







前言
本文主要讲了ES在节点部署时可以考虑的节点职责划分,如果不考虑节点部署,那么所有节点都会身兼数职(master-eligible ,data,coordinate等),这对后期的维护拓展并不利,所以本文从节点介绍出发,再到实践Hot Warm 架构,让大家有个es集群分职责部署有个直观印象。然后仍要着重强调,本文只是一个引子,只是告诉你ES有这个东西,当看完本文,以后的所有问题都应该直接去看 Elasticsearc-Nodes 官方文档介绍,ES完善的文档内容已经能够解决大部分问题,下方很多节点介绍也直接是文档原文整理了一下,都没有翻译,一开始本来想翻译的,后面想想完全没有必要,程序猿看英文文档不是很正常吗,哈哈。
一个节点只承担一个角色(Elasticsearch 8.14.3)
节点职责
You define a node’s roles by setting node.roles in elasticsearch.yml. If you set node.roles, the node is only assigned the roles you specify. If you don’t set node.roles, the node is assigned the following roles:
masterdatadata_contentdata_hotdata_warmdata_colddata_frozeningestmlremote_cluster_clienttransform
If you set node.roles, ensure you specify every node role your cluster needs. Every cluster requires the following node roles:
master- (
data_contentanddata_hot) ORdata
Master-eligible node
The master node is responsible for lightweight cluster-wide actions,It is important for cluster health to have a stable master node
- creating or deleting an index
- tracking which nodes are part of the cluster
- deciding which shards to allocate to which nodes
To create a dedicated master-eligible node, set:
node.roles: [ master ]
Coordinating Node
Requests like search requests or bulk-indexing requests may involve data held on different data nodes. A search request, for example, is executed in two phases which are coordinated by the node which receives the client request — the coordinating node.
- In the scatter phase, the coordinating node forwards the request to the data nodes which hold the data. Each data node executes the request locally and returns its results to the coordinating node.
- In the gather phase, the coordinating node reduces each data node’s results into a single global result set.
Every node is implicitly a coordinating node. This means that a node that has an explicit empty list of roles via node.roles will only act as a coordinating node, which cannot be disabled. As a result, such a node needs to have enough memory and CPU in order to deal with the gather phase.
To create a dedicated coordinating node, set:
node.roles: [ ]
Data Node
Data nodes hold the shards that contain the documents you have indexed. Data nodes handle data related operations like CRUD, search, and aggregations. These operations are I/O-, memory-, and CPU-intensive. It is important to monitor these resources and to add more data nodes if they are overloaded.
In a multi-tier deployment architecture, you use specialized data roles to assign data nodes to specific tiers: data_content,data_hot, data_warm, data_cold, or data_frozen. A node can belong to multiple tiers.
If you want to include a node in all tiers, or if your cluster does not use multiple tiers, then you can use the generic data role.
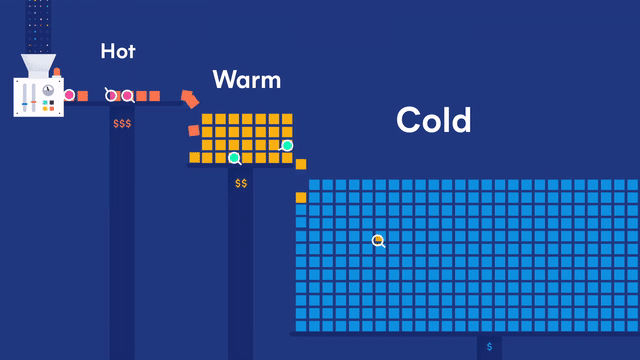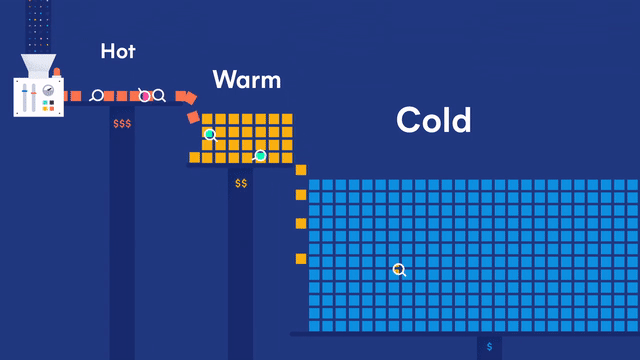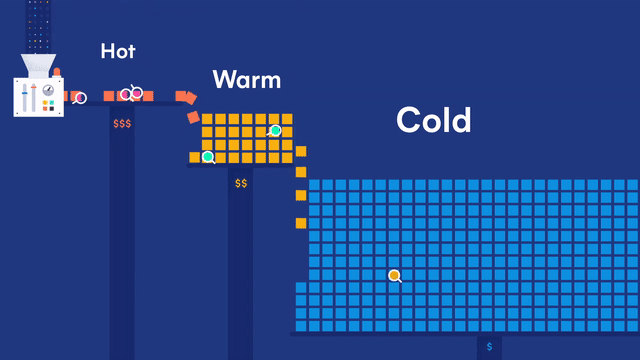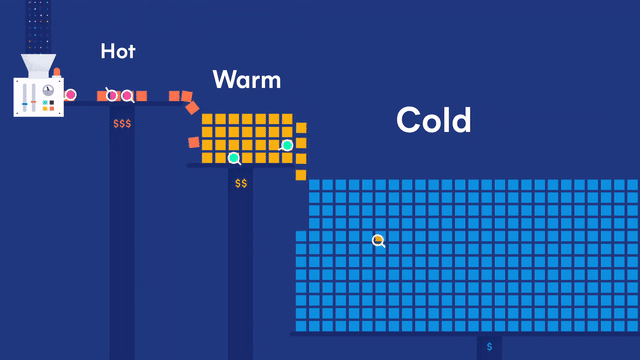
Generic data node
Generic data nodes are included in all content tiers.
To create a dedicated generic data node, set:
node.roles: [ data ]
Content data node
Content data nodes are part of the content tier. Data stored in the content tier is generally a collection of items such as a product catalog or article archive. Content data typically has long data retention requirements, and you want to be able to retrieve items quickly regardless of how old they are. Content tier nodes are usually optimized for query performance—they prioritize processing power over IO throughput so they can process complex searches and aggregations and return results quickly.
The content tier is required and is often deployed within the same node grouping as the hot tier. System indices and other indices that aren’t part of a data stream are automatically allocated to the content tier.
To create a dedicated content node, set:
node.roles: ["data_content"]
