







基于飞浆paddle训练框架
照这个改的
https://www.paddlepaddle.org.cn/documentation/docs/zh/practices/cv/image_ocr.html
训练不到10分钟
10epoch
cpu:inter i5 8250 U
脚本生成的图10000
验证训练:3:7
预测结果
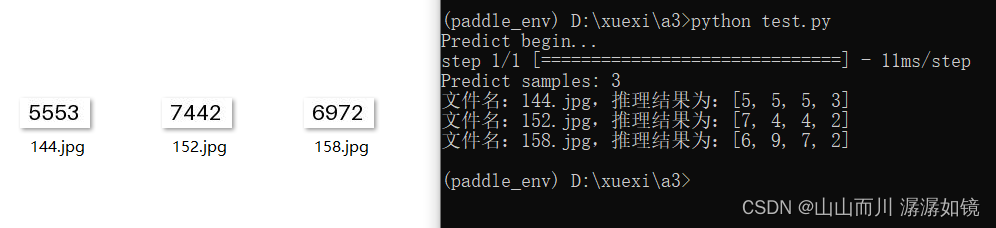
chatgpt写的代码,生成数字根据label.txt,数据集就是编的,截图测试的效果不理想,太局限了,1111和2222就是手动截取的图认不出来,干到现在脑子想不动了,写个笔记,很潦草。

from PIL import Image, ImageDraw, ImageFont
import os
import ast # 导入 ast 模块以进行 literal_eval
# 文件路径
file_path = 'D:\\xuexi\\a3\\data\\ocr\\a.txt'
# 输出目录
output_dir = 'D:\\xuexi\\a3\\data\\ocr\\images'
os.makedirs(output_dir, exist_ok=True)
# 使用默认字体
# 或者使用默认字体并设置大小
font_size = 22
font = ImageFont.load_default()
font = font.font_variant(size=font_size)
# 读取文件并解析内容
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 使用 ast.literal_eval 安全地将行解析为字典
data = ast.literal_eval(line.strip())
for filename, content in data.items():
# 动态调整图像大小以适应文本
text_width=70
text_height = 30
# 使用动态大小初始化 Image 对象
image = Image.new('RGB', (text_width , text_height ), color=(255, 255, 255))
d = ImageDraw.Draw(image)
# 计算将文本居中的位置
position = ((image.width - text_width) // 2+8, (image.height - text_height) // 2)
# 绘制文本
d.text(position, content, fill=(0, 0, 0), font=font)
# 构建完整的输出路径并保存图像
image_path = os.path.join(output_dir, filename.strip('"'))
image.save(image_path)
print("图像已生成。")
开始摸鱼,乌呼!


















 1871
1871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









