







1、特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,特征工程就是最大限度地从原始数据中提取特征以供算法和模型使用,通过归纳和总结,特征工程大体包含以下方面:
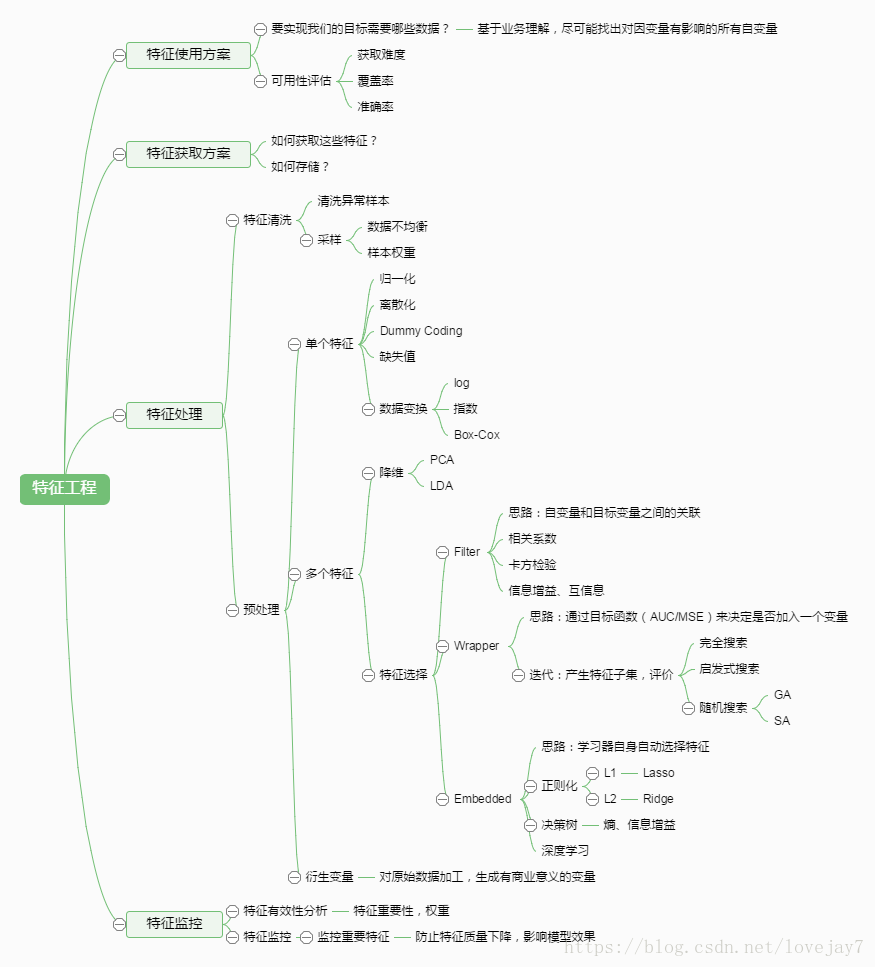
特征处理是特征工程的核心部分,scikit-learn提供了较为完整的特征处理方法,包括数据预处理、特征选择、降维等。
2、数据预处理
通过特征提取,我们能得到未处理的特征,这是的特征有以下显著特点:
不属于同一量纲:特征无法进行比较。
信息冗余。
定性特征不能直接使用。
存在缺失值。
信息利用率低。
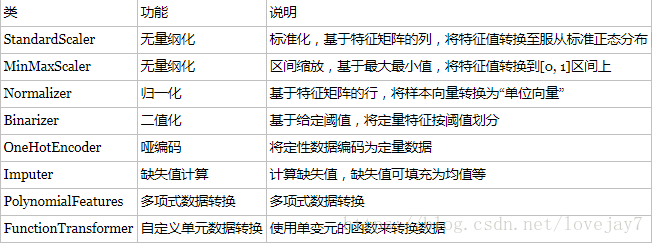
无量纲化
无量纲化使用不同规格的数据转换到统一规格。常见的无量纲化方法有标准化和区间缩放法。标准化的前提是特征值服从正态分布,标准化后,转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围。
3、特征选择
当数据与处理完成后,我们需要选择有意义的特征输入算法和模型进行训练,通常来说,从两个方面来选择特征:
1、特征是否发散:若一个特征不发散,例如方差接近0,说明样本在这个特征上基本没有差异,这个特征对于样本的区分没有什么用。
2、特征与目标的相关性:与目标相关性高的特征,应当优先选择。
根据特征选择的形式又可将特征选择方法分为三种:
Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
一般使用scikit-learn中的feature_selection库来进行特征选择。
3.1 Filter
3.1.1 方差选择法
3.1.2 相关系数法
3.1.3 卡方检验
3.1.4 互信息法
3.2 Wrapper
3.2.1 递归特征消除法
3.3 Embedded
3.3.1 基于惩罚项的特征选择法
3.3.2 基于树模型的特征选择法
4、降维
当特征选择完成后,可以直接训练模型,但是可能由于特征矩阵过大,导致计算量大,训练时间过长,因此数据降维很有必要。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。















 2897
2897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









