16 | numpy.ushort | unsigned short | 平台定义的 16 位无符号整数类型 |
numpy.int32 | numpy.intc | int | 平台定义的 32 位有符号整数类型 |
numpy.uint32 | numpy.uintc | unsigned int | 平台定义的 32 位无符号整数类型 |
numpy.intp | 无 | ssize_t/Py_ssize_t | 平台定义的与 size_t 大小相同的有符号整数,常用于表示大小 |
numpy.uintp | 无 | size_t | 平台定义的能存储最大分配大小的无符号整数类型 |
| 无 | 'p' | intptr_t | 保证能存储指针(仅 Python 和 C 的字符代码) |
| 无 | 'P' | uintptr_t | 保证能存储指针(仅 Python 和 C 的字符代码) |
numpy.int32 或 numpy.int64 | numpy.long | long | 平台定义的至少 32 位的有符号整数类型 |
numpy.uint32 或 numpy.uint64 | numpy.ulong | unsigned long | 平台定义的至少 32 位的无符号整数类型 |
| 无 | numpy.longlong | long long | 平台定义的至少 64 位的有符号整数类型 |
| 无 | numpy.ulonglong | unsigned long long | 平台定义的至少 64 位的无符号整数类型 |
numpy.float16 | numpy.half | 无 | 半精度浮点数:符号位 1 位,指数 5 位,尾数 10 位 |
numpy.float32 | numpy.single | float | 平台定义的单精度浮点数:通常符号位 1 位,指数 8 位,尾数 23 位 |
numpy.float64 | numpy.double | double | 平台定义的双精度浮点数:通常符号位 1 位,指数 11 位,尾数 52 位 |
numpy.float96 或 numpy.float128 | numpy.longdouble | long double | 平台定义的扩展精度浮点数 |
numpy.complex64 | numpy.csingle | float complex | 由两个单精度浮点数(实部和虚部)表示的复数 |
numpy.complex128 | numpy.cdouble | double complex | 由两个双精度浮点数(实部和虚部)表示的复数 |
numpy.complex192 或 numpy.complex256 | numpy.clongdouble | long double complex | 由两个扩展精度浮点数(实部和虚部)表示的复数 |
由于许多类型具有平台相关的定义,NumPy 还提供了一组固定大小的别名(参见固定大小别名)。
数组标量
NumPy通常将数组元素作为数组标量返回(带有关联dtype的标量)。数组标量与Python标量不同,但在大多数情况下可以互换使用(主要例外是在Python 2.x之前的版本中,整数数组标量不能作为列表和元组的索引)。存在一些例外情况,例如当代码需要标量的特定属性时,或者专门检查某个值是否为Python标量时。通常,通过使用相应的Python类型函数(如int、float、complex、str)显式将数组标量转换为Python标量,可以轻松解决问题。
使用数组标量的主要优势在于它们保留了数组类型(Python可能没有匹配的标量类型可用,例如int16)。因此,使用数组标量可以确保数组和标量之间的行为一致,无论值是否在数组中。NumPy标量还具有许多与数组相同的方法。
溢出错误
NumPy数值类型的固定大小可能导致溢出错误,当某个值所需内存超过该数据类型可用容量时就会发生。例如,numpy.power 在计算64位整数的100 ** 9时结果正确,但对于32位整数会返回错误值-1486618624。
>>> np.power(100, 9, dtype=np.int64)
1000000000000000000
>>> np.power(100, 9, dtype=np.int32)
np.int32(-1486618624)
NumPy和Python整数类型在整数溢出时的行为差异显著,这可能会让期望NumPy整数表现类似Python int 的用户感到困惑。与NumPy不同,Python int 的大小是灵活的,这意味着Python整数可以扩展以适应任何整数值且不会溢出。
NumPy提供了 numpy.iinfo 和 numpy.finfo 来分别验证NumPy整数和浮点数值的最小值或最大值。
>>> np.iinfo(int) # Bounds of the default integer on this system.
iinfo(min=-9223372036854775808, max=9223372036854775807, dtype=int64)
>>> np.iinfo(np.int32) # Bounds of a 32-bit integer
iinfo(min=-2147483648, max=2147483647, dtype=int32)
>>> np.iinfo(np.int64) # Bounds of a 64-bit integer
iinfo(min=-9223372036854775808, max=9223372036854775807, dtype=int64)
如果64位整数仍然太小,可以将结果转换为浮点数。浮点数提供了更大但不够精确的数值范围。
>>> np.power(100, 100, dtype=np.int64) # Incorrect even with 64-bit int
0
>>> np.power(100, 100, dtype=np.float64)
1e+200
浮点数精度
NumPy中的许多函数,特别是numpy.linalg模块中的函数,都会涉及浮点数运算。由于计算机表示十进制数的方式,这可能会引入微小的误差。例如,在执行涉及浮点数的基本算术运算时:
>>> 0.3 - 0.2 - 0.1 # This does not equal 0 due to floating-point precision
-2.7755575615628914e-17
建议使用像np.isclose这样的函数来比较数值,而不是检查是否完全相等:
>>> np.isclose(0.3 - 0.2 - 0.1, 0, rtol=1e-05) # Check for closeness to 0
True
在这个示例中,np.isclose 通过应用相对容差来处理浮点计算中出现的微小误差,确保将阈值范围内的结果视为近似相等。
有关计算精度的更多信息,请参阅浮点运算。
扩展精度
Python 的浮点数通常是 64 位浮点数,几乎等同于 numpy.float64。在某些特殊情况下,可能需要使用更高精度的浮点数。NumPy 是否支持这种需求取决于硬件和开发环境:具体来说,x86 机器提供 80 位精度的硬件浮点运算,虽然大多数 C 编译器将其作为 long double 类型提供,但 MSVC(Windows 构建的标准编译器)使 long double 等同于 double(64 位)。NumPy 将编译器的 long double 类型提供为 numpy.longdouble(复数版本为 np.clongdouble)。可以通过 np.finfo(np.longdouble) 查看当前 NumPy 提供的精度信息。
NumPy 不提供比 C 的 long double 更高精度的 dtype;特别是,128 位的 IEEE 四倍精度数据类型(FORTRAN 的 REAL*16)不可用。
为了实现高效的内存对齐,numpy.longdouble 通常以零位填充存储,填充至 96 或 128 位。具体哪种方式更高效取决于硬件和开发环境:通常在 32 位系统中填充至 96 位,而在 64 位系统中通常填充至 128 位。np.longdouble 填充至系统默认值;np.float96 和 np.float128 则为需要特定填充的用户提供。尽管名称如此,np.float96 和 np.float128 提供的精度与 np.longdouble 相同,即在大多数 x86 机器上为 80 位,在标准 Windows 构建中为 64 位。
需要注意的是,即使 numpy.longdouble 提供了比 Python float 更高的精度,也很容易丢失这种额外精度,因为 Python 经常强制将值转换为 float。例如,% 格式化运算符要求其参数转换为标准 Python 类型,因此即使请求显示多位小数,也无法保留扩展精度。可以使用 1 + np.finfo(np.longdouble).eps 测试代码是否保留了扩展精度。
广播机制
另请参阅:numpy.broadcast
广播(broadcasting)这一术语描述了NumPy如何处理不同形状数组间的算术运算。在满足特定约束条件下,较小的数组会通过"广播"机制扩展到较大数组的维度,使它们具备兼容的形状。广播机制提供了一种向量化数组操作的方法,从而将循环过程转移到C语言层面而非Python层面实现。这种方式无需创建不必要的数据副本,通常能带来高效的算法实现。但在某些情况下,广播机制可能导致内存使用效率低下,反而会降低计算速度。
NumPy的运算通常基于数组元素逐个对应操作。在最简单的情况下,两个数组必须具有完全相同的形状,如下例所示:
>>> import numpy as np
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = np.array([2.0, 2.0, 2.0])
>>> a * b
array([2., 4., 6.])
NumPy的广播规则在数组形状满足特定条件时会放宽这一限制。最简单的广播示例发生在数组与标量值进行运算时:
>>> import numpy as np
>>> a = np.array([1.0, 2.0, 3.0])
>>> b = 2.0
>>> a * b
array([2., 4., 6.])
结果与之前b是数组的示例等效。
我们可以认为标量b在算术运算过程中被拉伸成一个与a形状相同的数组。如图1所示,b中的新元素只是原始标量的副本。拉伸类比仅是概念上的,NumPy会智能地使用原始标量值而无需实际创建副本,从而使广播操作尽可能节省内存和计算资源。
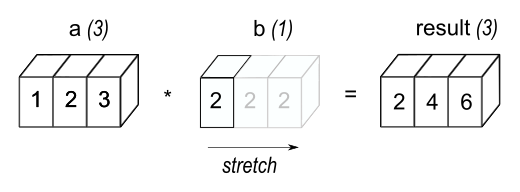
图1:在最简单的广播示例中,标量 b 被拉伸成与 a 形状相同的数组,从而使它们的形状兼容以进行逐元素乘法。
第二个示例中的代码比第一个更高效,因为在乘法过程中广播移动的内存更少(b是标量而非数组)。
通用广播规则
当对两个数组进行操作时,NumPy会逐元素比较它们的形状。它从最末(即最右边)的维度开始,然后向左推进。两个维度在以下情况下是兼容的:
1、它们相等,或者
2、其中一个维度为1。
如果不满足这些条件,就会抛出ValueError: operands could not be broadcast together异常,表明数组的形状不兼容。
输入数组不需要具有相同的维度数量。结果数组的维度数量将与输入数组中维度数量最多的那个相同,其中每个维度的大小是该维度在所有输入数组中的最大值。注意,缺失的维度默认大小为1。
例如,如果你有一个256x256x3的RGB值数组,并且你想用不同的值缩放图像中的每种颜色,你可以将该图像与一个包含3个值的一维数组相乘。根据广播规则对齐这些数组最末轴的大小后,可以看出它们是兼容的:
Image (3d array): 256 x 256 x 3
Scale (1d array): 3
Result (3d array): 256 x 256 x 3
当比较的两个维度中有一个为1时,则采用另一个维度。换句话说,大小为1的维度会被拉伸或"复制"以匹配另一个维度。
在以下示例中,A和B数组都含有长度为1的轴,这些轴在广播操作期间会被扩展至更大的尺寸:
a (4d array): 8 x 1 x 6 x 1
B (3d array): 7 x 1 x 5
Result (4d array): 8 x 7 x 6 x 5
可广播数组
当一组数组能够通过上述规则生成有效结果时,我们称这组数组可"广播"到相同形状。
例如:
- 若
a.shape为 (5,1) b.shape为 (1,6)c.shape为 (6,)d.shape为 ()(即 d 是标量)
那么 a, b, c 和 d 都可广播到维度 (5,6),具体表现为:
- a 的行为类似于 (5,6) 数组,其中
a[:,0]被广播到其他列 - b 的行为类似于 (5,6) 数组,其中
b[0,:]被广播到其他行 - c 的行为类似于 (1,6) 数组,因此也类似于 (5,6) 数组,其中
c[:]被广播到每一行 - d 的行为类似于 (5,6) 数组,其中单个值被重复使用
以下是更多示例:
a (2d array): 5 x 4
B (1d array): 1
Result (2d array): 5 x 4
a (2d array): 5 x 4
B (1d array): 4
Result (2d array): 5 x 4
a (3d array): 15 x 3 x 5
B (3d array): 15 x 1 x 5
Result (3d array): 15 x 3 x 5
a (3d array): 15 x 3 x 5
B (2d array): 3 x 5
Result (3d array): 15 x 3 x 5
a (3d array): 15 x 3 x 5
B (2d array): 3 x 1
Result (3d array): 15 x 3 x 5
以下是不进行广播的形状示例:
a (1d array): 3
B (1d array): 4 # trailing dimensions do not match
a (2d array): 2 x 1
B (3d array): 8 x 4 x 3 # second from last dimensions mismatched
当一维数组与二维数组相加时的广播机制示例:
>>> import numpy as np
>>> a = np.array([[ 0.0, 0.0, 0.0],
... [10.0, 10.0, 10.0],
... [20.0, 20.0, 20.0],
... [30.0, 30.0, 30.0]])
>>> b = np.array([1.0, 2.0, 3.0])
>>> a + b
array([[ 1., 2., 3.],
[11., 12., 13.],
[21., 22., 23.],
[31., 32., 33.]])
