







 本文深入探讨Spark 1.5.0的SparkContext创建过程,阐述其在应用程序中的核心角色,如与集群交互、申请资源、创建RDD等。文章介绍了Spark应用程序的执行流程,强调Executor的持久性和多线程执行Task的特性,以及Spark对不同集群管理器的适应性。此外,还提到了Driver端的任务调度重要性,并列举了Spark支持的集群管理器类型和Master URL。接下来的内容将逐步解析SparkContext创建的相关源码。
本文深入探讨Spark 1.5.0的SparkContext创建过程,阐述其在应用程序中的核心角色,如与集群交互、申请资源、创建RDD等。文章介绍了Spark应用程序的执行流程,强调Executor的持久性和多线程执行Task的特性,以及Spark对不同集群管理器的适应性。此外,还提到了Driver端的任务调度重要性,并列举了Spark支持的集群管理器类型和Master URL。接下来的内容将逐步解析SparkContext创建的相关源码。
博文推荐:http://blog.csdn.net/anzhsoft/article/details/39268963,由大神张安站写的Spark架构原理,使用Spark版本为1.2,本文以Spark 1.5.0为蓝本,介绍Spark应用程序的执行流程。
本文及后面的源码分析都以下列代码为样板
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount{
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: SparkWordCount <inputfile> <outputfile>")
System.exit(1)
}
val conf = new SparkConf().setAppName("SparkWordCount")
val sc = new SparkContext(conf)
val file=sc.textFile("file:///hadoopLearning/spark-1.5.1-bin-hadoop2.4/README.md")
val counts=file.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.reduceByKey(_+_)
counts.saveAsTextFile("file:///hadoopLearning/spark-1.5.1-bin-hadoop2.4/countReslut.txt")
}
}代码中的SparkContext在Spark应用程序的执行过程中起着主导作用,它负责与程序个Spark集群进行交互,包括申请集群资源、创建RDD、accumulators 及广播变量等。SparkContext与集群资源管理器、Worker结节点交互图如下图所示。
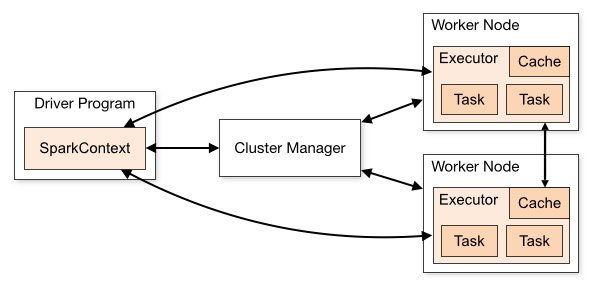
官网对图下面几点说明:
(1)不同的Spark应用程序对应该不同的Executor,这些Executor在整个应用程序执行期间都存在并且Executor中可以采用多线程的方式执行Task。这样做的好处是,各个Spark应用程序的执行是相互隔离的。除Spark应用程序向外部存储系统写数据进行数据交互这种方式外,各Spark应用程序间无法进行数据共享。
(2)Spark对于其使用的集群资源管理器没有感知能力,只要它能对Executor进行申请并通信即可。这意味着不管使用哪种资源管理器,其执行流程都是不变的。这样Spark可以不同的资源管理器进行交互。
(3)Spark应用程序在整个执行过程中要与Executors进行来回通信。
(4)Driver端负责Spark应用程序任务的调度,因此最好Driver应该靠近Worker节点。
Spark目前支持的集群管理器包括:
Standalone
Apache Mesos
Hadoop YARN
在提交Spark应用程序时,Spark支持下列几种Master URL

有了前面的知识铺垫后,现在我们来说明一下Spark的创建过程,SparkContext创建部分核心源码如下:
// We need to register "HeartbeatReceiver" before "createTaskScheduler" because Executor will
// retrieve "HeartbeatReceiver" in the constructor. (SPARK-6640)
_heartbeatReceiver = env.rpcEnv.setupEndpoint(
HeartbeatReceiver.ENDPOINT_NAME, new HeartbeatReceiver(this))
// Create and start the scheduler
//根据master及SparkContext对象创建TaskScheduler,返回SchedulerBackend及TaskScheduler
val (sched, ts) = SparkContext.createTaskScheduler(this, master)
_schedulerBackend = sched
_taskScheduler = ts
//根据SparkContext对象创建DAGScheduler
_dagScheduler = new DAGScheduler(this)
_heartbeatReceiver.ask[Boolean](TaskSchedulerIsSet)
// start TaskSched 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4256
4256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