Hot data node
Hot data nodes are part of the hot tier. The hot tier is the Elasticsearch entry point for time series data and holds your most-recent, most-frequently-searched time series data. Nodes in the hot tier need to be fast for both reads and writes, which requires more hardware resources and faster storage (SSDs). For resiliency, indices in the hot tier should be configured to use one or more replicas.
The hot tier is required. New indices that are part of a data stream are automatically allocated to the hot tier.
To create a dedicated hot node, set:
node.roles: [ "data_hot" ]
Warm data node
Warm data nodes are part of the warm tier. Time series data can move to the warm tier once it is being queried less frequently than the recently-indexed data in the hot tier. The warm tier typically holds data from recent weeks. Updates are still allowed, but likely infrequent. Nodes in the warm tier generally don’t need to be as fast as those in the hot tier. For resiliency, indices in the warm tier should be configured to use one or more replicas.
To create a dedicated warm node, set:
node.roles: [ "data_warm" ]
Cold data node
Cold data nodes are part of the cold tier. When you no longer need to search time series data regularly, it can move from the warm tier to the cold tier. While still searchable, this tier is typically optimized for lower storage costs rather than search speed.
For better storage savings, you can keep fully mounted indices of searchable snapshots on the cold tier. Unlike regular indices, these fully mounted indices don’t require replicas for reliability. In the event of a failure, they can recover data from the underlying snapshot instead. This potentially halves the local storage needed for the data. A snapshot repository is required to use fully mounted indices in the cold tier. Fully mounted indices are read-only.
Alternatively, you can use the cold tier to store regular indices with replicas instead of using searchable snapshots. This lets you store older data on less expensive hardware but doesn’t reduce required disk space compared to the warm tier.
To create a dedicated cold node, set:
node.roles: [ "data_cold" ]
Frozen data node
Frozen data nodes are part of the frozen tier. Once data is no longer being queried, or being queried rarely, it may move from the cold tier to the frozen tier where it stays for the rest of its life.
The frozen tier requires a snapshot repository. The frozen tier uses partially mounted indices to store and load data from a snapshot repository. This reduces local storage and operating costs while still letting you search frozen data. Because Elasticsearch must sometimes fetch frozen data from the snapshot repository, searches on the frozen tier are typically slower than on the cold tier.
To create a dedicated frozen node, set:
node.roles: [ "data_frozen" ]
WARNING: Adding too many coordinating only nodes to a cluster can increase the burden on the entire cluster because the elected master node must await acknowledgement of cluster state updates from every node! The benefit of coordinating only nodes should not be overstated — data nodes can happily serve the same purpose.
Ingest Node
数据前置处理转换节点,支持pipeline管道设置,可以使用ingest对数据进行过滤、转换等操作
Hot Warm 架构实践
部署3个master-eligible节点, 2个coordinate only node,2个data-content(充当warm节点),3个data-hot。这些基本算是如果要做节点职责划分的最小配置。

- 单一 master eligible nodes: 负责集群状态(cluster state)的管理
- 使用低配置的CPU,RAM和磁盘
- 单一 data nodes: 负责数据存储及处理客户端请求
- 使用高配置的CPU,RAM和磁盘
- 单一ingest nodes: 负责数据处理
- 使用高配置CPU; 中等配置的RAM; 低配置的磁盘
- 单一Coordinating Only Nodes(Client Node)
- 使用高配置CPU; 高配置的RAM; 低配置的磁盘
Docker安装脚本
create index template
add a data

Set a tier preference for existing indices (move index to other data node)
你可以使用ilm机制去自动迁移index,这里只是演示http请求手动迁移books索引从data_hot节点到data_content节点。


















 3313
3313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