>>> b = np.array([1.0, 2.0, 3.0, 4.0])
>>> a + b
Traceback (most recent call last):
ValueError: operands could not be broadcast together with shapes (4,3) (4,)
如图2所示,b被添加到a的每一行。
在图3中,由于形状不兼容而引发了异常。
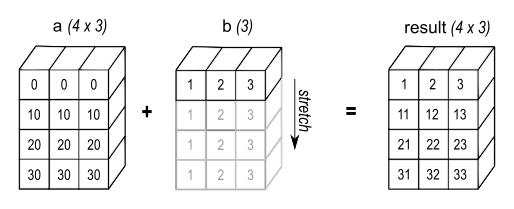
图2:当一维数组的元素数量与二维数组的列数匹配时,一维数组与二维数组相加会产生广播效果。
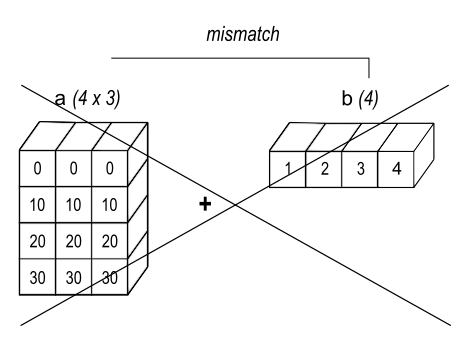
图3:当数组的尾部维度不相等时,广播会失败,因为无法将第一个数组行中的值与第二个数组的元素进行逐元素对齐相加。
广播机制提供了一种便捷的方式来实现两个数组的外积(或任何其他外部运算)。以下示例展示两个一维数组的外部加法运算:
>>> import numpy as np
>>> a = np.array([0.0, 10.0, 20.0, 30.0])
>>> b = np.array([1.0, 2.0, 3.0])
>>> a[:, np.newaxis] + b
array([[ 1., 2., 3.],
[11., 12., 13.],
[21., 22., 23.],
[31., 32., 33.]])
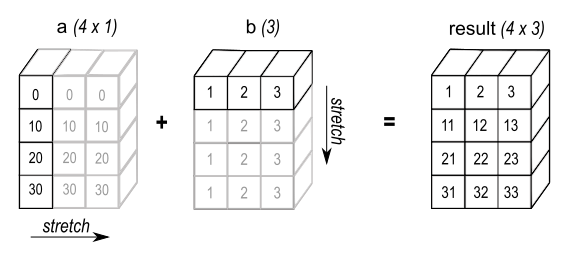
图4:在某些情况下,广播会同时扩展两个数组,形成比初始数组更大的输出数组
这里newaxis索引运算符在a中插入一个新轴,使其成为一个二维的4x1数组。将形状为(4,1)的数组与形状为(3,)的b数组结合,会产生一个4x3的数组。
实际案例:向量量化
广播操作在实际问题中经常出现。一个典型例子是信息论、分类及相关领域中使用的向量量化(VQ)算法。VQ的基本操作是在一组点(VQ术语中称为codes)中找出与给定点(称为observation)最近的点。下面展示的简单二维案例中,observation的值代表待分类运动员的体重和身高,而codes表示不同类别的运动员。[[1]](#f1)
寻找最近点需要计算观测点与每个编码点之间的距离,最短距离代表最佳匹配。在本例中,codes[0]是最接近的类别,表明该运动员很可能是篮球选手。
>>> from numpy import array, argmin, sqrt, sum
>>> observation = array([111.0, 188.0])
>>> codes = array([[102.0, 203.0],
... [132.0, 193.0],
... [45.0, 155.0],
... [57.0, 173.0]])
>>> diff = codes - observation # the broadcast happens here
>>> dist = sqrt(sum(diff**2,axis=-1))
>>> argmin(dist)
0
在这个示例中,observation 数组被扩展以匹配 codes 数组的形状:
Observation (1d array): 2
Codes (2d array): 4 x 2
Diff (2d array): 4 x 2
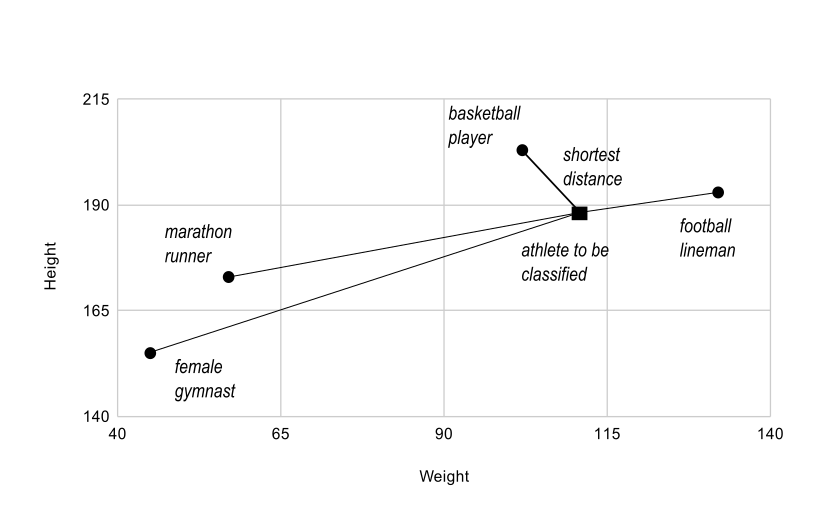
图5:向量量化的基本操作是计算待分类对象(黑色方块)与多个已知编码(灰色圆圈)之间的距离。在这个简单示例中,每个编码代表一个独立类别。更复杂的情况会为每个类别使用多个编码。*
通常会将大量可能从数据库读取的observations与一组codes进行比较。考虑以下场景:
Observation (2d array): 10 x 3
Codes (3d array): 5 x 1 x 3
Diff (3d array): 5 x 10 x 3
三维数组 diff 是广播机制的结果,而非计算所必需。处理大型数据集时会生成庞大的中间数组,导致计算效率低下。相反,如果使用 Python 循环逐个处理观测值(基于上述二维示例中的代码),则只需使用小得多的数组。
广播机制是一种强大工具,能编写出简洁且通常直观的代码,并通过 C 语言高效执行计算。但在某些算法中,广播可能导致内存使用量不必要地激增。此时更适合用 Python 编写算法的外层循环,这样不仅可能提升代码可读性——因为随着广播维度的增加,使用广播的算法往往会变得难以理解。
脚注
[1] 本例中,由于数值量级差异,体重对距离计算的影响远大于身高。实际应用中,通常需要通过数据集的标准差对身高和体重进行归一化处理,使两者对距离计算产生同等影响。
副本与视图
在操作NumPy数组时,可以直接通过视图访问内部数据缓冲区而无需复制数据。这种方式能保证良好的性能,但如果用户不了解其工作原理,也可能导致意外问题。因此,理解这两个术语的区别以及哪些操作返回副本、哪些返回视图非常重要。
NumPy数组是由两部分组成的数据结构:包含实际数据元素的连续数据缓冲区,以及包含数据缓冲区信息的元数据。元数据包括数据类型、步长等信息,这些信息有助于轻松操作ndarray。详情可参阅NumPy数组内部结构章节。
视图
通过仅修改某些元数据(如stride步长和dtype数据类型),而无需更改数据缓冲区,就能以不同方式访问数组。这创建了一种新的数据查看方式,这类新数组被称为视图。由于数据缓冲区保持不变,对视图所做的任何修改都会反映到原始副本中。可以通过ndarray.view方法强制创建视图。
复制
当通过复制数据缓冲区及元数据来创建新数组时,该操作称为复制。对副本所做的修改不会反映到原始数组上。执行复制操作速度较慢且消耗内存,但在某些情况下是必要的。可以通过调用 ndarray.copy 强制进行复制。
索引操作
另请参阅:ndarrays上的索引
当可以通过原始数组的偏移量和步长来访问元素时,就会创建视图。因此,基本索引操作总是会创建视图。例如:
>>> import numpy as np
>>> x = np.arange(10)
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> y = x[1:3] # creates a view
>>> y
array([1, 2])
>>> x[1:3] = [10, 11]
>>> x
array([ 0, 10, 11, 3, 4, 5, 6, 7, 8, 9])
>>> y
array([10, 11])
在这里,当 x 改变时 y 也会随之改变,因为它是一个视图。
而高级索引则总是会创建副本。
例如:
>>> import numpy as np
>>> x = np.arange(9).reshape(3, 3)
>>> x
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> y = x[[1, 2]]
>>> y
array([[3, 4, 5],
[6, 7, 8]])
>>> y.base is None
True
Here, ``y`` is a copy, as signified by the :attr:`base <.ndarray.base>`
attribute. We can also confirm this by assigning new values to ``x[[1, 2]]``
which in turn will not affect ``y`` at all::
>>> x[[1, 2]] = [[10, 11, 12], [13, 14, 15]]
>>> x
array([[ 0, 1, 2],
[10, 11, 12],
[13, 14, 15]])
>>> y
array([[3, 4, 5],
[6, 7, 8]])
必须指出的是,在 x[[1, 2]] 赋值过程中不会创建视图或副本,因为赋值是原地进行的。
其他操作
numpy.reshape 函数会尽可能创建视图(view),否则返回副本。在大多数情况下,可以通过调整步长(strides)来实现数组的原地重塑。但当数组变为非连续存储时(例如执行 ndarray.transpose 操作后),仅修改步长就无法完成重塑,此时必须创建副本。
这种情况下,我们可以通过直接给数组的shape属性赋新值来触发错误。例如:
>>> import numpy as np
>>> x = np.ones((2, 3))
>>> y = x.T # makes the array non-contiguous
>>> y
array([[1., 1.],
[1., 1.],
[1., 1.]])
>>> z = y.view()
>>> z.shape = 6
Traceback (most recent call last):
...
AttributeError: Incompatible shape for in-place modification. Use
`.reshape()` to make a copy with the desired shape.
