









Stage划分
在上一节中我们讲了 Spark Job的提交,在该讲中我们提到,当rdd触发action操作之后,会调用SparkContext的runJob方法,最后调用的DAGScheduler.handleJobSubmitted方法完成整个job的提交。然后DAGScheduler根据RDD的lineage进行Stage划分,再生成TaskSet,由TaskScheduler向集群申请资源,最终在Woker节点的Executor进程中执行Task。
今天我们先来看一下如何进行Stage划分。下图给出的是对应Spark应用程序代码生成的Stage。它的具体划分依据是根据RDD的依赖关系进行,在遇到宽依赖时将两个RDD划分为不同的Stage。
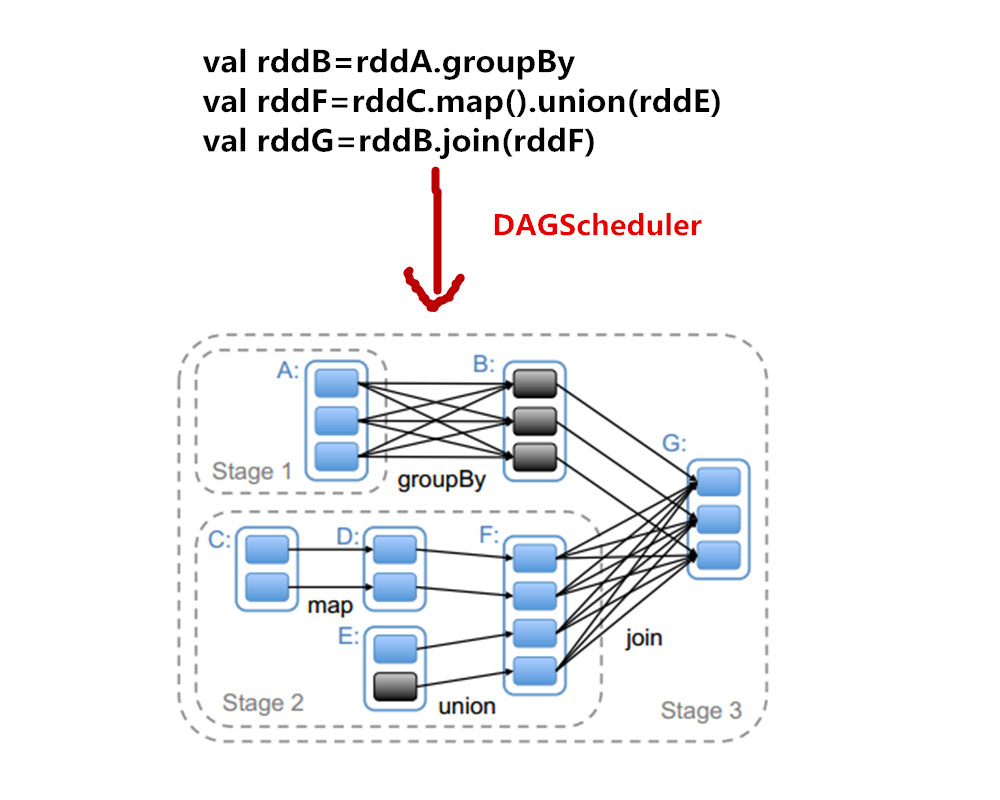
从上图中可以看到,RDD G与RDD F间的依赖是宽依赖,所以RDD F与 RDD G被划分为不同的Stage,而RDD G 与 RDD 间为窄依赖,因此 RDD B 与 RDD G被划分为同一个Stage。通过这种递归的调用方式,将所有RDD进行划分。
//DAGScheduler.handleJobSubmitted方法
//参数finalRDD为触发action操作时最后一个RDD
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
//finalStage表示最后一个Stage
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
//调用newResultStage创建Final Stage
finalStage = newResultStage(finalRDD, partitions.length, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
//如果存在finalStage
if (finalStage != null) {
val job = new ActiveJob(jobId, finalStage, func, partitions, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + "(" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.resultOfJob = Some(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
//向LiveListenerBus post SparkListenerJobStart
//listenerThread后台线程处理该事件
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
//提交finalStage,该方法会提交所有关联的未提交的stage
submitStage(finalStage)
}
//检查是否有等待或失败的Stage需要重新提交
submitWaitingStages()
}这里重点关注newResultStage方法,具体代码如下
/**
* Create a ResultStage associated with the provided jobId.
*/
private def newResultStage(
rdd: RDD[_],
numTasks: Int,
jobId: Int,
callSite: CallSite): ResultStage = {
//获取Parent Stages及ID
val (parentStages: List[Stage], id: Int) = getParentStagesAndId(rdd, jobId)
//创建ResultStage
val stage: ResultStage = new ResultStage(id, rdd, numTasks, parentStages, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}跳到getParentStagesAndId方法中可以看到如下代码:
/**
* Helper function to eliminate some code re-use when creating new stages.
*/
private def getParentStagesAndId(rdd: RDD[_], firstJobId: Int): (List[Stage], Int) = {
//根据宽依赖中的ShuffleDependency生成ParentStage
val parentStages = getParentStages(rdd, firstJobId)
//生成StageID
val id = nextStageId.getAndIncrement()
(parentStages, id)
}跳到getParentStages方法中,可以看到下面的代码:
/**
* Get or create the list of parent stages for a given RDD. The new Stages will be created with
* the provided firstJobId.
*/
private def getParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
val parents = new HashSet[Stage]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new Stack[RDD[_]]
//广度优先遍历方式
def visit(r: RDD[_]) {
if (!visited(r)) {
visited += r
// Kind of ugly: need to register RDDs with the cache here since
// we can't do it in its constructor because # of partitions is unknown
for (dep <- r.dependencies) {
dep match {
//如何是ShuffleDependency,则生成一个新的stage
case shufDep: ShuffleDependency[_, _, _] =>
parents += getShuffleMapStage(shufDep, firstJobId)
case _ =>
waitingForVisit.push(dep.rdd)
}
}
}
}
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())
}
parents.toList
}再跳到getShuffleMapStage方法,可以看到如下代码:
/**
* Get or create a shuffle map stage for the given shuffle dependency's map side.
*/
private def getShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleToMapStage.get(shuffleDep.shuffleId) match {
//如何存在,则不需要创建,原样返回
case Some(stage) => stage
//如果不存在,则创建
case None =>
// We are going to register ancestor shuffle dependencies
//查看其依赖的父类Stage是否存在,没有的话创建
registerShuffleDependencies(shuffleDep, firstJobId)
// Then register current shuffleDep
//创建当前shuffleDep RDD的Stage
val stage = newOrUsedShuffleStage(shuffleDep, firstJobId)
shuffleToMapStage(shuffleDep.shuffleId) = stage
stage
}
}Stage整体划分的逻辑讲清楚了,在下一节中我们将介绍submitStage及submitWaitingStages方法进行Stage的提交。















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









