







 本文是Spark修炼之道的进阶篇,详细介绍了Spark RDD的两种重要操作:repartitionAndSortWithinPartitions与aggregateByKey。repartitionAndSortWithinPartitions在分区和排序方面提供了更高的性能;而aggregateByKey则用于聚合相同Key的值,通过seqOp和combOp函数实现。文章还列举了这两个操作的使用示例,并探讨了aggregateByKey在不同Spark版本中的行为差异。此外,文中还提及了RDD的一些常用action操作,如reduce、count、first、take等。
本文是Spark修炼之道的进阶篇,详细介绍了Spark RDD的两种重要操作:repartitionAndSortWithinPartitions与aggregateByKey。repartitionAndSortWithinPartitions在分区和排序方面提供了更高的性能;而aggregateByKey则用于聚合相同Key的值,通过seqOp和combOp函数实现。文章还列举了这两个操作的使用示例,并探讨了aggregateByKey在不同Spark版本中的行为差异。此外,文中还提及了RDD的一些常用action操作,如reduce、count、first、take等。
作者:周志湖
网名:摇摆少年梦
微信号:zhouzhihubeyond
本节主要内容
- RDD transformation(续)
- RDD actions
1. RDD transformation(续)
(1)repartitionAndSortWithinPartitions(partitioner)
repartitionAndSortWithinPartitions函数是repartition函数的变种,与repartition函数不同的是,repartitionAndSortWithinPartitions在给定的partitioner内部进行排序,性能比repartition要高。
函数定义:
/**
* Repartition the RDD according to the given partitioner and, within each resulting partition,
* sort records by their keys.
*
* This is more efficient than calling repartition and then sorting within each partition
* because it can push the sorting down into the shuffle machinery.
*/
def repartitionAndSortWithinPartitions(partitioner: Partitioner): RDD[(K, V)]
使用示例:
scala> val data = sc.parallelize(List((1,3),(1,2),(5,4),(1, 4),(2,3),(2,4)),3)
data: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[3] at parallelize at <console>:21
scala> data.repartitionAndSortWithinPartitions(new HashPartitioner(3)).collect
res3: Array[(Int, Int)] = Array((1,4), (1,3), (1,2), (2,3), (2,4), (5,4))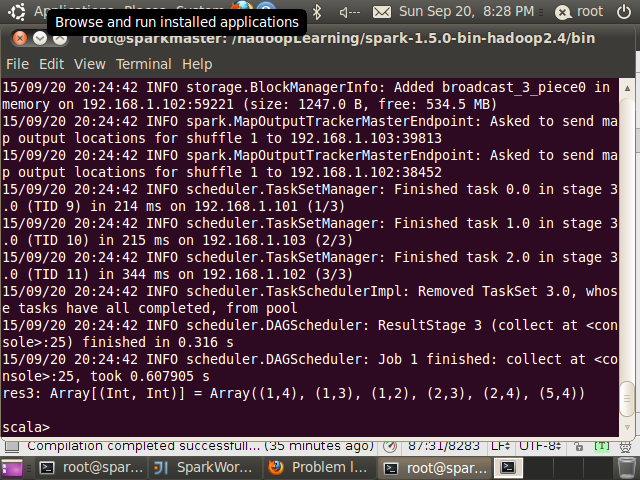
(2)aggregateByKey(zeroValue)(seqOp, combOp, [numTasks])
aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。其函数定义如下:
/**
* Aggregate the values of each key, using given combine functions and a neutral “zero value”.
* This function can return a different result type, U, than the type of the values in this RDD,
* V. Thus, we need one operation for merging a V into a U and one operation for merging two U’s,
* as in scala.TraversableOnce. The former operation is used for merging values within a
* partition, and the latter is used for merging values between partitions. To avoid memory
* allocation, both of these functions are allowed to modify and return their first argument
* instead of creating a new U.
*/
def aggregateByKey[U: ClassTag](zeroValue: U)(seqOp: (U, V) => U,
combOp: (U, U) => U): RDD[(K, U)]
示例代码:
import org.apache.spark.SparkContext._
import org.apache.spa 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 257
257

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