以另一个操作为例,ravel 会尽可能返回数组的连续扁平化视图。而 ndarray.flatten 总是返回数组的扁平化副本。
不过,若要在大多数情况下确保获得视图,使用 x.reshape(-1) 可能是更好的选择。
如何判断数组是视图还是副本
通过 ndarray 的 base 属性可以轻松判断数组是视图还是副本。视图的 base 属性会返回原始数组,而副本的 base 属性则返回 None。
>>> import numpy as np
>>> x = np.arange(9)
>>> x
array([0, 1, 2, 3, 4, 5, 6, 7, 8])
>>> y = x.reshape(3, 3)
>>> y
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
>>> y.base # .reshape() creates a view
array([0, 1, 2, 3, 4, 5, 6, 7, 8])
>>> z = y[[2, 1]]
>>> z
array([[6, 7, 8],
[3, 4, 5]])
>>> z.base is None # advanced indexing creates a copy
True
请注意,base属性不应被用于判断一个ndarray对象是否是新创建的,而仅应用于判断它是否是另一个ndarray的视图或副本。
处理字符串与字节数组
虽然 NumPy 主要是一个数值计算库,但使用 NumPy 处理字符串或字节数组通常也很方便。最常见的两种使用场景是:
- 处理从数据文件加载或内存映射的数据,其中数据的一个或多个字段是字符串或字节串,且字段的最大长度已知。这种情况通常用于名称或标签字段。
- 对长度未知的 Python 字符串数组使用 NumPy 索引和广播操作,这些数组可能为每个值都定义了数据,也可能没有。
对于第一种使用场景,NumPy 提供了固定宽度的 numpy.void、numpy.str_ 和 numpy.bytes_ 数据类型。对于第二种使用场景,NumPy 提供了 numpy.dtypes.StringDType。下面我们将介绍如何处理固定宽度和可变宽度的字符串数组,如何在两种表示形式之间转换,并提供一些在 NumPy 中高效处理字符串数据的建议。
固定宽度数据类型
在 NumPy 2.0 之前,固定宽度的 numpy.str_、numpy.bytes_ 和 numpy.void 数据类型是 NumPy 中处理字符串和字节串的唯一可用类型。因此,它们分别被用作字符串和字节串的默认 dtype。
>>> np.array(["hello", "world"])
array(['hello', 'world'], dtype='<U5')
此处检测到的数据类型是'<U5',即小端序的 Unicode 字符串数据,最大长度为 5 个 Unicode 码点。
对于字节串(bytestrings)同理:
>>> np.array([b"hello", b"world"])
array([b'hello', b'world'], dtype='|S5')
由于这是一个单字节编码,字节顺序标记为 ‘|’(不适用),检测到的数据类型是最大长度为5个字符的字节串。
你也可以使用 numpy.void 来表示字节串:
>>> np.array([b"hello", b"world"]).astype(np.void)
array([b'\x68\x65\x6C\x6C\x6F', b'\x77\x6F\x72\x6C\x64'], dtype='|V5')
当处理那些不适合表示为字节串的字节流时,这种方法最为实用,更适合将其视为8位整数的集合。
可变宽度字符串
2.0 版本新增功能。
注意:numpy.dtypes.StringDType 是 NumPy 新增的数据类型,它利用了 NumPy 对灵活用户自定义数据类型的新支持实现。与旧版 NumPy 数据类型相比,该类型在生产工作流中的测试覆盖度尚未达到同等水平。
现实场景中的字符串数据往往长度不可预测。使用固定宽度字符串会显得笨拙,因为要在创建数组前预知需要存储的最长字符串长度,才能确保所有数据不被截断。
为此,NumPy 提供了 numpy.dtypes.StringDType 类型,该类型以 UTF-8 编码在 NumPy 数组中存储可变宽度字符串数据:
>>> from numpy.dtypes import StringDType
>>> data = ["this is a longer string", "short string"]
>>> arr = np.array(data, dtype=StringDType())
>>> arr
array(['this is a longer string', 'short string'], dtype=StringDType())
请注意,与固定宽度字符串不同,StringDType 不受数组元素最大长度的参数限制,任意长度(无论长短)的字符串可以共存于同一数组中,无需为短字符串预留填充字节的存储空间。
还需注意,与固定宽度字符串及大多数其他 NumPy 数据类型不同,StringDType 不会将字符串数据存储在“主”ndarray数据缓冲区中。
相反,数组缓冲区仅用于存储字符串数据在内存中的位置元数据。这一差异意味着,那些预期数组缓冲区包含字符串数据的代码将无法正常工作,需要更新以支持 StringDType。
缺失数据支持
字符串数据集通常并不完整,需要特殊标签来标识缺失值。默认情况下,StringDType 除了使用空字符串填充空数组外,并未提供对缺失值的特殊支持。
>>> np.empty(3, dtype=StringDType())
array(['', '', ''], dtype=StringDType())
可选地,您可以通过向初始化器传递关键字参数 na_object 来创建一个支持缺失值的 StringDType 实例:
>>> dt = StringDType(na_object=None)
>>> arr = np.array(["this array has", None, "as an entry"], dtype=dt)
>>> arr
array(['this array has', None, 'as an entry'],
dtype=StringDType(na_object=None))
>>> arr[1] is None
True
na_object可以是任意Python对象。
常见选择包括:numpy.nan、float('nan')、None,或是专门用于表示缺失数据的对象(如pandas.NA),亦或是(最好)唯一的字符串(如"__placeholder__")。
NumPy对类似NaN的标记值和字符串标记值有特殊处理机制。
类 NaN 缺失数据标记值
类 NaN 标记值在进行算术运算时会返回其自身。这包括 Python 的浮点数 nan 和 Pandas 的缺失数据标记值 pd.NA。
类 NaN 标记值在字符串操作中也会继承这些行为。这意味着,例如,与其他任何字符串相加的结果仍然是该标记值本身。
>>> dt = StringDType(na_object=np.nan)
>>> arr = np.array(["hello", np.nan, "world"], dtype=dt)
>>> arr + arr
array(['hellohello', nan, 'worldworld'], dtype=StringDType(na_object=nan))
遵循浮点数组中nan的行为,类似NaN的标记值会被排序到数组末尾:
>>> np.sort(arr)
array(['hello', 'world', nan], dtype=StringDType(na_object=nan))
字符串缺失数据标记
字符串缺失数据值是指str类型或其子类型的实例。当此类数组被传递给字符串操作或类型转换时,"缺失"条目会被视为具有字符串标记所指定的值。比较操作同样会直接使用标记值来处理缺失条目。
其他哨兵值
除了None之外,其他对象也可以作为缺失数据的哨兵值。如果在使用此类哨兵值的数组中存在任何缺失数据,字符串操作将会报错。
>>> dt = StringDType(na_object=None)
>>> arr = np.array(["this array has", None, "as an entry"])
>>> np.sort(arr)
Traceback (most recent call last):
...
TypeError: '<' not supported between instances of 'NoneType' and 'str'
强制转换非字符串类型
默认情况下,非字符串数据会被强制转换为字符串:
>>> np.array([1, object(), 3.4], dtype=StringDType())
array(['1', '<object object at 0x7faa2497dde0>', '3.4'], dtype=StringDType())
如果不希望出现此行为,可以通过在初始化时设置 coerce=False 来创建一个禁用字符串强制转换的 DType 实例:
>>> np.array([1, object(), 3.4], dtype=StringDType(coerce=False))
Traceback (most recent call last):
...
ValueError: StringDType only allows string data when string coercion is disabled.
这允许在与NumPy创建数组时使用的同一数据遍历过程中进行严格的数据验证。设置coerce=True可恢复默认行为,允许强制转换为字符串。
固定宽度字符串的相互转换
StringDType 支持在 numpy.str_、numpy.bytes_ 和 numpy.void 之间进行往返转换。当字符串需要在 ndarray 中进行内存映射,或者需要固定宽度字符串来读写具有已知最大字符串长度的列式数据格式时,转换为固定宽度字符串最为有用。
在所有情况下,转换为固定宽度字符串都需要指定允许的最大字符串长度:
>>> arr = np.array(["hello", "world"], dtype=StringDType())
>>> arr.astype(np.str_)
Traceback (most recent call last):
...
TypeError: Casting from StringDType to a fixed-width dtype with an
unspecified size is not currently supported, specify an explicit
size for the output dtype instead.
The above exception was the direct cause of the following
exception:
TypeError: cannot cast dtype StringDType() to <class 'numpy.dtypes.StrDType'>.
>>> arr.astype("U5")
array(['hello', 'world'], dtype='<U5')
numpy.bytes_ 类型转换最适合已知仅包含 ASCII 字符的字符串数据,因为超出此范围的字符无法在 UTF-8 编码中用单字节表示,会被拒绝转换。
任何有效的 Unicode 字符串都可以转换为 numpy.str_,但由于该类型对所有字符使用 32 位 UCS4 编码,对于实际文本数据(这些数据本可以用更节省内存的编码良好表示)往往会浪费内存。
此外,任何有效的 Unicode 字符串都可以转换为 numpy.void,此时 UTF-8 字节会直接存储在输出数组中:
>>> arr = np.array(["hello", "world"], dtype=StringDType())
>>> arr.astype("V5")
array([b'\x68\x65\x6C\x6C\x6F', b'\x77\x6F\x72\x6C\x64'], dtype='|V5')
必须注意确保输出数组有足够空间容纳字符串中的UTF-8字节,因为UTF-8字节流的字节大小不一定等于字符串的字符数量。
结构化数组
https://numpy.org/doc/stable/user/basics.rec.html
简介
结构化数组是一种 ndarray,其数据类型由一系列命名字段(fields)组成的简单数据类型组合而成。例如,
>>> x = np.array([('Rex', 9, 81.0), ('Fido', 3, 27.0)],
... dtype=[('name', 'U10'), ('age', 'i4'), ('weight', 'f4')])
>>> x
array([('Rex', 9, 81.), ('Fido', 3, 27.)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f4')])
这里 x 是一个长度为2的一维数组,其数据类型是一个包含三个字段的结构体:
1、名为’name’、长度不超过10的字符串
2、名为’age’的32位整数
3、名为’weight’的32位浮点数
如果访问 x 在位置1的元素,你将获得一个结构体:
>>> x[1]
np.void(('Fido', 3, 27.0), dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f4')])
你可以通过字段名索引来访问和修改结构化数组的单个字段:
>>> x['age']
array([9, 3], dtype=int32)
>>> x['age'] = 5
>>> x
array([('Rex', 5, 81.), ('Fido', 5, 27.)],
dtype=[('name', '<U10'), ('age', '<i4'), ('weight', '<f4')])
结构化数据类型的设计初衷是为了模拟C语言中的’结构体’,并共享相似的内存布局。它们主要用于与C代码交互以及对结构化缓冲区进行底层操作,例如解析二进制数据块。为此,这些类型支持特殊功能,如子数组、嵌套数据类型和联合体,并允许控制结构体的内存布局。
对于需要处理表格数据(例如存储在csv文件中的数据)的用户,可能会发现其他pydata项目更合适,比如xarray、pandas或DataArray。这些项目为表格数据分析提供了高级接口,并针对此类用途进行了更好的优化。例如,与这些工具相比,NumPy中结构化数组采用的类C结构体内存布局可能导致较差的缓存性能。
结构化数据类型
结构化数据类型可以视为一段特定长度的字节序列(该结构的itemsize),这段字节序列会被解释为多个字段的集合。每个字段包含名称、数据类型以及在结构体中的字节偏移量。字段的数据类型可以是任意NumPy数据类型(包括其他结构化数据类型),也可以是子数组数据类型——这种类型的行为类似于指定形状的ndarray。
字段的偏移量是任意的,甚至允许字段重叠。这些偏移量通常由NumPy自动确定,但也可以手动指定。
结构化数据类型创建
可以使用 numpy.dtype 函数创建结构化数据类型。共有4种不同的定义方式,它们在灵活性和简洁性上各有不同。这些方法在数据类型对象参考页中有详细说明,简要概括如下:
1、元组列表形式,每个字段对应一个元组
每个元组采用 (fieldname, datatype, shape) 格式,其中 shape 是可选的。fieldname 是字符串(如果使用字段标题则为元组,参见下文字段标题部分),datatype 可以是任何可转换为数据类型的对象,shape 是指定子数组形状的整数元组。
>>> np.dtype([('x', 'f4'), ('y', np.float32), ('z', 'f4', (2, 2))])
dtype([('x', '<f4'), ('y', '<f4'), ('z', '<f4', (2, 2))])
如果 fieldname 是空字符串 '',该字段将被赋予一个默认名称,格式为 f#,其中 # 是从左开始以 0 为基数的字段整型索引值。
>>> np.dtype([('x', 'f4'), ('', 'i4'), ('z', 'i8')])
dtype([('x', '<f4'), ('f1', '<i4'), ('z', '<i8')])
结构中各字段的字节偏移量以及结构总大小会自动确定。
2、逗号分隔的dtype规范字符串
在这种简写形式中,可以使用任何字符串dtype规范,各规范间用逗号分隔。字段的大小和字节偏移量会自动确定,字段名称默认为f0、f1等。
>>> np.dtype('i8, f4, S3')
dtype([('f0', '<i8'), ('f1', '<f4'), ('f2', 'S3')])
>>> np.dtype('3int8, float32, (2, 3)float64')
dtype([('f0', 'i1', (3,)), ('f1', '<f4'), ('f2', '<f8', (2, 3))])
3、字段参数数组的字典
这是最灵活的规范形式,因为它允许控制字段的字节偏移量和结构体的项大小。
该字典包含两个必需键——‘names’和’formats’,以及四个可选键——‘offsets’、‘itemsize’、‘aligned’和’titles’。其中:
- 'names’和’formats’的值应分别为字段名称列表和dtype规范列表,且两者长度必须相同
- 可选的’offsets’值应为整数型字节偏移量列表,对应结构体中每个字段的偏移位置。若未指定offsets,偏移量将自动计算
- 可选的’itemsize’值应为整数类型,用于描述dtype的总字节大小,该值必须足够大以包含所有字段
>>> np.dtype({'names': ['col1', 'col2'], 'formats': ['i4', 'f4']})
dtype([('col1', '<i4'), ('col2', '<f4')])
>>> np.dtype({'names': ['col1', 'col2'],
... 'formats': ['i4', 'f4'],
... 'offsets': [0, 4],
... 'itemsize': 12})
dtype({'names': ['col1', 'col2'], 'formats': ['<i4', '<f4'], 'offsets': [0, 4], 'itemsize': 12})
可以选择让字段偏移量重叠,但这意味着给某个字段赋值时可能会覆盖与其重叠的其他字段数据。有一个例外情况:由于存在覆盖内部对象指针并解引用它的风险,numpy.object_类型的字段不能与其他字段重叠。
可选参数aligned可以设置为True,这样自动计算偏移量时会使用对齐的偏移量(参见自动字节偏移与对齐),效果等同于将numpy.dtype的align关键字参数设为True。
可选参数titles应是一个与names长度相同的标题列表,具体说明见下文字段标题部分。
4、字段名字典
字典的键是字段名,值是由类型和偏移量组成的元组:
>>> np.dtype({'col1': ('i1', 0), 'col2': ('f4', 1)})
dtype([('col1', 'i1'), ('col2', '<f4')])
这种形式不被推荐使用,因为在 Python 3.6 之前的版本中,Python 字典无法保持顺序。字段标题可以通过使用三元组来指定,具体见下文。
操作和显示结构化数据类型
可以通过结构化数据类型的dtype对象的names属性获取字段名列表:
>>> d = np.dtype([('x', 'i8'), ('y', 'f4')])
>>> d.names
('x', 'y')
可以通过字段名称查询每个独立字段的数据类型:
>>> d['x']
dtype('int64')
字段名可以通过向names属性赋值来修改,需使用长度相同的字符串序列。
dtype对象还具有类似字典的属性fields,其键为字段名(以及字段标题,见下文),值为包含各字段dtype和字节偏移量的元组。
>>> d.fields
mappingproxy({'x': (dtype('int64'), 0), 'y': (dtype('float32'), 8)})
对于非结构化数组,names和fields属性都会等于None。推荐使用if dt.names is not None而非if dt.names来检测dtype是否为结构化类型,这样可以正确处理字段数为0的情况。
结构化数据类型的字符串表示会优先采用"元组列表"形式展示,如果不可行,numpy则会回退到更通用的字典形式。
自动字节偏移与对齐
NumPy 会根据是否指定了关键字参数 align=True(通过 numpy.dtype),采用以下两种方法之一来自动确定字段的字节偏移量和结构化数据类型的总体项大小。
默认情况下(align=False),NumPy 会将字段紧密排列,使每个字段从前一个字段结束的字节偏移量开始,确保字段在内存中是连续存储的。
>>> def print_offsets(d):
... print("offsets:", [d.fields[name][1] for name in d.names])
... print("itemsize:", d.itemsize)
>>> print_offsets(np.dtype('u1, u1, i4, u1, i8, u2'))
offsets: [0, 1, 2, 6, 7, 15]
itemsize: 17
如果设置 align=True,numpy 会以类似许多 C 编译器填充 C 结构体的方式对结构进行填充。对齐结构在某些情况下能提升性能,但代价是增加数据类型大小。
填充字节会插入字段之间,使得每个字段的字节偏移量成为该字段对齐值的倍数(对于简单数据类型,对齐值通常等于字段的字节大小,参见 PyArray_Descr.alignment)。此外,结构体末尾也会添加填充,使其 itemsize 成为最大字段对齐值的倍数。
>>> print_offsets(np.dtype('u1, u1, i4, u1, i8, u2', align=True))
offsets: [0, 1, 4, 8, 16, 24]
itemsize: 32
需要注意的是,虽然几乎所有现代C编译器默认会进行这种填充,但C结构体中的填充行为取决于具体实现,因此这种内存布局并不能保证与C程序中对应结构体完全匹配。可能需要同时在NumPy端或C端进行一些调整,才能实现精确对应。
如果在基于字典的dtype规范中使用了可选的offsets键来指定偏移量,那么设置align=True将会检查每个字段的偏移量是否是其大小的倍数,以及itemsize是否是最大字段大小的倍数。如果不满足这些条件,将会引发异常。
如果结构化数组的字段偏移量和itemsize满足对齐条件,该数组将会设置ALIGNED flag标志。
为了方便使用,numpy.lib.recfunctions.repack_fields函数可以将对齐的dtype或数组转换为紧凑格式,反之亦然。该函数接受一个dtype或结构化ndarray作为参数,并返回一个重新打包字段后的副本,可以选择是否包含填充字节。
字段标题
除了字段名称外,字段还可以关联一个标题,即替代名称。该标题有时用作字段的附加描述或别名。与字段名称类似,标题也可用于索引数组。
在使用元组列表形式指定dtype时,若需添加标题,可将字段名称指定为由两个字符串组成的元组(而非单个字符串),分别表示字段标题和字段名称。例如:
>>> np.dtype([(('my title', 'name'), 'f4')])
dtype([(('my title', 'name'), '<f4')])
当使用第一种基于字典的规范形式时,标题可以作为额外的'titles'键提供,如上所述。当使用第二种(不推荐)基于字典的规范形式时,可以通过提供一个3元素元组(datatype, offset, title)来指定标题,而不是通常使用的2元素元组。
>>> np.dtype({'name': ('i4', 0, 'my title')})
dtype([(('my title', 'name'), '<i4')])
如果使用了标题,dtype.fields字典将包含标题作为键。这意味着一个有标题的字段实际上会在字段字典中出现两次。这些字段的元组值还会包含第三个元素——字段标题。
由于这种情况,以及names属性会保留字段顺序而fields属性可能不会,建议通过dtype的names属性来遍历字段(该属性不会列出标题),例如:
>>> for name in d.names:
... print(d.fields[name][:2])
(dtype('int64'), 0)
(dtype('float32'), 8)
联合类型
NumPy 中实现的结构化数据类型默认以 numpy.void 作为基础类型,但也可以通过 dtype 规范中描述的 (base_dtype, dtype) 形式将其他 NumPy 类型解释为结构化类型(详见数据类型对象)。其中,base_dtype 是期望的底层数据类型,字段和标志将从 dtype 中复制。这种数据类型类似于 C 语言中的 ‘union’(联合体)。
结构化数组的索引与赋值
为结构化数组分配数据
有几种方法可以为结构化数组赋值:使用 Python 元组、标量值或其他结构化数组。
Python原生类型赋值(元组)
为结构化数组赋值的最简单方法是使用Python元组。
每个被赋值的值应当是一个长度等于数组字段数的元组,而不是列表或数组,因为这些类型会触发NumPy的广播规则。元组的元素会从左到右依次赋值给数组的连续字段:
>>> x = np.array([(1, 2, 3), (4, 5, 6)], dtype='i8, f4, f8')
>>> x[1] = (7, 8, 9)
>>> x
array([(1, 2., 3.), (7, 8., 9.)], dtype=[('f0', '<i8'), ('f1', '<f4'), ('f2', '<f8')])
标量赋值规则
当标量值被赋给结构化元素时,该值会被赋给所有字段。这种情况发生在以下两种场景:
1、将标量赋给结构化数组时
2、将非结构化数组赋给结构化数组时
>>> x = np.zeros(2, dtype='i8, f4, ?, S1')
>>> x[:] = 3
>>> x
array([(3, 3., True, b'3'), (3, 3., True, b'3')],
dtype=[('f0', '<i8'), ('f1', '<f4'), ('f2', '?'), ('f3', 'S1')])
>>> x[:] = np.arange(2)
>>> x
array([(0, 0., False, b'0'), (1, 1., True, b'1')],
dtype=[('f0', '<i8'), ('f1', '<f4'), ('f2', '?'), ('f3', 'S1')])
结构化数组也可以赋值给非结构化数组,但前提是该结构化数据类型仅包含单个字段。
>>> twofield = np.zeros(2, dtype=[('A', 'i4'), ('B', 'i4')])
>>> onefield = np.zeros(2, dtype=[('A', 'i4')])
>>> nostruct = np.zeros(2, dtype='i4')
>>> nostruct[:] = twofield
Traceback (most recent call last):
...
TypeError: Cannot cast array data from dtype([('A', '<i4'), ('B', '<i4')]) to dtype('int32') according to the rule 'unsafe'
来自其他结构化数组的赋值
两个结构化数组之间的赋值操作,会先将源数组元素转换为元组,然后再赋值给目标数组元素。具体来说,无论字段名称如何,源数组的第一个字段会赋值给目标数组的第一个字段,第二个字段同理,依此类推。字段数量不同的结构化数组之间不能相互赋值。目标结构中未被任何字段包含的字节将保持不变。
>>> a = np.zeros(3, dtype=[('a', 'i8'), ('b', 'f4'), ('c', 'S3')])
>>> b = np.ones(3, dtype=[('x', 'f4'), ('y', 'S3'), ('z', 'O')])
>>> b[:] = a
>>> b
array([(0., b'0.0', b''), (0., b'0.0', b''), (0., b'0.0', b'')],
dtype=[('x', '<f4'), ('y', 'S3'), ('z', 'O')])
涉及子数组的赋值操作
当对子数组类型的字段进行赋值时,所赋的值会首先广播至该子数组的形状。
结构化数组索引
访问单个字段
可以通过使用字段名对结构化数组进行索引,来访问和修改其单个字段。
>>> x = np.array([(1, 2), (3, 4)], dtype=[('foo', 'i8'), ('bar', 'f4')])
>>> x['foo']
array([1, 3])
>>> x['foo'] = 10
>>> x
array([(10, 2.), (10, 4.)],
dtype=[('foo', '<i8'), ('bar', '<f4')])
生成的数组是原始数组的一个视图(view)。它与原数组共享相同的内存地址,对视图进行写入操作会直接修改原始数组。
>>> y = x['bar']
>>> y[:] = 11
>>> x
array([(10, 11.), (10, 11.)],
dtype=[('foo', '<i8'), ('bar', '<f4')])
该视图与索引字段具有相同的 dtype 和 itemsize,因此通常是非结构化数组,除非遇到嵌套结构的情况。
>>> y.dtype, y.shape, y.strides
(dtype('float32'), (2,), (12,))
如果访问的字段是一个子数组,该子数组的维度会被附加到结果形状中:
>>> x = np.zeros((2, 2), dtype=[('a', np.int32), ('b', np.float64, (3, 3))])
>>> x['a'].shape
(2, 2)
>>> x['b'].shape
(2, 2, 3, 3)
访问多个字段
可以通过多字段索引对结构化数组进行索引和赋值,其中索引是一个字段名称列表。
警告:从 NumPy 1.15 到 NumPy 1.16,多字段索引的行为发生了变化。使用多字段索引的结果是对原始数组的视图,具体如下:
>>> a = np.zeros(3, dtype=[('a', 'i4'), ('b', 'i4'), ('c', 'f4')])
>>> a[['a', 'c']]
array([(0, 0.), (0, 0.), (0, 0.)],
dtype={'names': ['a', 'c'], 'formats': ['<i4', '<f4'], 'offsets': [0, 8], 'itemsize': 12})
对视图的赋值会修改原始数组。视图中的字段将按照索引顺序排列。需要注意的是,与单字段索引不同,视图的 dtype 与原始数组具有相同的 itemsize,并且字段在原始数组中的偏移量保持不变,未索引的字段仅会被忽略。
警告:在 NumPy 1.15 版本中,使用多字段索引数组会返回上述结果的副本,但字段在内存中是紧密排列的,就像通过了 numpy.lib.recfunctions.repack_fields 函数处理一样。
从 NumPy 1.16 开始的新行为会导致未索引字段的位置存在额外的“填充”字节(与 1.15 版本相比)。如果代码依赖于数据的“紧凑”内存布局,则需要更新相关代码。例如类似以下的代码:
>>> a[['a', 'c']].view('i8') # Fails in Numpy 1.16
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: When changing to a smaller dtype, its size must be a divisor of the size of original dtype
需要进行修改。这段代码自 NumPy 1.12 版本起会引发 FutureWarning,而类似代码自 1.7 版本起就会触发该警告。
在 1.16 版本中,numpy.lib.recfunctions 模块引入了一系列函数来帮助用户适应这一变更,具体包括:
numpy.lib.recfunctions.repack_fields、
numpy.lib.recfunctions.structured_to_unstructured、
numpy.lib.recfunctions.unstructured_to_structured、
numpy.lib.recfunctions.apply_along_fields、
numpy.lib.recfunctions.assign_fields_by_name 以及
numpy.lib.recfunctions.require_fields。
其中 numpy.lib.recfunctions.repack_fields 函数始终可用于还原旧版行为,因为它会返回结构化数组的打包副本。例如,前文代码可替换为:
>>> from numpy.lib.recfunctions import repack_fields
>>> repack_fields(a[['a', 'c']]).view('i8') # supported in 1.16
array([0, 0, 0])
此外,NumPy 现在提供了一个新函数 numpy.lib.recfunctions.structured_to_unstructured,对于希望将结构化数组转换为非结构化数组的用户来说,这是一个更安全且高效的替代方案,因为上述视图方法通常就是为此目的而设计的。
该函数能够安全地转换为非结构化类型,同时考虑填充字节问题,通常可以避免复制操作,并且还会根据需要自动转换数据类型,这与视图方法不同。示例代码如下:
>>> b = np.zeros(3, dtype=[('x', 'f4'), ('y', 'f4'), ('z', 'f4')])
>>> b[['x', 'z']].view('f4')
array([0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
可以通过替换以下内容来提高安全性:
>>> from numpy.lib.recfunctions import structured_to_unstructured
>>> structured_to_unstructured(b[['x', 'z']])
array([[0., 0.],
[0., 0.],
[0., 0.]], dtype=float32)
使用多字段索引对数组进行赋值会修改原始数组:
>>> a[['a', 'c']] = (2, 3)
>>> a
array([(2, 0, 3.), (2, 0, 3.), (2, 0, 3.)],
dtype=[('a', '<i4'), ('b', '<i4'), ('c', '<f4')])
这遵循了前文描述的结构化数组赋值规则。例如,这意味着可以通过适当的多字段索引来交换两个字段的值:
>>> a[['a', 'c']] = a[['c', 'a']]
通过整数索引获取结构化标量
使用整数索引访问结构化数组的单个元素时,会返回一个结构化标量:
>>> x = np.array([(1, 2., 3.)], dtype='i, f, f')
>>> scalar = x[0]
>>> scalar
np.void((1, 2.0, 3.0), dtype=[('f0', '<i4'), ('f1', '<f4'), ('f2', '<f4')])
>>> type(scalar)
<class 'numpy.void'>
与其他 NumPy 标量不同,结构化标量是可变的,并且会像原始数组的视图一样运作。因此,修改标量会同时修改原始数组。结构化标量还支持通过字段名进行访问和赋值。
>>> x = np.array([(1, 2), (3, 4)], dtype=[('foo', 'i8'), ('bar', 'f4')])
>>> s = x[0]
>>> s['bar'] = 100
>>> x
array([(1, 100.), (3, 4.)],
dtype=[('foo', '<i8'), ('bar', '<f4')])
与元组类似,结构化标量也可以通过整数进行索引:
>>> scalar = np.array([(1, 2., 3.)], dtype='i, f, f')[0]
>>> scalar[0]
1
>>> scalar[1] = 4
因此,可以将元组视为 Python 原生类型中与 NumPy 结构化类型相对应的等价物,就像 Python 原生整数对应于 NumPy 的整数类型一样。通过调用 numpy.ndarray.item 方法,可以将结构化标量转换为元组。
>>> scalar.item(), type(scalar.item())
((1, 4.0, 3.0), <class 'tuple'>)
查看包含对象的结构化数组
为了防止覆盖 object 类型字段中的对象指针,NumPy 目前不允许查看包含对象的结构化数组。
结构体比较与提升
当两个 void 结构化数组的数据类型(dtype)相同时,测试数组的相等性将生成一个与原数组维度相同的布尔数组。其中,若对应结构体的所有字段均相等,则该位置的元素会被设为 True。
>>> a = np.array([(1, 1), (2, 2)], dtype=[('a', 'i4'), ('b', 'i4')])
>>> b = np.array([(1, 1), (2, 3)], dtype=[('a', 'i4'), ('b', 'i4')])
>>> a == b
array([True, False])
NumPy 会提升各个字段的数据类型以执行比较操作。
因此以下写法同样有效(注意 'a' 字段的 'f4' 数据类型):
>>> b = np.array([(1.0, 1), (2.5, 2)], dtype=[("a", "f4"), ("b", "i4")])
>>> a == b
array([True, False])
要比较两个结构化数组,必须能够将它们提升为共同的 dtype,如 numpy.result_type 和 numpy.promote_types 所返回的类型。
这要求字段数量、字段名称和字段标题必须完全匹配。
如果无法进行类型提升(例如由于字段名称不匹配),NumPy 将抛出错误。
两个结构化 dtype 之间的提升操作会生成一个规范的 dtype,确保所有字段都采用原生字节顺序:
>>> np.result_type(np.dtype("i,>i"))
dtype([('f0', '<i4'), ('f1', '<i4')])
>>> np.result_type(np.dtype("i,>i"), np.dtype("i,i"))
dtype([('f0', '<i4'), ('f1', '<i4')])
类型提升后的结果 dtype 也保证是紧凑的,这意味着所有字段都是连续排列的,并且移除了不必要的填充:
>>> dt = np.dtype("i1,V3,i4,V1")[["f0", "f2"]]
>>> dt
dtype({'names':['f0','f2'], 'formats':['i1','<i4'], 'offsets':[0,4], 'itemsize':9})
>>> np.result_type(dt)
dtype([('f0', 'i1'), ('f2', '<i4')])
请注意,结果显示时没有offsets或itemsize,这表明不存在额外的填充。
如果创建结构化dtype时使用了align=True以确保dtype.isalignedstruct为真,则会保留此属性:
>>> dt = np.dtype("i1,V3,i4,V1", align=True)[["f0", "f2"]]
>>> dt
dtype({'names':['f0','f2'], 'formats':['i1','<i4'], 'offsets':[0,4], 'itemsize':12}, align=True)
>>> np.result_type(dt)
dtype([('f0', 'i1'), ('f2', '<i4')], align=True)
>>> np.result_type(dt).isalignedstruct
True
在提升多种数据类型(dtypes)时,只要任一输入是对齐的,结果就会保持对齐。
>>> np.result_type(np.dtype("i,i"), np.dtype("i,i", align=True))
dtype([('f0', '<i4'), ('f1', '<i4')], align=True)
当比较空结构数组时,< 和 > 运算符总是返回 False,并且不支持算术和位运算。
在 1.23 版本中的变更:在 NumPy 1.23 之前,当提升到共同 dtype 失败时会发出警告并返回 False。
此外,类型提升规则更加严格:例如会拒绝上述混合浮点/整数的比较情况。
记录数组
作为一项可选便利功能,NumPy 提供了 ndarray 的子类 numpy.recarray,它允许通过属性(而不仅限于索引)访问结构化数组的字段。
记录数组使用特殊数据类型 numpy.record,该类型允许通过属性访问从数组获取的结构化标量字段。numpy.rec 模块提供了从各种对象创建记录数组的函数。
更多用于创建和操作结构化数组的辅助函数可在 numpy.lib.recfunctions 中找到。
创建记录数组最简单的方式是使用 numpy.rec.array:
>>> recordarr = np.rec.array([(1, 2., 'Hello'), (2, 3., "World")],
... dtype=[('foo', 'i4'),('bar', 'f4'), ('baz', 'S10')])
>>> recordarr.bar
array([2., 3.], dtype=float32)
>>> recordarr[1:2]
rec.array([(2, 3., b'World')],
dtype=[('foo', '<i4'), ('bar', '<f4'), ('baz', 'S10')])
>>> recordarr[1:2].foo
array([2], dtype=int32)
>>> recordarr.foo[1:2]
array([2], dtype=int32)
>>> recordarr[1].baz
b'World'
numpy.rec.array 能够将多种类型的参数转换为记录数组,包括结构化数组:
>>> arr = np.array([(1, 2., 'Hello'), (2, 3., "World")],
...
dtype=[('foo', 'i4'), ('bar', 'f4'), ('baz', 'S10')])
>>> recordarr = np.rec.array(arr)
numpy.rec模块提供了多个便捷函数用于创建记录数组,具体可参考记录数组创建例程。
通过使用合适的view方法,可以获取结构化数组的记录数组表示形式。
>>> arr = np.array([(1, 2., 'Hello'), (2, 3., "World")],
... dtype=[('foo', 'i4'),('bar', 'f4'), ('baz', 'S10')])
>>> recordarr = arr.view(dtype=np.dtype((np.record, arr.dtype)),
... type=np.recarray)
为方便起见,将 ndarray 视为 numpy.recarray 类型时,
会自动转换为 numpy.record 数据类型,因此视图中可以省略 dtype 参数:
>>> recordarr = arr.view(np.recarray)
>>> recordarr.dtype
dtype((numpy.record, [('foo', '<i4'), ('bar', '<f4'), ('baz', 'S10')]))
要恢复为普通的 ndarray,必须同时重置 dtype 和 type。以下视图实现了这一操作,并考虑了 recordarr 不是结构化类型的特殊情况:
>>> arr2 = recordarr.view(recordarr.dtype.fields or recordarr.dtype, np.ndarray)
通过索引或属性访问的记录数组字段,如果该字段具有结构化类型,则返回为记录数组;否则返回为普通 ndarray。
>>> recordarr = np.rec.array([('Hello', (1, 2)), ("World", (3, 4))],
... dtype=[('foo', 'S6'),('bar', [('A', int), ('B', int)])])
>>> type(recordarr.foo)
<class 'numpy.ndarray'>
>>> type(recordarr.bar)
<class 'numpy.rec.recarray'>
请注意,如果某个字段与 ndarray 属性同名,ndarray 属性将优先。这种情况下,虽然无法通过属性访问该字段,但仍可通过索引访问。
记录数组辅助函数
用于操作结构化数组的实用工具集合。
这些函数最初大多由 John Hunter 为 matplotlib 实现。为方便使用,现已重写并扩展。
numpy.lib.recfunctions.append_fields(*base, names, data, dtypes=None, fill_value=-1, usemask=True, asrecarray=False)
向现有数组添加新字段。
字段名称通过 names 参数指定,对应值通过 data 参数指定。
若仅添加单个字段,names、data 和 dtypes 可直接传入值而无需使用列表。
参数:
base : 数组
待扩展的输入数组。
names : 字符串或序列
新字段名称的字符串或字符串序列。
data : 数组或数组序列
存储待添加字段的数组或数组序列。
dtypes : 数据类型序列,可选
数据类型或数据类型序列。若为None,则从 data 自动推断数据类型。
fill_value : {浮点数},可选
用于填充较短数组缺失数据的默认值。
usemask : {False, True},可选
是否返回掩码数组。
asrecarray : {False, True},可选
是否返回记录数组(MaskedRecords)。
numpy.lib.recfunctions.apply_along_fields(func, arr)
将函数 ‘func’ 作为归约操作应用于结构化数组的字段维度。
此功能类似于 numpy.apply_along_axis,但将结构化数组的字段视为额外维度。所有字段会先按照 numpy.result_type 的类型提升规则转换为统一类型。
参数:
func : 函数
应用于"字段"维度的函数。该函数必须支持 axis 参数,如 numpy.mean、numpy.sum 等。
arr : ndarray
待处理的结构化数组。
返回:
out : ndarray
归约操作的结果
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> b = np.array([(1, 2, 5), (4, 5, 7), (7, 8 ,11), (10, 11, 12)],
... dtype=[('x', 'i4'), ('y', 'f4'), ('z', 'f8')])
>>> rfn.apply_along_fields(np.mean, b)
array([ 2.66666667, 5.33333333, 8.66666667, 11、 ])
>>> rfn.apply_along_fields(np.mean, b[['x', 'z']])
array([ 3、, 5.5, 9、, 11、])
numpy.lib.recfunctions.assign_fields_by_name(*dst, src, zero_unassigned=True)
通过字段名将一个结构化数组的值赋给另一个数组。
在NumPy >= 1.14版本中,结构化数组之间的赋值通常是"按位置"复制,即无论字段名是否相同,源数组的第一个字段会被复制到目标数组的第一个字段,依此类推。
而本函数采用"按字段名"复制的方式,目标数组中的字段会从源数组同名字段获取值。对于嵌套结构,此操作会递归执行。这种赋值行为与NumPy 1.6到1.13版本的实现一致。
参数说明:
dst : ndarray
src : ndarray
赋值操作中的源数组和目标数组。
zero_unassigned : bool, 可选参数
若为True,目标数组中找不到匹配字段的位置会被填充为0值(这是NumPy <= 1.13版本的行为)。若为False,则这些字段保持不变。
numpy.lib.recfunctions.drop_fields(*base, drop_names, usemask=True, asrecarray=False)
返回删除指定字段后的新数组。
支持嵌套字段的删除。
版本1.18.0变更: 当所有字段都被删除时,drop_fields会返回一个包含0个字段的数组,而不再像之前版本那样返回None。
参数说明:
base : array
输入数组
drop_names : string或sequence
需要删除的字段名称,可以是字符串或字符串序列。
usemask : {False, True}, 可选参数
是否返回掩码数组。
asrecarray : string或sequence, 可选参数
控制返回类型:设为True时返回recarray或mrecarray,设为False时返回灵活数据类型的普通ndarray或掩码数组(默认)。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> a = np.array([(1, (2, 3.0)), (4, (5, 6.0))],
... dtype=[('a', np.int64), ('b', [('ba', np.double), ('bb', np.int64)])])
>>> rfn.drop_fields(a, 'a')
array([((2., 3),), ((5., 6),)],
dtype=[('b', [('ba', '<f8'), ('bb', '<i8')])])
>>> rfn.drop_fields(a, 'ba')
array([(1, (3,)), (4, (6,))], dtype=[('a', '<i8'), ('b', [('bb', '<i8')])])
>>> rfn.drop_fields(a, ['ba', 'bb'])
array([(1,), (4,)], dtype=[('a', '<i8')])
numpy.lib.recfunctions.find_duplicates(a, key=None, ignoremask=True, return_index=False)
查找结构化数组中沿指定键的重复项
参数说明:
a类数组输入数组
key{字符串, None}, 可选用于检查重复项的字段名称。若为None,则按记录执行搜索
ignoremask{True, False}, 可选是否应忽略被掩码数据或将其视为重复项
return_index{False, True}, 可选是否返回重复值的索引位置
使用示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> ndtype = [('a', int)]
>>> a = np.ma.array([1, 1, 1, 2, 2, 3, 3],
... mask=[0, 0, 1, 0, 0, 0, 1]).view(ndtype)
>>> rfn.find_duplicates(a, ignoremask=True, return_index=True)
(masked_array(data=[(1,), (1,), (2,), (2,)],
mask=[(False,), (False,), (False,), (False,)], fill_value=(999999,),
dtype=[('a', '<i8')]), array([0, 1, 3, 4]))
numpy.lib.recfunctions.flatten_descr(ndtype)
展平结构化数据类型的描述。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> ndtype = np.dtype([('a', '<i4'), ('b', [('ba', '<f8'), ('bb', '<i4')])])
>>> rfn.flatten_descr(ndtype)
(('a', dtype('int32')), ('ba', dtype('float64')), ('bb', dtype('int32')))
numpy.lib.recfunctions.get_fieldstructure(*adtype, lastname=None, parents=None)
返回一个字典,其中字段索引其父字段列表。
此函数用于简化访问嵌套在其他字段中的字段。
参数:
adtypenp.dtype输入数据类型
lastname可选最后处理的字段名(递归过程中内部使用)。
parents字典父字段字典(递归过程中内部使用)。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> ndtype = np.dtype([('A', int),
... ('B', [('BA', int),
... ('BB', [('BBA', int), ('BBB', int)])])])
>>> rfn.get_fieldstructure(ndtype)
... # XXX: possible regression, order of BBA and BBB is swapped
{'A': [], 'B': [], 'BA': ['B'], 'BB': ['B'], 'BBA': ['B', 'BB'], 'BBB': ['B', 'BB']}
numpy.lib.recfunctions.get_names(*adtype)
返回输入数据类型的字段名称组成的元组。输入数据类型必须包含字段,否则会引发错误。
参数:
adtype dtype
输入数据类型
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> rfn.get_names(np.empty((1,), dtype=[('A', int)]).dtype)
('A',)
>>> rfn.get_names(np.empty((1,), dtype=[('A',int), ('B', float)]).dtype)
('A', 'B')
>>> adtype = np.dtype([('a', int), ('b', [('ba', int), ('bb', int)])])
>>> rfn.get_names(adtype)
('a', ('b', ('ba', 'bb')))
numpy.lib.recfunctions.get_names_flat(adtype)
返回输入数据类型的字段名称组成的元组。输入数据类型必须包含字段,否则会引发错误。
嵌套结构会预先被展平。
参数:
adtype : dtype
输入数据类型
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> rfn.get_names_flat(np.empty((1,), dtype=[('A', int)]).dtype) is None
False
>>> rfn.get_names_flat(np.empty((1,), dtype=[('A',int), ('B', str)]).dtype)
('A', 'B')
>>> adtype = np.dtype([('a', int), ('b', [('ba', int), ('bb', int)])])
>>> rfn.get_names_flat(adtype)
('a', 'b', 'ba', 'bb')
numpy.lib.recfunctions.join_by(key, r1, r2, jointype='inner', r1postfix='1', r2postfix='2', defaults=None, usemask=True, asrecarray=False)
基于键值 key 合并数组 r1 和 r2。
key 应为字符串或字符串序列,对应用于连接数组的字段。如果在两个输入数组中找不到 key 字段,则会引发异常。r1 和 r2 在 key 字段上不应有任何重复值:重复值的存在会使输出结果不可靠。注意,算法不会主动检查重复值。
参数:
key:{字符串, 序列}
用于比较的字段名称或字段名称序列。
r1, r2:数组
结构化数组。
jointype:{‘inner’, ‘outer’, ‘leftouter’},可选
- ‘inner’:返回 r1 和 r2 共有的元素。
- ‘outer’:返回共有元素及 r1 中不在 r2 的元素和 r2 中不在 r1 的元素。
- ‘leftouter’:返回共有元素及 r1 中不在 r2 的元素。
r1postfix:字符串,可选
附加到 r1 字段名的后缀,这些字段存在于 r2 但不在 key 中。
r2postfix:字符串,可选
附加到 r2 字段名的后缀,这些字段存在于 r1 但不在 key 中。
defaults:{字典},可选
字段名到对应默认值的映射字典。
usemask:{True, False},可选
是否返回 MaskedArray(或当 asrecarray==True 时返回 MaskedRecords)或 ndarray。
asrecarray:{False, True},可选
是否返回 recarray(或当 usemask==True 时返回 MaskedRecords)或灵活类型的 ndarray。
注意:
- 输出结果按 key 排序。
- 算法会临时创建一个数组,方法是删除两个数组中不在 key 中的字段并拼接结果。该数组排序后,选择共有条目。输出通过填充所选条目的字段构建。如果存在重复值,匹配关系不会被保留。
numpy.lib.recfunctions.merge_arrays(*seqarrays, fill_value=-1, flatten=False, usemask=False, asrecarray=False)
按字段逐个合并数组。
参数:
seqarrays:ndarrays 序列
待合并的数组序列。
fill_value:{float},可选
用于填充较短数组中缺失数据的值。
flatten:{False, True},可选
是否展开嵌套字段。
usemask:{False, True},可选
是否返回掩码数组。
asrecarray:{False, True},可选
是否返回 recarray(或 MaskedRecords)。
注意:
- 不使用掩码时,缺失值会根据其类型填充如下:
- 整数:
-1 - 浮点数:
-1.0 - 字符:
'-' - 字符串:
'-1' - 布尔值:
True
- 整数:
- 注:这些值是通过实验得出的。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> rfn.merge_arrays((np.array([1, 2]), np.array([10., 20., 30.])))
array([( 1, 10.), ( 2, 20.), (-1, 30.)],
dtype=[('f0', '<i8'), ('f1', '<f8')])
>>> rfn.merge_arrays((np.array([1, 2], dtype=np.int64),
... np.array([10., 20., 30.])), usemask=False)
array([(1, 10.0), (2, 20.0), (-1, 30.0)],
dtype=[('f0', '<i8'), ('f1', '<f8')])
>>> rfn.merge_arrays((np.array([1, 2]).view([('a', np.int64)]),
... np.array([10., 20., 30.])),
... usemask=False, asrecarray=True)
rec.array([( 1, 10.), ( 2, 20.), (-1, 30.)],
dtype=[('a', '<i8'), ('f1', '<f8')])
numpy.lib.recfunctions.rec_append_fields(*base, names, data, dtypes=None)
向现有数组添加新字段。
字段名称通过names参数指定,对应的值通过data参数提供。
如果仅添加单个字段,names、data和dtypes可以不是列表而直接使用值。
参数说明:
basearray
需要扩展的输入数组。
namesstring, sequence
字符串或字符串序列,对应新字段的名称。
dataarray or sequence of arrays
数组或数组序列,存储要添加到基础数组的字段值。
dtypessequence of datatypes, optional
数据类型或数据类型序列。
如果为None,则根据data自动推断数据类型。
返回值:
appended_arraynp.recarray
另请参阅 : append_fields
numpy.lib.recfunctions.rec_drop_fields(*base, drop_names)
返回一个新的numpy.recarray,其中已移除drop_names指定的字段。
numpy.lib.recfunctions.rec_join(key, r1, r2, *jointype='inner', r1postfix='1', r2postfix='2', defaults=None)
根据键值连接数组r1和r2。
这是join_by的替代方案,始终返回np.recarray类型的结果。
另请参阅 : join_by等效函数
numpy.lib.recfunctions.recursive_fill_fields(*input, output)
将输入数组的字段递归填充到输出数组,支持嵌套结构。
参数说明:
inputndarray
输入数组。
outputndarray
输出数组。
注意事项
- output的尺寸至少应与input相同
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> a = np.array([(1, 10.), (2, 20.)], dtype=[('A', np.int64), ('B', np.float64)])
>>> b = np.zeros((3,), dtype=a.dtype)
>>> rfn.recursive_fill_fields(a, b)
array([(1, 10.), (2, 20.), (0, 0.)], dtype=[('A', '<i8'), ('B', '<f8')])
numpy.lib.recfunctions.rename_fields(*base, namemapper)
重命名灵活数据类型 ndarray 或 recarray 的字段。
支持嵌套字段。
参数:
base: ndarray 需要修改字段的输入数组。
namemapper: dictionary 将旧字段名映射到新名称的字典。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> a = np.array([(1, (2, [3.0, 30.])), (4, (5, [6.0, 60.]))],
... dtype=[('a', int),('b', [('ba', float), ('bb', (float, 2))])])
>>> rfn.rename_fields(a, {'a':'A', 'bb':'BB'})
array([(1, (2., [ 3., 30.])), (4, (5., [ 6., 60.]))],
dtype=[('A', '<i8'), ('b', [('ba', '<f8'), ('BB', '<f8', (2,))])])
numpy.lib.recfunctions.repack_fields(*a, align=False, recurse=False)
重新打包结构化数组或数据类型在内存中的字段布局。
结构化数据类型的内存布局允许字段位于任意的字节偏移位置。这意味着字段之间可能存在填充字节,它们的偏移量可以非单调递增,甚至可能出现字段重叠。
该方法会消除所有重叠字段,并重新排序内存中的字段使其具有递增的字节偏移量。根据align参数的设置(其行为类似于numpy.dtype的align选项),会添加或移除填充字节。
当align=False时,该方法会产生"紧凑"的内存布局:
- 每个字段从前一个字段结束的字节位置开始
- 所有填充字节将被移除
当align=True时,该方法会产生"对齐"的内存布局:
- 每个字段的偏移量是其对齐大小的整数倍
- 通过添加必要的填充字节,使总项目大小成为最大对齐大小的整数倍
参数说明:
a : ndarray或dtype
需要重新打包字段的数组或数据类型
align : 布尔值
若为True则使用"对齐"内存布局,否则使用"紧凑"布局
recurse : 布尔值
若为True则同时重新打包嵌套结构
返回值:
repacked : ndarray或dtype
返回字段重新打包后的a副本。若无需重新打包则返回a本身
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> def print_offsets(d):
... print("offsets:", [d.fields[name][1] for name in d.names])
... print("itemsize:", d.itemsize)
...
>>> dt = np.dtype('u1, <i8, <f8', align=True)
>>> dt
dtype({'names': ['f0', 'f1', 'f2'], 'formats': ['u1', '<i8', '<f8'], 'offsets': [0, 8, 16], 'itemsize': 24}, align=True)
>>> print_offsets(dt)
offsets: [0, 8, 16]
itemsize: 24
>>> packed_dt = rfn.repack_fields(dt)
>>> packed_dt
dtype([('f0', 'u1'), ('f1', '<i8'), ('f2', '<f8')])
>>> print_offsets(packed_dt)
offsets: [0, 1, 9]
itemsize: 17
numpy.lib.recfunctions.require_fields(*array, required_dtype)
通过字段名赋值的方式将结构化数组转换为新的数据类型。
此函数根据字段名称从旧数组向新数组赋值,因此输出数组中字段的值就是源数组里同名字段的值。这样做的效果是创建一个新的ndarray,其中仅包含required_dtype所"要求"的字段。
如果required_dtype中的某个字段名在输入数组中不存在,则会在输出数组中创建该字段并设为0。
参数:
andarray待转换的数组
required_dtypedtype输出数组的数据类型
返回值:
outndarray具有新数据类型的数组,其字段值从输入数组的同名字段复制而来
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> a = np.ones(4, dtype=[('a', 'i4'), ('b', 'f8'), ('c', 'u1')])
>>> rfn.require_fields(a, [('b', 'f4'), ('c', 'u1')])
array([(1., 1), (1., 1), (1., 1), (1., 1)], dtype=[('b', '<f4'), ('c', 'u1')])
>>> rfn.require_fields(a, [('b', 'f4'), ('newf', 'u1')])
array([(1., 0), (1., 0), (1., 0), (1., 0)], dtype=[('b', '<f4'), ('newf', 'u1')])
numpy.lib.recfunctions.stack_arrays(*arrays, defaults=None, usemask=True, asrecarray=False, autoconvert=False)
按字段叠加数组
参数说明:
arrays 数组或序列
输入数组序列。
defaults 字典, 可选
字段名到对应默认值的映射字典。
usemask {True, False}, 可选
是否返回 MaskedArray(当 asrecarray==True 时返回 MaskedRecords)或 ndarray。
asrecarray {False, True}, 可选
是否返回 recarray(当 usemask==True 时返回 MaskedRecords)
或仅返回灵活类型的 ndarray。
autoconvert {False, True}, 可选
是否自动将字段类型转换为最大值类型。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> x = np.array([1, 2,])
>>> rfn.stack_arrays(x) is x
True
>>> z = np.array([('A', 1), ('B', 2)], dtype=[('A', '|S3'), ('B', float)])
>>> zz = np.array([('a', 10., 100.), ('b', 20., 200.), ('c', 30., 300.)],
... dtype=[('A', '|S3'), ('B', np.double), ('C', np.double)])
>>> test = rfn.stack_arrays((z,zz))
>>> test
masked_array(data=[(b'A', 1.0, --), (b'B', 2.0, --), (b'a', 10.0, 100.0),
(b'b', 20.0, 200.0), (b'c', 30.0, 300.0)],
mask=[(False, False, True), (False, False, True),
(False, False, False), (False, False, False),
(False, False, False)], fill_value=(b'N/A', 1e+20, 1e+20),
dtype=[('A', 'S3'), ('B', '<f8'), ('C', '<f8')])
numpy.lib.recfunctions.structured_to_unstructured(arr, *dtype=None, copy=False, casting='unsafe')
将n维结构化数组转换为(n+1)维非结构化数组。
新数组的最后一个维度大小等于输入数组的字段元素数量。如果未指定输出数据类型,则根据所有字段数据类型的NumPy类型提升规则自动确定。
嵌套字段以及任何子数组字段的每个元素,均视为单个字段元素。
参数说明:
arr : ndarray
待转换的结构化数组或数据类型。不能包含对象数据类型。
dtype : dtype, 可选
输出非结构化数组的数据类型。
copy : bool, 可选
若为True则始终返回副本。若为False,则在满足以下条件时返回视图:
- 字段的dtype和步长符合要求
- 数组子类型为
numpy.ndarray、numpy.recarray或numpy.memmap
版本1.25.0变更:当字段间具有统一步长时,现在可返回视图。
casting : {‘no’, ‘equiv’, ‘safe’, ‘same_kind’, ‘unsafe’}, 可选
参见numpy.ndarray.astype的casting参数。控制允许的数据类型转换方式。
返回值:
unstructured : ndarray
增加一个维度的非结构化数组。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> a = np.zeros(4, dtype=[('a', 'i4'), ('b', 'f4,u2'), ('c', 'f4', 2)])
>>> a
array([(0, (0., 0), [0., 0.]), (0, (0., 0), [0., 0.]), (0, (0., 0), [0., 0.]), (0, (0., 0), [0., 0.])],
dtype=[('a', '<i4'), ('b', [('f0', '<f4'), ('f1', '<u2')]), ('c', '<f4', (2,))])
>>> rfn.structured_to_unstructured(a)
array([[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0.]])
>>> b = np.array([(1, 2, 5), (4, 5, 7), (7, 8 ,11), (10, 11, 12)],
... dtype=[('x', 'i4'), ('y', 'f4'), ('z', 'f8')])
>>> np.mean(rfn.structured_to_unstructured(b[['x', 'z']]), axis=-1)
array([ 3、, 5.5, 9、, 11、])
numpy.lib.recfunctions.unstructured_to_structured(arr, *dtype=None, names=None, align=False, copy=False, casting='unsafe')
将n维非结构化数组转换为(n-1)维结构化数组。
输入数组的最后一个维度会被转换为结构体,其字段元素数量等于输入数组最后一个维度的大小。默认情况下,所有输出字段都使用输入数组的数据类型,但也可以提供具有相同数量字段元素的结构化数据类型作为替代。
嵌套字段以及任何子数组字段的每个元素都会计入字段元素数量。
参数说明:
arr : ndarray
待转换的非结构化数组或数据类型。
dtype : dtype, 可选
输出数组的结构化数据类型。
names : 字符串列表, 可选
如果未提供dtype参数,此参数按顺序指定输出数据类型的字段名称。字段数据类型将与输入数组相同。
align : 布尔值, 可选
是否创建对齐的内存布局。
copy : 布尔值, 可选
参见numpy.ndarray.astype的copy参数。如果为True,则始终返回副本;如果为False且满足dtype要求,则返回视图。
casting : {‘no’, ‘equiv’, ‘safe’, ‘same_kind’, ‘unsafe’}, 可选
参见numpy.ndarray.astype的casting参数。控制可能发生的数据类型转换方式。
返回值:
structured : ndarray
维度减少后的结构化数组。
示例:
>>> import numpy as np
>>> from numpy.lib import recfunctions as rfn
>>> dt = np.dtype([('a', 'i4'), ('b', 'f4,u2'), ('c', 'f4', 2)])
>>> a = np.arange(20).reshape((4,5))
>>> a
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14],
[15, 16, 17, 18, 19]])
>>> rfn.unstructured_to_structured(a, dt)
array([( 0, ( 1., 2), [ 3., 4.]), ( 5, ( 6., 7), [ 8., 9.]), (10, (11., 12), [13., 14.]), (15, (16., 17), [18., 19.])],
dtype=[('a', '<i4'), ('b', [('f0', '<f4'), ('f1', '<u2')]), ('c', '<f4', (2,))])
通用函数 ufunc 基础
https://numpy.org/doc/stable/user/basics.ufuncs.html
另见:通用函数(ufunc)
通用函数(简称ufunc)是一种对ndarrays进行逐元素操作的函数,支持数组广播、类型转换等标准特性。也就是说,ufunc是对特定数量输入产生特定数量输出的函数进行"向量化"包装的产物。
在NumPy中,通用函数是numpy.ufunc类的实例。许多内置函数都是用编译的C代码实现的。基础ufunc操作标量,但也存在一种广义类型——其基本元素是子数组(向量、矩阵等),并在其他维度上进行广播。最简单的例子就是加法运算符:
>>> np.array([0,2,3,4]) + np.array([1,1,-1,2])
array([1, 3, 2, 6])
用户还可以使用 numpy.frompyfunc 工厂函数来生成自定义的 numpy.ufunc 实例。
Ufunc 方法
所有 ufunc 都有四种方法。这些方法可以在方法部分找到。不过,这些方法仅适用于接收两个输入参数并返回一个输出参数的标量 ufunc。尝试在其他 ufunc 上调用这些方法会导致 ValueError。
类 reduce 方法都接受 axis 参数、dtype 参数和 out 参数,且数组的维度必须 >= 1。axis 参数指定了数组中进行归约操作的轴(负值表示从后往前计数)。通常它是一个整数,但对于 numpy.ufunc.reduce,它也可以是一个 int 元组来同时归约多个轴,或者设为 None 来归约所有轴。例如:
>>> x = np.arange(9).reshape(3,3)
>>> x
array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
>>> np.add.reduce(x, 1)
array([ 3, 12, 21])
>>> np.add.reduce(x, (0, 1))
36
dtype 关键字能帮助解决一个常见问题——当直接使用 ufunc.reduce 时,可能会出现数组元素总和超出原数据类型范围的情况。例如,单字节整数数组求和时,结果可能无法用原数据类型表示。
通过 dtype 关键字,您可以指定归约运算使用的数据类型(从而决定输出结果的类型),确保输出类型具有足够的精度容纳计算结果。通常,调整归约类型的责任在用户自身,但存在一个例外情况:当未指定 dtype 且进行"加法"或"乘法"归约时,若输入是比 numpy.int_ 更小的整数(或布尔)类型,系统会自动将其提升为 int_(或 numpy.uint)类型。
>>> x.dtype
dtype('int64')
>>> np.multiply.reduce(x, dtype=float)
array([ 0., 28., 80.])
最终,out 关键字允许你提供一个输出数组(对于多输出 ufuncs 则是一个输出数组的元组)。
如果指定了 out 参数,那么 dtype 参数仅用于内部计算。
以前面的示例中的 x 为例:
>>> y = np.zeros(3, dtype=int)
>>> y
array([0, 0, 0])
>>> np.multiply.reduce(x, dtype=float, out=y)
array([ 0, 28, 80])
Ufuncs 还有第五个方法 numpy.ufunc.at,它允许通过高级索引执行原地操作。在使用高级索引的维度上不会启用缓冲机制,因此高级索引可以多次引用同一元素,且每次操作都会基于该元素前一次操作的结果执行。
输出类型确定
当所有输入参数都不是 ndarray 时,ufunc(及其方法)的输出结果不一定是 ndarray。实际上,如果任何输入参数定义了 __array_ufunc__ 方法,控制权将完全传递给该方法,即 ufunc 被重写。
如果没有输入参数重写 ufunc,那么所有输出数组将被传递给输入参数中定义了 __array_wrap__ 方法(除了 ndarrays 和标量)并且具有最高 __array_priority__ 的输入参数。ndarray 的默认 __array_priority__ 是 0.0,子类型的默认 __array_priority__ 也是 0.0,而矩阵的 __array_priority__ 值为 10.0。
所有 ufunc 也可以接受输出参数,这些参数必须是数组或子类。如果需要,结果将被转换为提供的输出数组的数据类型。如果输出参数定义了 __array_wrap__ 方法,则会调用该方法而不是输入参数中的方法。
广播机制
另请参阅:广播基础
每个通用函数(ufunc)通过逐元素执行核心操作来处理数组输入并生成数组输出(这里的"元素"通常指标量,但对于广义ufunc也可以是向量或更高维的子数组)。系统会应用标准的广播规则,使得形状不完全相同的输入数组仍能进行有效运算。
根据广播规则,如果输入数组在某个维度上的尺寸为1,则该维度的第一个数据条目会沿该维度被复用于所有计算。换句话说,ufunc的遍历机制将直接跳过该维度(该维度的步长会被设为0)。
类型转换规则
注意:在 NumPy 1.6.0 版本中,引入了一个类型提升 API 来封装确定输出类型的机制。详情请参阅以下函数:
numpy.result_type、numpy.promote_types 和 numpy.min_scalar_type。
每个通用函数(ufunc)的核心是一个一维跨步循环,该循环为特定类型组合实现实际功能。创建 ufunc 时,会为其指定一个静态的内部循环列表以及对应的类型签名列表,ufunc 机制使用此列表来确定在特定情况下使用哪个内部循环。可以通过检查特定 ufunc 的 .types 属性来查看哪些类型组合定义了内部循环以及它们生成的输出类型(输出中使用了字符代码以简洁表示)。
当提供的输入类型没有核心循环实现时,必须对一个或多个输入进行类型转换。如果找不到输入类型的实现,算法会搜索一个类型签名,所有输入都可以“安全”地转换到该签名。在内部循环列表中找到的第一个符合条件的实现会被选中,并在完成所有必要的类型转换后执行。需要注意的是,ufunc 过程中的内部拷贝(即使是用于类型转换)也受限于内部缓冲区的大小(该大小可由用户设置)。
注意:NumPy 中的通用函数非常灵活,可以支持混合类型签名。例如,可以定义一个同时处理浮点数和整数值的通用函数。示例可参考 numpy.ldexp。
根据上述描述,类型转换规则本质上是通过“何时可以将一种数据类型‘安全’地转换为另一种数据类型”这一问题来实现的。在 Python 中,可以通过调用函数 can_cast(fromtype, totype) 来确定这一问题的答案。下面的示例展示了在作者的 64 位系统上,对 24 种内部支持类型调用此函数的结果。您可以通过示例中提供的代码为您的系统生成此表。
示例:
显示 64 位系统“安全转换”表的代码段。通常,输出取决于系统;您的系统可能会生成不同的表。
>>> mark = {False: ' -', True: ' Y'}
>>> def print_table(ntypes):
... print('X ' + ' '.join(ntypes))
... for row in ntypes:
... print(row, end='')
... for col in ntypes:
... print(mark[np.can_cast(row, col)], end='')
... print()
...
>>> print_table(np.typecodes['All'])
X ? b h i l q n p B H I L Q N P e f d g F D G S U V O M m
? Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y - Y
b - Y Y Y Y Y Y Y - - - - - - - Y Y Y Y Y Y Y Y Y Y Y - Y
h - - Y Y Y Y Y Y - - - - - - - - Y Y Y Y Y Y Y Y Y Y - Y
i - - - Y Y Y Y Y - - - - - - - - - Y Y - Y Y Y Y Y Y - Y
l - - - - Y Y Y Y - - - - - - - - - Y Y - Y Y Y Y Y Y - Y
q - - - - Y Y Y Y - - - - - - - - - Y Y - Y Y Y Y Y Y - Y
n - - - - Y Y Y Y - - - - - - - - - Y Y - Y Y Y Y Y Y - Y
p - - - - Y Y Y Y - - - - - - - - - Y Y - Y Y Y Y Y Y - Y
B - - Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y Y - Y
H - - - Y Y Y Y Y - Y Y Y Y Y Y - Y Y Y Y Y Y Y Y Y Y - Y
I - - - - Y Y Y Y - - Y Y Y Y Y - - Y Y - Y Y Y Y Y Y - Y
L - - - - - - - - - - - Y Y Y Y - - Y Y - Y Y Y Y Y Y - -
Q - - - - - - - - - - - Y Y Y Y - - Y Y - Y Y Y Y Y Y - -
N - - - - - - - - - - - Y Y Y Y - - Y Y - Y Y Y Y Y Y - -
P - - - - - - - - - - - Y Y Y Y - - Y Y - Y Y Y Y Y Y - -
e - - - - - - - - - - - - - - - Y Y Y Y Y Y Y Y Y Y Y - -
f - - - - - - - - - - - - - - - - Y Y Y Y Y Y Y Y Y Y - -
d - - - - - - - - - - - - - - - - - Y Y - Y Y Y Y Y Y - -
g - - - - - - - - - - - - - - - - - - Y - - Y Y Y Y Y - -
F - - - - - - - - - - - - - - - - - - - Y Y Y Y Y Y Y - -
D - - - - - - - - - - - - - - - - - - - - Y Y Y Y Y Y - -
G - - - - - - - - - - - - - - - - - - - - - Y Y Y Y Y - -
S - - - - - - - - - - - - - - - - - - - - - - Y Y Y Y - -
U - - - - - - - - - - - - - - - - - - - - - - - Y Y Y - -
V - - - - - - - - - - - - - - - - - - - - - - - - Y Y - -
O - - - - - - - - - - - - - - - - - - - - - - - - - Y - -
M - - - - - - - - - - - - - - - - - - - - - - - - Y Y Y -
m - - - - - - - - - - - - - - - - - - - - - - - - Y Y - Y
需要注意的是,虽然为了完整性在表格中包含了’S’、'U’和’V’类型,但这些类型无法被ufuncs操作。此外,在32位系统上,整数类型可能有不同的大小,这会导致表格内容略有变化。
混合标量-数组运算使用另一套类型转换规则,确保除非标量属于与数组完全不同类型的数据(即在数据类型层次结构中处于不同层级),否则标量不会"向上转型"数组。这一规则使您可以在代码中使用标量常量(作为Python类型,它们会在ufuncs中被相应解释),而无需担心标量常量的精度会导致大型(低精度)数组发生向上转型。
内部缓冲区的使用
在内部,缓冲区用于处理未对齐数据、交换数据以及需要从一种数据类型转换为另一种数据类型的情况。内部缓冲区的大小可按线程进行设置。最多可以创建 2 ( n i n p u t s + n o u t p u t s ) 2 (n_{inputs} + n_{outputs}) 2(ninputs+noutputs) 个指定大小的缓冲区,用于处理通用函数(ufunc)所有输入和输出的数据。缓冲区的默认大小为10,000个元素。
当需要进行基于缓冲区的计算,但所有输入数组都小于缓冲区大小时,那些行为异常或类型错误的数组会在计算开始前被复制。因此,调整缓冲区大小可能会影响各类通用函数计算完成的速度。
通过函数 numpy.setbufsize 可以简单地设置这个变量。
错误处理
通用函数可能会触发硬件中的特殊浮点状态寄存器(例如除零错误)。如果您的平台支持此功能,在计算过程中会定期检查这些寄存器。错误处理以线程为单位进行控制,可通过 numpy.seterr 和 numpy.seterrcall 函数进行配置。
重写 ufunc 行为
类(包括 ndarray 子类)可以通过定义特定的特殊方法来重写 ufunc 对它们的操作方式。详情请参阅标准数组子类。
2025-05-10(六)



















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











